 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging LLMs to Automate Energy-Aware Refactoring of Parallel Scientific Codes
May 04, 2025While large language models (LLMs) are increasingly used for generating parallel scientific code, most current efforts emphasize functional correctness, often overlooking performance and energy considerations. In this work, we propose LASSI-EE, an automated LLM-based refactoring framework that generates energy-efficient parallel code on a target parallel system for a given parallel code as input. Through a multi-stage, iterative pipeline process, LASSI-EE achieved an average energy reduction of 47% across 85% of the 20 HeCBench benchmarks tested on NVIDIA A100 GPUs. Our findings demonstrate the broader potential of LLMs, not only for generating correct code but also for enabling energy-aware programming. We also address key insights and limitations within the framework, offering valuable guidance for future improvements.
LASSI: An LLM-based Automated Self-Correcting Pipeline for Translating Parallel Scientific Codes
Jun 30, 2024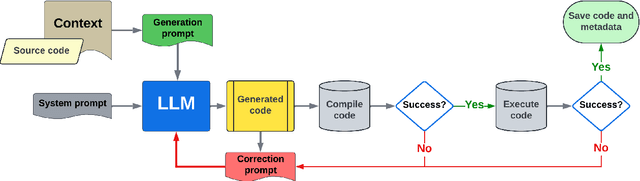

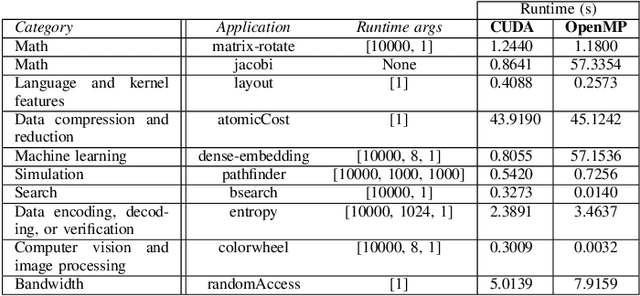
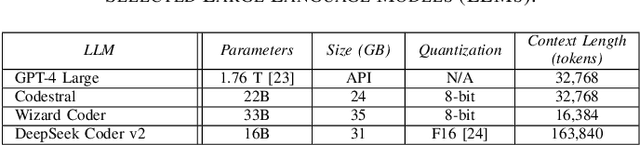
This paper addresses the problem of providing a novel approach to sourcing significant training data for LLMs focused on science and engineering. In particular, a crucial challenge is sourcing parallel scientific codes in the ranges of millions to billions of codes. To tackle this problem, we propose an automated pipeline framework, called LASSI, designed to translate between parallel programming languages by bootstrapping existing closed- or open-source LLMs. LASSI incorporates autonomous enhancement through self-correcting loops where errors encountered during compilation and execution of generated code are fed back to the LLM through guided prompting for debugging and refactoring. We highlight the bi-directional translation of existing GPU benchmarks between OpenMP target offload and CUDA to validate LASSI. The results of evaluating LASSI with different application codes across four LLMs demonstrate the effectiveness of LASSI for generating executable parallel codes, with 80% of OpenMP to CUDA translations and 85% of CUDA to OpenMP translations producing the expected output. We also observe approximately 78% of OpenMP to CUDA translations and 62% of CUDA to OpenMP translations execute within 10% of or at a faster runtime than the original benchmark code in the same language.
