 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsynchronous Distributed Bayesian Optimization at HPC Scale
Paper and Code
Jul 04, 2022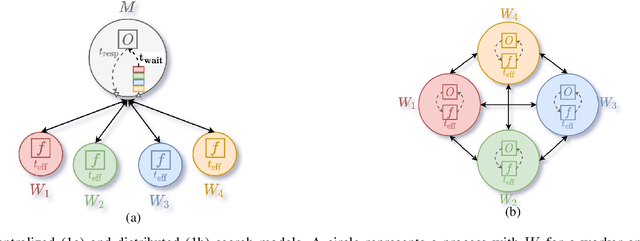
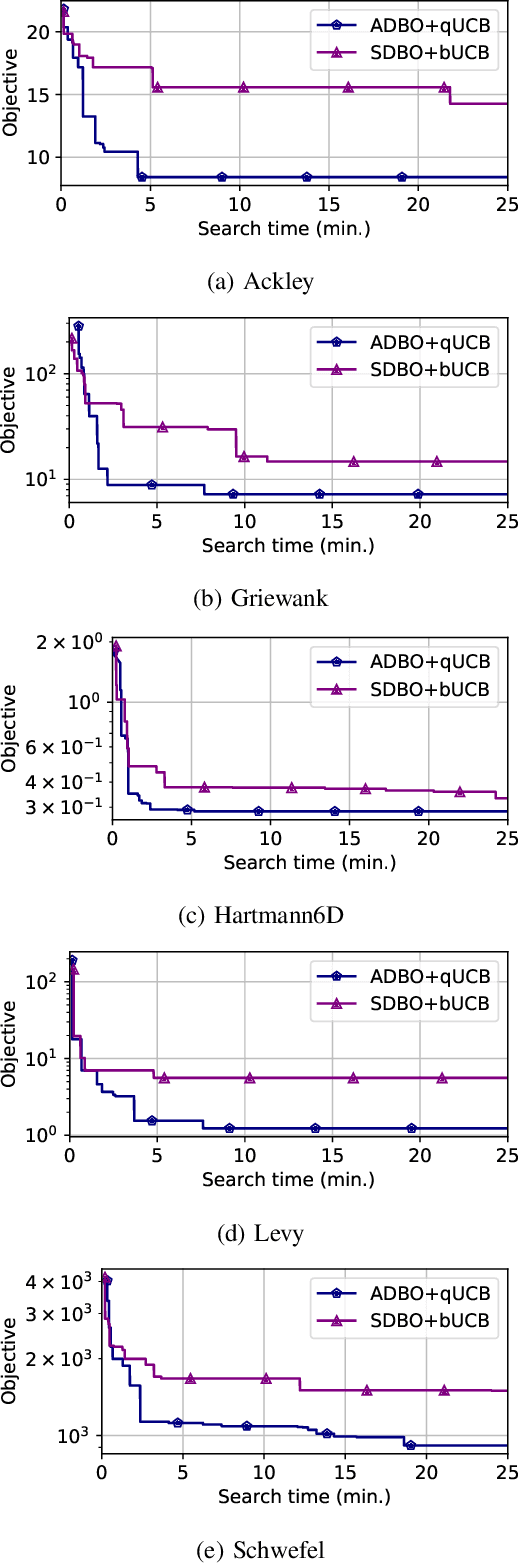
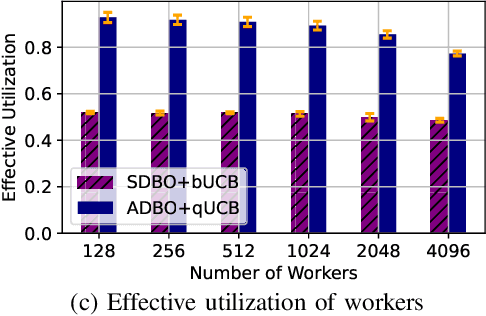
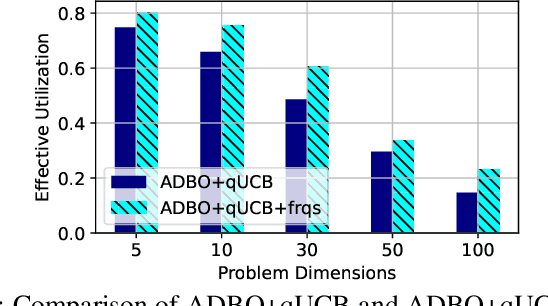
Bayesian optimization (BO) is a widely used approach for computationally expensive black-box optimization such as simulator calibration and hyperparameter optimization of deep learning methods. In BO, a dynamically updated computationally cheap surrogate model is employed to learn the input-output relationship of the black-box function; this surrogate model is used to explore and exploit the promising regions of the input space. Multipoint BO methods adopt a single manager/multiple workers strategy to achieve high-quality solutions in shorter time. However, the computational overhead in multipoint generation schemes is a major bottleneck in designing BO methods that can scale to thousands of workers. We present an asynchronous-distributed BO (ADBO) method wherein each worker runs a search and asynchronously communicates the input-output values of black-box evaluations from all other workers without the manager. We scale our method up to 4,096 workers and demonstrate improvement in the quality of the solution and faster convergence. We demonstrate the effectiveness of our approach for tuning the hyperparameters of neural networks from the Exascale computing project CANDLE benchmarks.