 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLASSI: An LLM-based Automated Self-Correcting Pipeline for Translating Parallel Scientific Codes
Paper and Code
Jun 30, 2024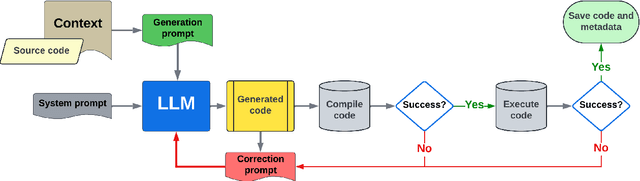

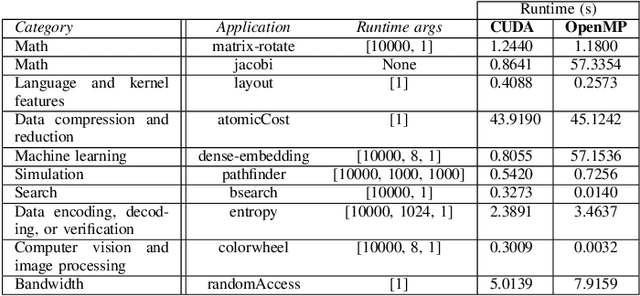
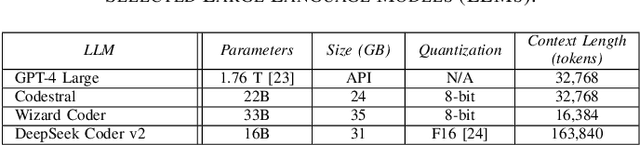
This paper addresses the problem of providing a novel approach to sourcing significant training data for LLMs focused on science and engineering. In particular, a crucial challenge is sourcing parallel scientific codes in the ranges of millions to billions of codes. To tackle this problem, we propose an automated pipeline framework, called LASSI, designed to translate between parallel programming languages by bootstrapping existing closed- or open-source LLMs. LASSI incorporates autonomous enhancement through self-correcting loops where errors encountered during compilation and execution of generated code are fed back to the LLM through guided prompting for debugging and refactoring. We highlight the bi-directional translation of existing GPU benchmarks between OpenMP target offload and CUDA to validate LASSI. The results of evaluating LASSI with different application codes across four LLMs demonstrate the effectiveness of LASSI for generating executable parallel codes, with 80% of OpenMP to CUDA translations and 85% of CUDA to OpenMP translations producing the expected output. We also observe approximately 78% of OpenMP to CUDA translations and 62% of CUDA to OpenMP translations execute within 10% of or at a faster runtime than the original benchmark code in the same language.