An Autotuning-based Optimization Framework for Mixed-kernel SVM Classifications in Smart Pixel Datasets and Heterojunction Transistors
Jun 26, 2024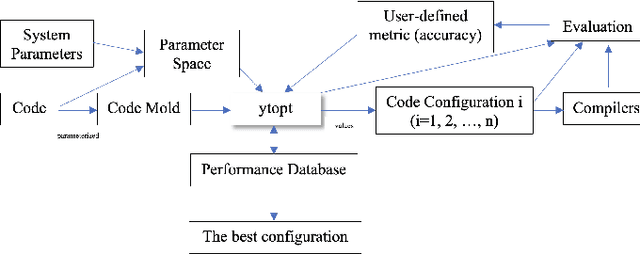
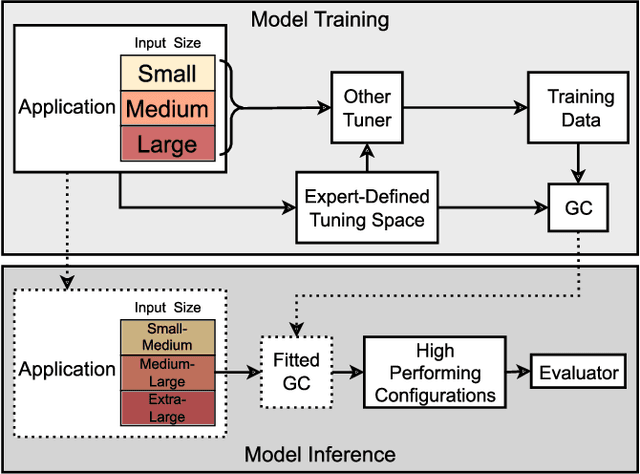
Support Vector Machine (SVM) is a state-of-the-art classification method widely used in science and engineering due to its high accuracy, its ability to deal with high dimensional data, and its flexibility in modeling diverse sources of data. In this paper, we propose an autotuning-based optimization framework to quantify the ranges of hyperparameters in SVMs to identify their optimal choices, and apply the framework to two SVMs with the mixed-kernel between Sigmoid and Gaussian kernels for smart pixel datasets in high energy physics (HEP) and mixed-kernel heterojunction transistors (MKH). Our experimental results show that the optimal selection of hyperparameters in the SVMs and the kernels greatly varies for different applications and datasets, and choosing their optimal choices is critical for a high classification accuracy of the mixed kernel SVMs. Uninformed choices of hyperparameters C and coef0 in the mixed-kernel SVMs result in severely low accuracy, and the proposed framework effectively quantifies the proper ranges for the hyperparameters in the SVMs to identify their optimal choices to achieve the highest accuracy 94.6\% for the HEP application and the highest average accuracy 97.2\% with far less tuning time for the MKH application.
Transfer-Learning-Based Autotuning Using Gaussian Copula
Jan 09, 2024


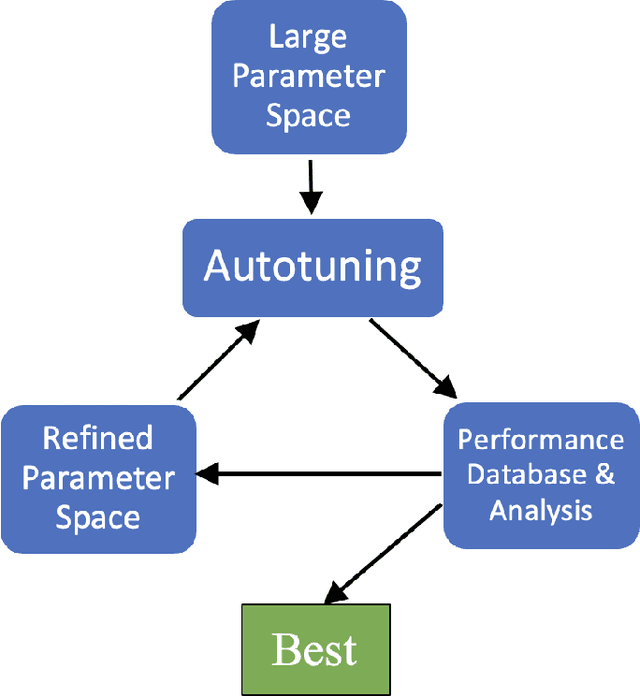
As diverse high-performance computing (HPC) systems are built, many opportunities arise for applications to solve larger problems than ever before. Given the significantly increased complexity of these HPC systems and application tuning, empirical performance tuning, such as autotuning, has emerged as a promising approach in recent years. Despite its effectiveness, autotuning is often a computationally expensive approach. Transfer learning (TL)-based autotuning seeks to address this issue by leveraging the data from prior tuning. Current TL methods for autotuning spend significant time modeling the relationship between parameter configurations and performance, which is ineffective for few-shot (that is, few empirical evaluations) tuning on new tasks. We introduce the first generative TL-based autotuning approach based on the Gaussian copula (GC) to model the high-performing regions of the search space from prior data and then generate high-performing configurations for new tasks. This allows a sampling-based approach that maximizes few-shot performance and provides the first probabilistic estimation of the few-shot budget for effective TL-based autotuning. We compare our generative TL approach with state-of-the-art autotuning techniques on several benchmarks. We find that the GC is capable of achieving 64.37% of peak few-shot performance in its first evaluation. Furthermore, the GC model can determine a few-shot transfer budget that yields up to 33.39$\times$ speedup, a dramatic improvement over the 20.58$\times$ speedup using prior techniques.
