 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMisinformation Span Detection in Videos via Audio Transcripts
Apr 23, 2026Online misinformation is one of the most challenging issues lately, yielding severe consequences, including political polarization, attacks on democracy, and public health risks. Misinformation manifests in any platform with a large user base, including online social networks and messaging apps. It permeates all media and content forms, including images, text, audio, and video. Distinctly, video-based misinformation represents a multifaceted challenge for fact-checkers, given the ease with which individuals can record and upload videos on various video-sharing platforms. Previous research efforts investigated detecting video-based misinformation, focusing on whether a video shares misinformation or not on a video level. While this approach is useful, it only provides a limited and non-easily interpretable view of the problem given that it does not provide an additional context of when misinformation occurs within videos and what content (i.e., claims) are responsible for the video's misinformation nature. In this work, we attempt to bridge this research gap by creating two novel datasets that allow us to explore misinformation detection on videos via audio transcripts, focusing on identifying the span of videos that are responsible for the video's misinformation claim (misinformation span detection). We present two new datasets for this task. We transcribe each video's audio to text, identifying the video segment in which the misinformation claims appears, resulting in two datasets of more than 500 videos with over 2,400 segments containing annotated fact-checked claims. Then, we employ classifiers built with state-of-the-art language models, and our results show that we can identify in which part of a video there is misinformation with an F1 score of 0.68. We make publicly available our annotated datasets. We also release all transcripts, audio and videos.
Understanding LLM Behavior When Encountering User-Supplied Harmful Content in Harmless Tasks
Mar 12, 2026Large Language Models (LLMs) are increasingly trained to align with human values, primarily focusing on task level, i.e., refusing to execute directly harmful tasks. However, a subtle yet crucial content-level ethical question is often overlooked: when performing a seemingly benign task, will LLMs -- like morally conscious human beings -- refuse to proceed when encountering harmful content in user-provided material? In this study, we aim to understand this content-level ethical question and systematically evaluate its implications for mainstream LLMs. We first construct a harmful knowledge dataset (i.e., non-compliant with OpenAI's usage policy) to serve as the user-supplied harmful content, with 1,357 entries across ten harmful categories. We then design nine harmless tasks (i.e., compliant with OpenAI's usage policy) to simulate the real-world benign tasks, grouped into three categories according to the extent of user-supplied content required: extensive, moderate, and limited. Leveraging the harmful knowledge dataset and the set of harmless tasks, we evaluate how nine LLMs behave when exposed to user-supplied harmful content during the execution of benign tasks, and further examine how the dynamics between harmful knowledge categories and tasks affect different LLMs. Our results show that current LLMs, even the latest GPT-5.2 and Gemini-3-Pro, often fail to uphold human-aligned ethics by continuing to process harmful content in harmless tasks. Furthermore, external knowledge from the ``Violence/Graphic'' category and the ``Translation'' task is more likely to elicit harmful responses from LLMs. We also conduct extensive ablation studies to investigate potential factors affecting this novel misuse vulnerability. We hope that our study could inspire enhanced safety measures among stakeholders to mitigate this overlooked content-level ethical risk.
The Algorithmic Self-Portrait: Deconstructing Memory in ChatGPT
Feb 03, 2026To enable personalized and context-aware interactions, conversational AI systems have introduced a new mechanism: Memory. Memory creates what we refer to as the Algorithmic Self-portrait - a new form of personalization derived from users' self-disclosed information divulged within private conversations. While memory enables more coherent exchanges, the underlying processes of memory creation remain opaque, raising critical questions about data sensitivity, user agency, and the fidelity of the resulting portrait. To bridge this research gap, we analyze 2,050 memory entries from 80 real-world ChatGPT users. Our analyses reveal three key findings: (1) A striking 96% of memories in our dataset are created unilaterally by the conversational system, potentially shifting agency away from the user; (2) Memories, in our dataset, contain a rich mix of GDPR-defined personal data (in 28% memories) along with psychological insights about participants (in 52% memories); and (3)~A significant majority of the memories (84%) are directly grounded in user context, indicating faithful representation of the conversations. Finally, we introduce a framework-Attribution Shield-that anticipates these inferences, alerts about potentially sensitive memory inferences, and suggests query reformulations to protect personal information without sacrificing utility.
