 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Energy Optimization in GPUs: A Multi-Armed Bandit Approach
Oct 03, 2024



Energy consumption has become a critical design metric and a limiting factor in the development of future computing architectures, from small wearable devices to large-scale leadership computing facilities. The predominant methods in energy management optimization are focused on CPUs. However, GPUs are increasingly significant and account for the majority of energy consumption in heterogeneous high performance computing (HPC) systems. Moreover, they typically rely on either purely offline training or a hybrid of offline and online training, which are impractical and lead to energy loss during data collection. Therefore, this paper studies a novel and practical online energy optimization problem for GPUs in HPC scenarios. The problem is challenging due to the inherent performance-energy trade-offs of GPUs, the exploration & exploitation dilemma across frequencies, and the lack of explicit performance counters in GPUs. To address these challenges, we formulate the online energy consumption optimization problem as a multi-armed bandit framework and develop a novel bandit based framework EnergyUCB. EnergyUCB is designed to dynamically adjust GPU core frequencies in real-time, reducing energy consumption with minimal impact on performance. Specifically, the proposed framework EnergyUCB (1) balances the performance-energy trade-off in the reward function, (2) effectively navigates the exploration & exploitation dilemma when adjusting GPU core frequencies online, and (3) leverages the ratio of GPU core utilization to uncore utilization as a real-time GPU performance metric. Experiments on a wide range of real-world HPC benchmarks demonstrate that EnergyUCB can achieve substantial energy savings. The code of EnergyUCB is available at https://github.com/XiongxiaoXu/EnergyUCB-Bandit.
Transfer-Learning-Based Autotuning Using Gaussian Copula
Jan 09, 2024
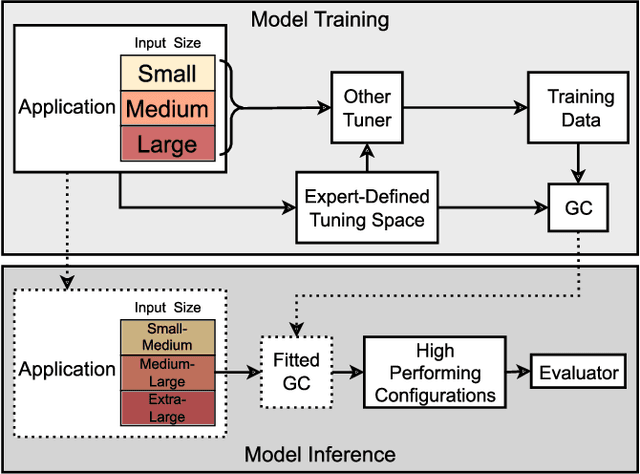


As diverse high-performance computing (HPC) systems are built, many opportunities arise for applications to solve larger problems than ever before. Given the significantly increased complexity of these HPC systems and application tuning, empirical performance tuning, such as autotuning, has emerged as a promising approach in recent years. Despite its effectiveness, autotuning is often a computationally expensive approach. Transfer learning (TL)-based autotuning seeks to address this issue by leveraging the data from prior tuning. Current TL methods for autotuning spend significant time modeling the relationship between parameter configurations and performance, which is ineffective for few-shot (that is, few empirical evaluations) tuning on new tasks. We introduce the first generative TL-based autotuning approach based on the Gaussian copula (GC) to model the high-performing regions of the search space from prior data and then generate high-performing configurations for new tasks. This allows a sampling-based approach that maximizes few-shot performance and provides the first probabilistic estimation of the few-shot budget for effective TL-based autotuning. We compare our generative TL approach with state-of-the-art autotuning techniques on several benchmarks. We find that the GC is capable of achieving 64.37% of peak few-shot performance in its first evaluation. Furthermore, the GC model can determine a few-shot transfer budget that yields up to 33.39$\times$ speedup, a dramatic improvement over the 20.58$\times$ speedup using prior techniques.
* 13 pages, 5 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2023, available at https://dl.acm.org/doi/10.1145/3577193.3593712
ytopt: Autotuning Scientific Applications for Energy Efficiency at Large Scales
Mar 28, 2023



As we enter the exascale computing era, efficiently utilizing power and optimizing the performance of scientific applications under power and energy constraints has become critical and challenging. We propose a low-overhead autotuning framework to autotune performance and energy for various hybrid MPI/OpenMP scientific applications at large scales and to explore the tradeoffs between application runtime and power/energy for energy efficient application execution, then use this framework to autotune four ECP proxy applications -- XSBench, AMG, SWFFT, and SW4lite. Our approach uses Bayesian optimization with a Random Forest surrogate model to effectively search parameter spaces with up to 6 million different configurations on two large-scale production systems, Theta at Argonne National Laboratory and Summit at Oak Ridge National Laboratory. The experimental results show that our autotuning framework at large scales has low overhead and achieves good scalability. Using the proposed autotuning framework to identify the best configurations, we achieve up to 91.59% performance improvement, up to 21.2% energy savings, and up to 37.84% EDP improvement on up to 4,096 nodes.