* 13 pages, 5 figures, 7 tables, the definitive version of this work is published in the Proceedings of the ACM International Conference on Supercomputing 2023, available at https://dl.acm.org/doi/10.1145/3577193.3593712
Autotuning Apache TVM-based Scientific Applications Using Bayesian Optimization
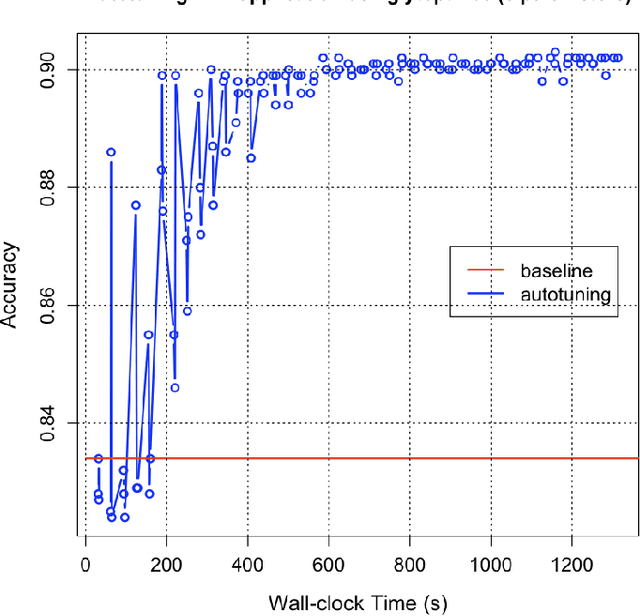
Sep 13, 2023Apache TVM (Tensor Virtual Machine), an open source machine learning compiler framework designed to optimize computations across various hardware platforms, provides an opportunity to improve the performance of dense matrix factorizations such as LU (Lower Upper) decomposition and Cholesky decomposition on GPUs and AI (Artificial Intelligence) accelerators. In this paper, we propose a new TVM autotuning framework using Bayesian Optimization and use the TVM tensor expression language to implement linear algebra kernels such as LU, Cholesky, and 3mm. We use these scientific computation kernels to evaluate the effectiveness of our methods on a GPU cluster, called Swing, at Argonne National Laboratory. We compare the proposed autotuning framework with the TVM autotuning framework AutoTVM with four tuners and find that our framework outperforms AutoTVM in most cases.
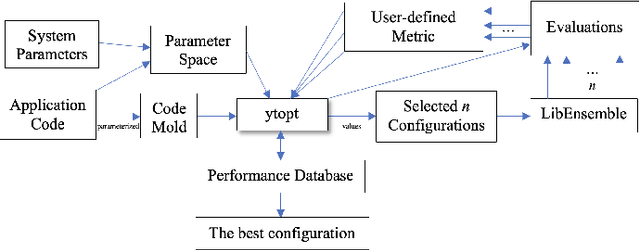
ytopt: Autotuning Scientific Applications for Energy Efficiency at Large Scales
Mar 28, 2023



As we enter the exascale computing era, efficiently utilizing power and optimizing the performance of scientific applications under power and energy constraints has become critical and challenging. We propose a low-overhead autotuning framework to autotune performance and energy for various hybrid MPI/OpenMP scientific applications at large scales and to explore the tradeoffs between application runtime and power/energy for energy efficient application execution, then use this framework to autotune four ECP proxy applications -- XSBench, AMG, SWFFT, and SW4lite. Our approach uses Bayesian optimization with a Random Forest surrogate model to effectively search parameter spaces with up to 6 million different configurations on two large-scale production systems, Theta at Argonne National Laboratory and Summit at Oak Ridge National Laboratory. The experimental results show that our autotuning framework at large scales has low overhead and achieves good scalability. Using the proposed autotuning framework to identify the best configurations, we achieve up to 91.59% performance improvement, up to 21.2% energy savings, and up to 37.84% EDP improvement on up to 4,096 nodes.
