 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAGZO: Activation-Guided Zeroth-Order Optimization for LLM Fine-Tuning
Jan 24, 2026Zeroth-Order (ZO) optimization has emerged as a promising solution for fine-tuning LLMs under strict memory constraints, as it avoids the prohibitive memory cost of storing activations for backpropagation. However, existing ZO methods typically employ isotropic perturbations, neglecting the rich structural information available during the forward pass. In this paper, we identify a crucial link between gradient formation and activation structure: the gradient of a linear layer is confined to the subspace spanned by its input activations. Leveraging this insight, we propose Activation-Guided Zeroth-Order optimization (AGZO). Unlike prior methods, AGZO extracts a compact, activation-informed subspace on the fly during the forward pass and restricts perturbations to this low-rank subspace. We provide a theoretical framework showing that AGZO optimizes a subspace-smoothed objective and provably yields update directions with higher cosine similarity to the true gradient than isotropic baselines. Empirically, we evaluate AGZO on Qwen3 and Pangu models across various benchmarks. AGZO consistently outperforms state-of-the-art ZO baselines and significantly narrows the performance gap with first-order fine-tuning, while maintaining almost the same peak memory footprint as other ZO methods.
Toward Reproducing Network Research Results Using Large Language Models
Sep 09, 2023



Reproducing research results in the networking community is important for both academia and industry. The current best practice typically resorts to three approaches: (1) looking for publicly available prototypes; (2) contacting the authors to get a private prototype; and (3) manually implementing a prototype following the description of the publication. However, most published network research does not have public prototypes and private prototypes are hard to get. As such, most reproducing efforts are spent on manual implementation based on the publications, which is both time and labor consuming and error-prone. In this paper, we boldly propose reproducing network research results using the emerging large language models (LLMs). In particular, we first prove its feasibility with a small-scale experiment, in which four students with essential networking knowledge each reproduces a different networking system published in prominent conferences and journals by prompt engineering ChatGPT. We report the experiment's observations and lessons and discuss future open research questions of this proposal. This work raises no ethical issue.
Achieving Efficient Distributed Machine Learning Using a Novel Non-Linear Class of Aggregation Functions
Jan 29, 2022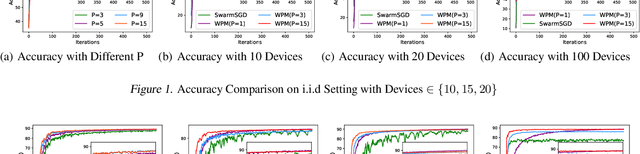
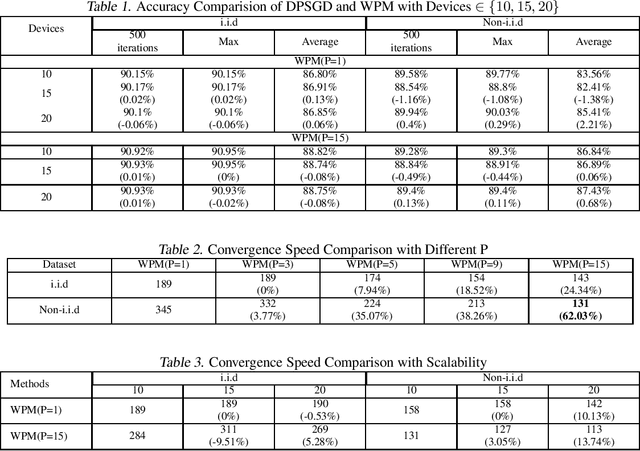


Distributed machine learning (DML) over time-varying networks can be an enabler for emerging decentralized ML applications such as autonomous driving and drone fleeting. However, the commonly used weighted arithmetic mean model aggregation function in existing DML systems can result in high model loss, low model accuracy, and slow convergence speed over time-varying networks. To address this issue, in this paper, we propose a novel non-linear class of model aggregation functions to achieve efficient DML over time-varying networks. Instead of taking a linear aggregation of neighboring models as most existing studies do, our mechanism uses a nonlinear aggregation, a weighted power-p mean (WPM) where p is a positive odd integer, as the aggregation function of local models from neighbors. The subsequent optimizing steps are taken using mirror descent defined by a Bregman divergence that maintains convergence to optimality. In this paper, we analyze properties of the WPM and rigorously prove convergence properties of our aggregation mechanism. Additionally, through extensive experiments, we show that when p > 1, our design significantly improves the convergence speed of the model and the scalability of DML under time-varying networks compared with arithmetic mean aggregation functions, with little additional 26computation overhead.
Vulcan: Solving the Steiner Tree Problem with Graph Neural Networks and Deep Reinforcement Learning
Nov 21, 2021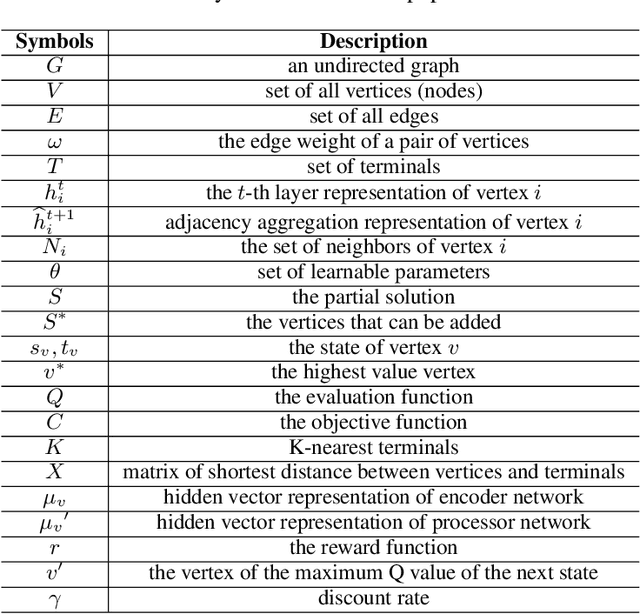