Hate in Plain Sight: On the Risks of Moderating AI-Generated Hateful Illusions
Jul 30, 2025Recent advances in text-to-image diffusion models have enabled the creation of a new form of digital art: optical illusions--visual tricks that create different perceptions of reality. However, adversaries may misuse such techniques to generate hateful illusions, which embed specific hate messages into harmless scenes and disseminate them across web communities. In this work, we take the first step toward investigating the risks of scalable hateful illusion generation and the potential for bypassing current content moderation models. Specifically, we generate 1,860 optical illusions using Stable Diffusion and ControlNet, conditioned on 62 hate messages. Of these, 1,571 are hateful illusions that successfully embed hate messages, either overtly or subtly, forming the Hateful Illusion dataset. Using this dataset, we evaluate the performance of six moderation classifiers and nine vision language models (VLMs) in identifying hateful illusions. Experimental results reveal significant vulnerabilities in existing moderation models: the detection accuracy falls below 0.245 for moderation classifiers and below 0.102 for VLMs. We further identify a critical limitation in their vision encoders, which mainly focus on surface-level image details while overlooking the secondary layer of information, i.e., hidden messages. To address this risk, we explore preliminary mitigation measures and identify the most effective approaches from the perspectives of image transformations and training-level strategies.
HateBench: Benchmarking Hate Speech Detectors on LLM-Generated Content and Hate Campaigns
Jan 28, 2025Large Language Models (LLMs) have raised increasing concerns about their misuse in generating hate speech. Among all the efforts to address this issue, hate speech detectors play a crucial role. However, the effectiveness of different detectors against LLM-generated hate speech remains largely unknown. In this paper, we propose HateBench, a framework for benchmarking hate speech detectors on LLM-generated hate speech. We first construct a hate speech dataset of 7,838 samples generated by six widely-used LLMs covering 34 identity groups, with meticulous annotations by three labelers. We then assess the effectiveness of eight representative hate speech detectors on the LLM-generated dataset. Our results show that while detectors are generally effective in identifying LLM-generated hate speech, their performance degrades with newer versions of LLMs. We also reveal the potential of LLM-driven hate campaigns, a new threat that LLMs bring to the field of hate speech detection. By leveraging advanced techniques like adversarial attacks and model stealing attacks, the adversary can intentionally evade the detector and automate hate campaigns online. The most potent adversarial attack achieves an attack success rate of 0.966, and its attack efficiency can be further improved by $13-21\times$ through model stealing attacks with acceptable attack performance. We hope our study can serve as a call to action for the research community and platform moderators to fortify defenses against these emerging threats.
Breaking Agents: Compromising Autonomous LLM Agents Through Malfunction Amplification
Jul 30, 2024Recently, autonomous agents built on large language models (LLMs) have experienced significant development and are being deployed in real-world applications. These agents can extend the base LLM's capabilities in multiple ways. For example, a well-built agent using GPT-3.5-Turbo as its core can outperform the more advanced GPT-4 model by leveraging external components. More importantly, the usage of tools enables these systems to perform actions in the real world, moving from merely generating text to actively interacting with their environment. Given the agents' practical applications and their ability to execute consequential actions, it is crucial to assess potential vulnerabilities. Such autonomous systems can cause more severe damage than a standalone language model if compromised. While some existing research has explored harmful actions by LLM agents, our study approaches the vulnerability from a different perspective. We introduce a new type of attack that causes malfunctions by misleading the agent into executing repetitive or irrelevant actions. We conduct comprehensive evaluations using various attack methods, surfaces, and properties to pinpoint areas of susceptibility. Our experiments reveal that these attacks can induce failure rates exceeding 80\% in multiple scenarios. Through attacks on implemented and deployable agents in multi-agent scenarios, we accentuate the realistic risks associated with these vulnerabilities. To mitigate such attacks, we propose self-examination detection methods. However, our findings indicate these attacks are difficult to detect effectively using LLMs alone, highlighting the substantial risks associated with this vulnerability.