Customized Monte Carlo Tree Search for LLVM/Polly's Composable Loop Optimization Transformations
May 10, 2021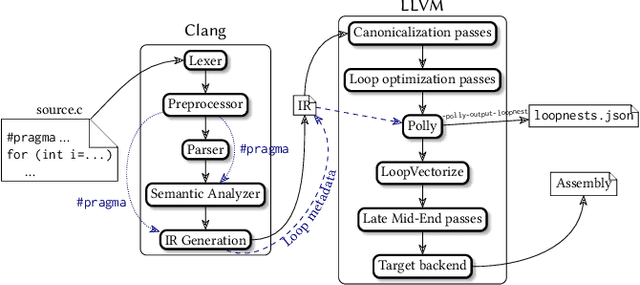
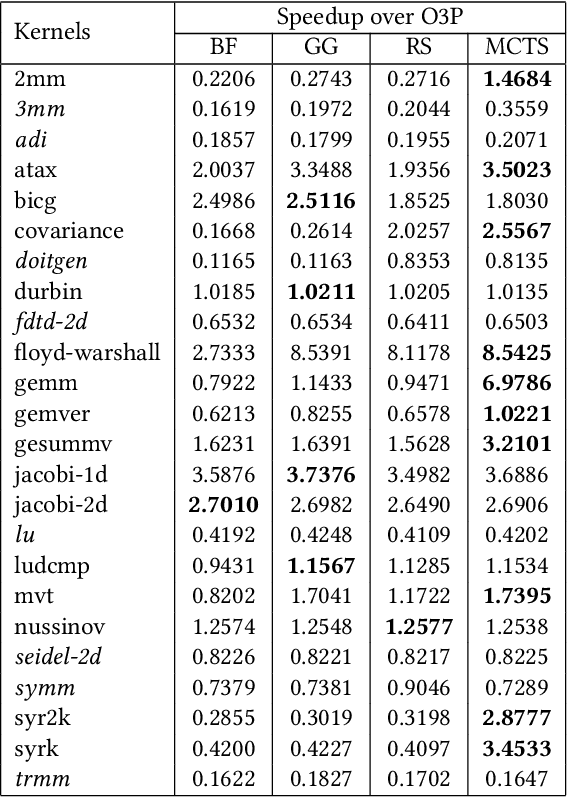
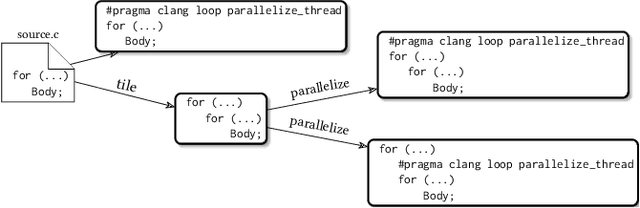
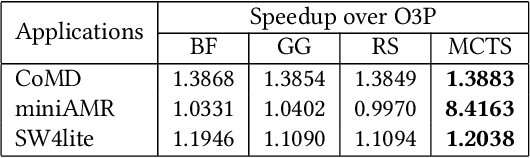
Polly is the LLVM project's polyhedral loop nest optimizer. Recently, user-directed loop transformation pragmas were proposed based on LLVM/Clang and Polly. The search space exposed by the transformation pragmas is a tree, wherein each node represents a specific combination of loop transformations that can be applied to the code resulting from the parent node's loop transformations. We have developed a search algorithm based on Monte Carlo tree search (MCTS) to find the best combination of loop transformations. Our algorithm consists of two phases: exploring loop transformations at different depths of the tree to identify promising regions in the tree search space and exploiting those regions by performing a local search. Moreover, a restart mechanism is used to avoid the MCTS getting trapped in a local solution. The best and worst solutions are transferred from the previous phases of the restarts to leverage the search history. We compare our approach with random, greedy, and breadth-first search methods on PolyBench kernels and ECP proxy applications. Experimental results show that our MCTS algorithm finds pragma combinations with a speedup of 2.3x over Polly's heuristic optimizations on average.
