 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Momentum-based Paradigm of Decentralized SGD for Non-Convex Models and Heterogeneous Data
Paper and Code
Mar 01, 2023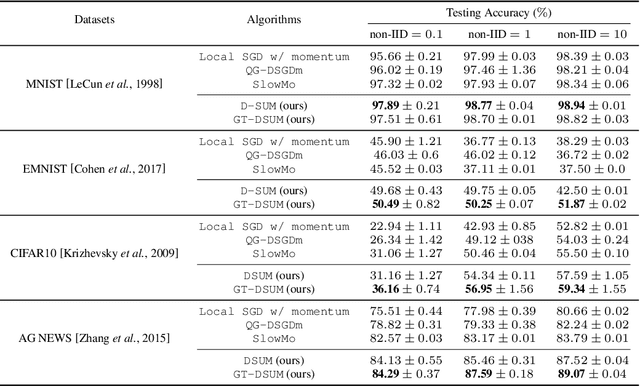
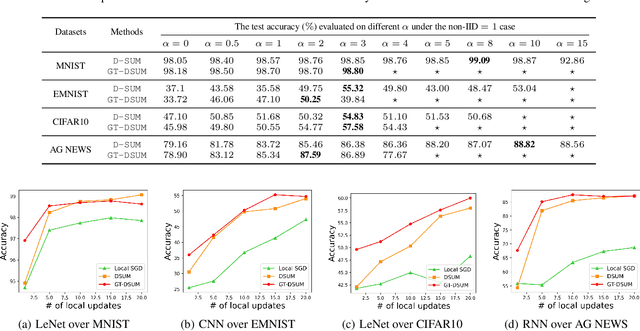
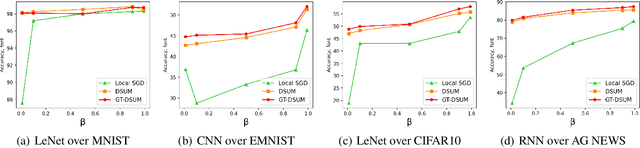
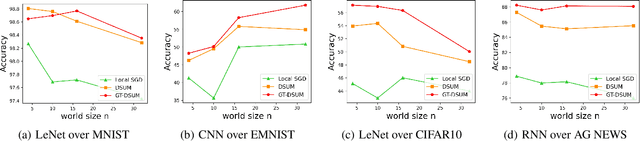
Emerging distributed applications recently boosted the development of decentralized machine learning, especially in IoT and edge computing fields. In real-world scenarios, the common problems of non-convexity and data heterogeneity result in inefficiency, performance degradation, and development stagnation. The bulk of studies concentrates on one of the issues mentioned above without having a more general framework that has been proven optimal. To this end, we propose a unified paradigm called UMP, which comprises two algorithms, D-SUM and GT-DSUM, based on the momentum technique with decentralized stochastic gradient descent(SGD). The former provides a convergence guarantee for general non-convex objectives. At the same time, the latter is extended by introducing gradient tracking, which estimates the global optimization direction to mitigate data heterogeneity(i.e., distribution drift). We can cover most momentum-based variants based on the classical heavy ball or Nesterov's acceleration with different parameters in UMP. In theory, we rigorously provide the convergence analysis of these two approaches for non-convex objectives and conduct extensive experiments, demonstrating a significant improvement in model accuracy by up to 57.6% compared to other methods in practice.