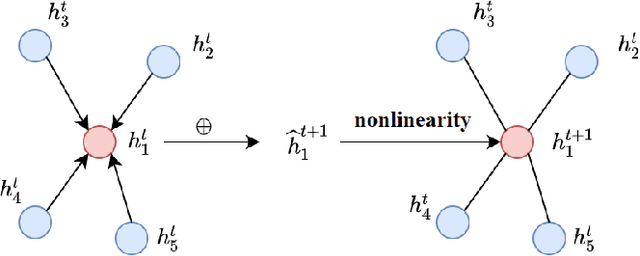

Steiner Tree Problem (STP) in graphs aims to find a tree of minimum weight in the graph that connects a given set of vertices. It is a classic NP-hard combinatorial optimization problem and has many real-world applications (e.g., VLSI chip design, transportation network planning and wireless sensor networks). Many exact and approximate algorithms have been developed for STP, but they suffer from high computational complexity and weak worst-case solution guarantees, respectively. Heuristic algorithms are also developed. However, each of them requires application domain knowledge to design and is only suitable for specific scenarios. Motivated by the recently reported observation that instances of the same NP-hard combinatorial problem may maintain the same or similar combinatorial structure but mainly differ in their data, we investigate the feasibility and benefits of applying machine learning techniques to solving STP. To this end, we design a novel model Vulcan based on novel graph neural networks and deep reinforcement learning. The core of Vulcan is a novel, compact graph embedding that transforms highdimensional graph structure data (i.e., path-changed information) into a low-dimensional vector representation. Given an STP instance, Vulcan uses this embedding to encode its pathrelated information and sends the encoded graph to a deep reinforcement learning component based on a double deep Q network (DDQN) to find solutions. In addition to STP, Vulcan can also find solutions to a wide range of NP-hard problems (e.g., SAT, MVC and X3C) by reducing them to STP. We implement a prototype of Vulcan and demonstrate its efficacy and efficiency with extensive experiments using real-world and synthetic datasets.
Toward Efficient Federated Learning in Multi-Channeled Mobile Edge Network with Layerd Gradient Compression
Sep 18, 2021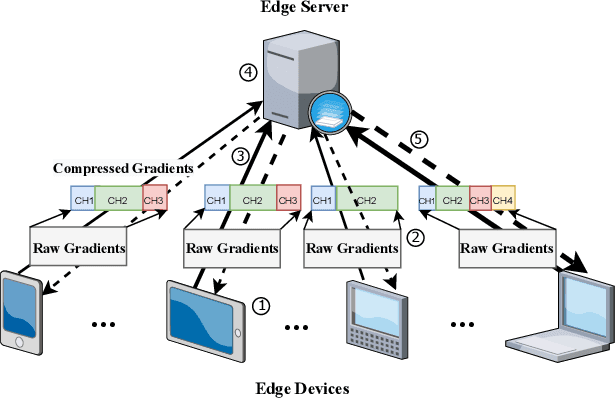

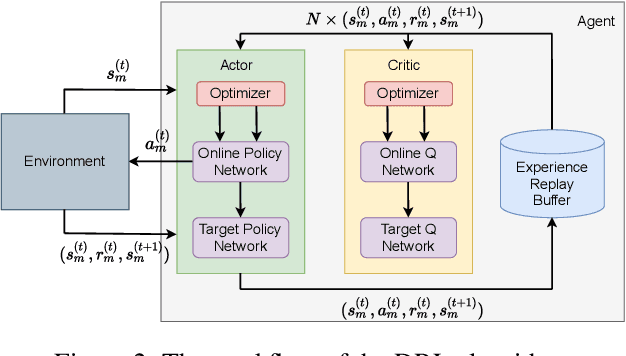
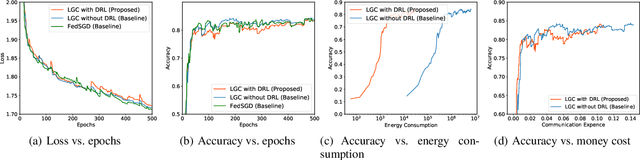
A fundamental issue for federated learning (FL) is how to achieve optimal model performance under highly dynamic communication environments. This issue can be alleviated by the fact that modern edge devices usually can connect to the edge FL server via multiple communication channels (e.g., 4G, LTE and 5G). However, having an edge device send copies of local models to the FL server along multiple channels is redundant, time-consuming, and would waste resources (e.g., bandwidth, battery life and monetary cost). In this paper, motivated by the layered coding techniques in video streaming, we propose a novel FL framework called layered gradient compression (LGC). Specifically, in LGC, local gradients from a device is coded into several layers and each layer is sent to the FL server along a different channel. The FL server aggregates the received layers of local gradients from devices to update the global model, and sends the result back to the devices. We prove the convergence of LGC, and formally define the problem of resource-efficient federated learning with LGC. We then propose a learning based algorithm for each device to dynamically adjust its local computation (i.e., the number of local stochastic descent) and communication decisions (i.e.,the compression level of different layers and the layer to channel mapping) in each iteration. Results from extensive experiments show that using our algorithm, LGC significantly reduces the training time, improves the resource utilization, while achieving a similar accuracy, compared with well-known FL mechanisms.