Autotuning PolyBench Benchmarks with LLVM Clang/Polly Loop Optimization Pragmas Using Bayesian Optimization (extended version)
Apr 27, 2021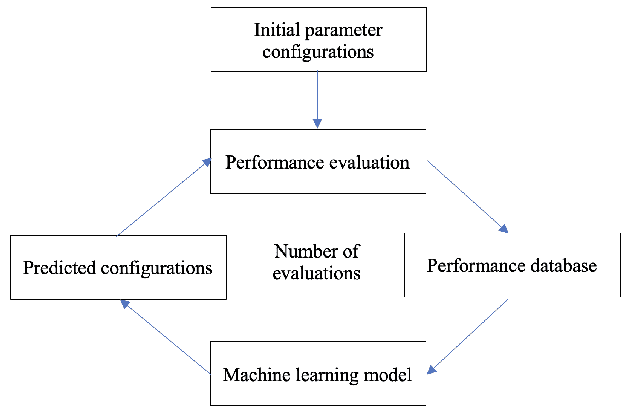

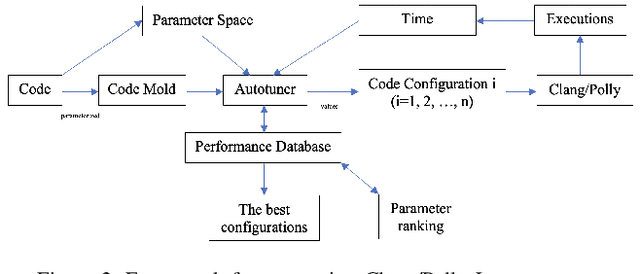

In this paper, we develop a ytopt autotuning framework that leverages Bayesian optimization to explore the parameter space search and compare four different supervised learning methods within Bayesian optimization and evaluate their effectiveness. We select six of the most complex PolyBench benchmarks and apply the newly developed LLVM Clang/Polly loop optimization pragmas to the benchmarks to optimize them. We then use the autotuning framework to optimize the pragma parameters to improve their performance. The experimental results show that our autotuning approach outperforms the other compiling methods to provide the smallest execution time for the benchmarks syr2k, 3mm, heat-3d, lu, and covariance with two large datasets in 200 code evaluations for effectively searching the parameter spaces with up to 170,368 different configurations. We find that the Floyd-Warshall benchmark did not benefit from autotuning because Polly uses heuristics to optimize the benchmark to make it run much slower. To cope with this issue, we provide some compiler option solutions to improve the performance. Then we present loop autotuning without a user's knowledge using a simple mctree autotuning framework to further improve the performance of the Floyd-Warshall benchmark. We also extend the ytopt autotuning framework to tune a deep learning application.
