 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Transformers are Versatile In-Context Learners
Paper and Code
Feb 21, 2024


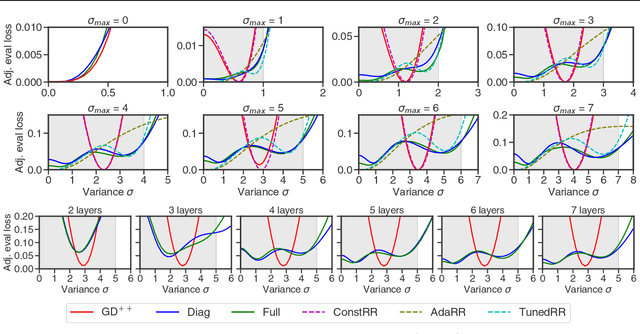
Recent research has demonstrated that transformers, particularly linear attention models, implicitly execute gradient-descent-like algorithms on data provided in-context during their forward inference step. However, their capability in handling more complex problems remains unexplored. In this paper, we prove that any linear transformer maintains an implicit linear model and can be interpreted as performing a variant of preconditioned gradient descent. We also investigate the use of linear transformers in a challenging scenario where the training data is corrupted with different levels of noise. Remarkably, we demonstrate that for this problem linear transformers discover an intricate and highly effective optimization algorithm, surpassing or matching in performance many reasonable baselines. We reverse-engineer this algorithm and show that it is a novel approach incorporating momentum and adaptive rescaling based on noise levels. Our findings show that even linear transformers possess the surprising ability to discover sophisticated optimization strategies.