Performance and Power Modeling and Prediction Using MuMMI and Ten Machine Learning Methods
Nov 12, 2020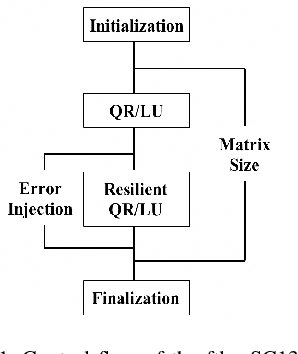
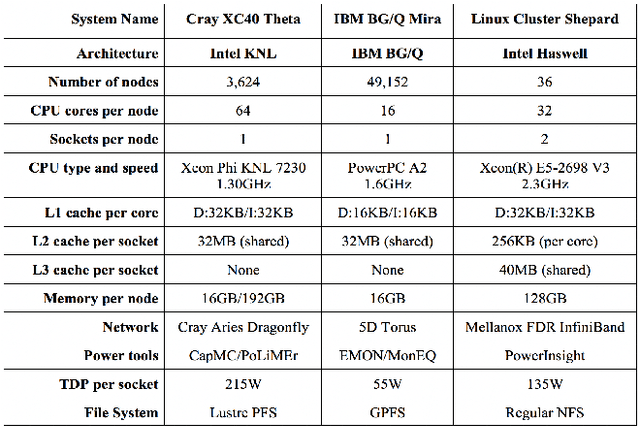
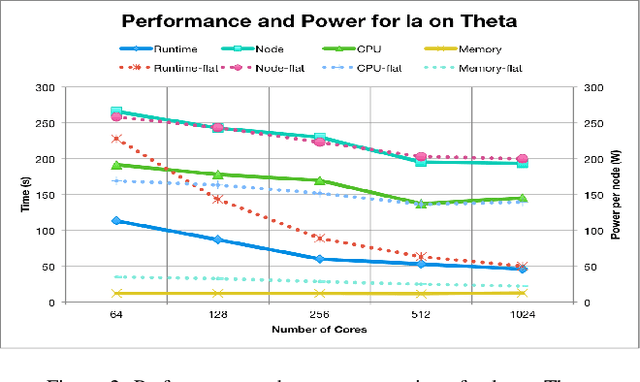
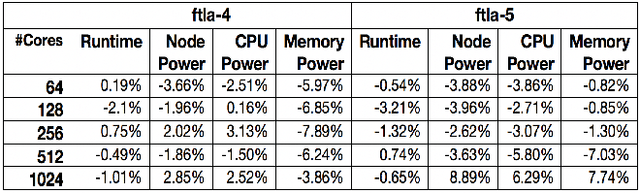
In this paper, we use modeling and prediction tool MuMMI (Multiple Metrics Modeling Infrastructure) and ten machine learning methods to model and predict performance and power and compare their prediction error rates. We use a fault-tolerant linear algebra code and a fault-tolerant heat distribution code to conduct our modeling and prediction study on the Cray XC40 Theta and IBM BG/Q Mira at Argonne National Laboratory and the Intel Haswell cluster Shepard at Sandia National Laboratories. Our experiment results show that the prediction error rates in performance and power using MuMMI are less than 10% for most cases. Based on the models for runtime, node power, CPU power, and memory power, we identify the most significant performance counters for potential optimization efforts associated with the application characteristics and the target architectures, and we predict theoretical outcomes of the potential optimizations. When we compare the prediction accuracy using MuMMI with that using 10 machine learning methods, we observe that MuMMI not only results in more accurate prediction in both performance and power but also presents how performance counters impact the performance and power models. This provides some insights about how to fine-tune the applications and/or systems for energy efficiency.
Utilizing Ensemble Learning for Performance and Power Modeling and Improvement of Parallel Cancer Deep Learning CANDLE Benchmarks
Nov 12, 2020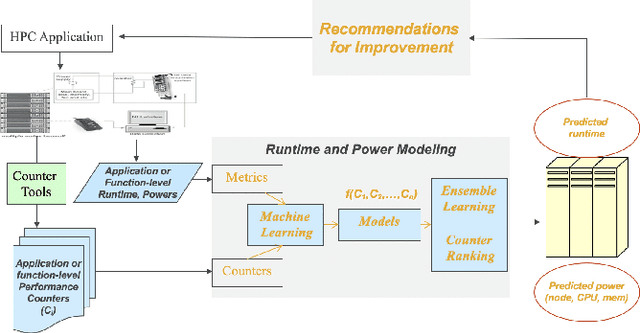
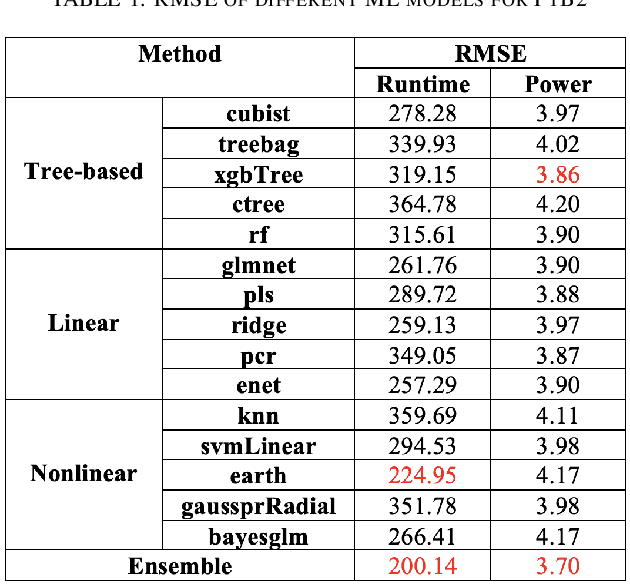
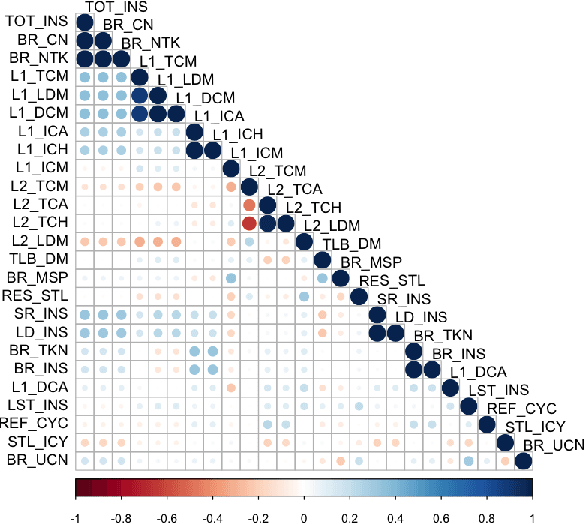
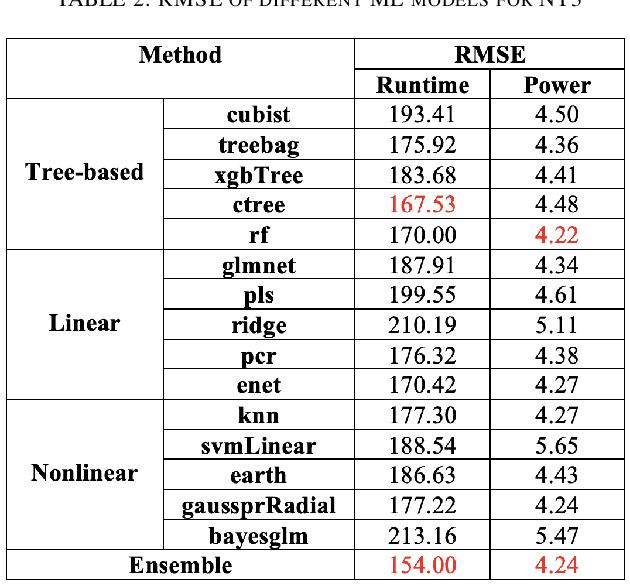
Machine learning (ML) continues to grow in importance across nearly all domains and is a natural tool in modeling to learn from data. Often a tradeoff exists between a model's ability to minimize bias and variance. In this paper, we utilize ensemble learning to combine linear, nonlinear, and tree-/rule-based ML methods to cope with the bias-variance tradeoff and result in more accurate models. Hardware performance counter values are correlated with properties of applications that impact performance and power on the underlying system. We use the datasets collected for two parallel cancer deep learning CANDLE benchmarks, NT3 (weak scaling) and P1B2 (strong scaling), to build performance and power models based on hardware performance counters using single-object and multiple-objects ensemble learning to identify the most important counters for improvement. Based on the insights from these models, we improve the performance and energy of P1B2 and NT3 by optimizing the deep learning environments TensorFlow, Keras, Horovod, and Python under the huge page size of 8 MB on the Cray XC40 Theta at Argonne National Laboratory. Experimental results show that ensemble learning not only produces more accurate models but also provides more robust performance counter ranking. We achieve up to 61.15% performance improvement and up to 62.58% energy saving for P1B2 and up to 55.81% performance improvement and up to 52.60% energy saving for NT3 on up to 24,576 cores.