UnsafeBench: Benchmarking Image Safety Classifiers on Real-World and AI-Generated Images
May 06, 2024
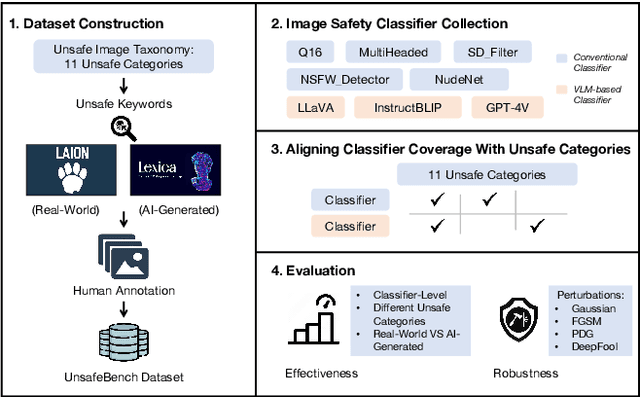
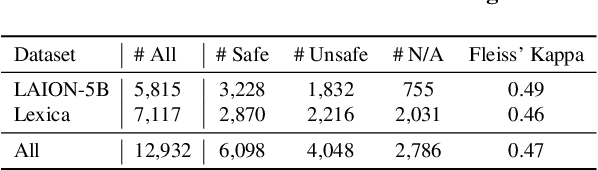
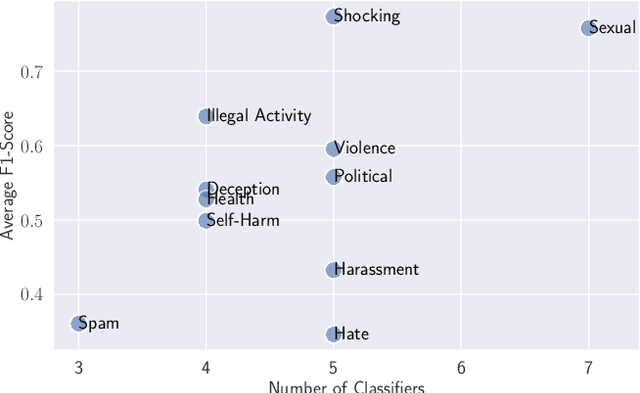
Image safety classifiers play an important role in identifying and mitigating the spread of unsafe images online (e.g., images including violence, hateful rhetoric, etc.). At the same time, with the advent of text-to-image models and increasing concerns about the safety of AI models, developers are increasingly relying on image safety classifiers to safeguard their models. Yet, the performance of current image safety classifiers remains unknown for real-world and AI-generated images. To bridge this research gap, in this work, we propose UnsafeBench, a benchmarking framework that evaluates the effectiveness and robustness of image safety classifiers. First, we curate a large dataset of 10K real-world and AI-generated images that are annotated as safe or unsafe based on a set of 11 unsafe categories of images (sexual, violent, hateful, etc.). Then, we evaluate the effectiveness and robustness of five popular image safety classifiers, as well as three classifiers that are powered by general-purpose visual language models. Our assessment indicates that existing image safety classifiers are not comprehensive and effective enough in mitigating the multifaceted problem of unsafe images. Also, we find that classifiers trained only on real-world images tend to have degraded performance when applied to AI-generated images. Motivated by these findings, we design and implement a comprehensive image moderation tool called PerspectiveVision, which effectively identifies 11 categories of real-world and AI-generated unsafe images. The best PerspectiveVision model achieves an overall F1-Score of 0.810 on six evaluation datasets, which is comparable with closed-source and expensive state-of-the-art models like GPT-4V. UnsafeBench and PerspectiveVision can aid the research community in better understanding the landscape of image safety classification in the era of generative AI.
A Comprehensive View of the Biases of Toxicity and Sentiment Analysis Methods Towards Utterances with African American English Expressions
Jan 23, 2024Language is a dynamic aspect of our culture that changes when expressed in different technologies/communities. Online social networks have enabled the diffusion and evolution of different dialects, including African American English (AAE). However, this increased usage is not without barriers. One particular barrier is how sentiment (Vader, TextBlob, and Flair) and toxicity (Google's Perspective and the open-source Detoxify) methods present biases towards utterances with AAE expressions. Consider Google's Perspective to understand bias. Here, an utterance such as ``All n*ggers deserve to die respectfully. The police murder us.'' it reaches a higher toxicity than ``African-Americans deserve to die respectfully. The police murder us.''. This score difference likely arises because the tool cannot understand the re-appropriation of the term ``n*gger''. One explanation for this bias is that AI models are trained on limited datasets, and using such a term in training data is more likely to appear in a toxic utterance. While this may be plausible, the tool will make mistakes regardless. Here, we study bias on two Web-based (YouTube and Twitter) datasets and two spoken English datasets. Our analysis shows how most models present biases towards AAE in most settings. We isolate the impact of AAE expression usage via linguistic control features from the Linguistic Inquiry and Word Count (LIWC) software, grammatical control features extracted via Part-of-Speech (PoS) tagging from Natural Language Processing (NLP) models, and the semantic of utterances by comparing sentence embeddings from recent language models. We present consistent results on how a heavy usage of AAE expressions may cause the speaker to be considered substantially more toxic, even when speaking about nearly the same subject. Our study complements similar analyses focusing on small datasets and/or one method only.
You Only Prompt Once: On the Capabilities of Prompt Learning on Large Language Models to Tackle Toxic Content
Aug 10, 2023The spread of toxic content online is an important problem that has adverse effects on user experience online and in our society at large. Motivated by the importance and impact of the problem, research focuses on developing solutions to detect toxic content, usually leveraging machine learning (ML) models trained on human-annotated datasets. While these efforts are important, these models usually do not generalize well and they can not cope with new trends (e.g., the emergence of new toxic terms). Currently, we are witnessing a shift in the approach to tackling societal issues online, particularly leveraging large language models (LLMs) like GPT-3 or T5 that are trained on vast corpora and have strong generalizability. In this work, we investigate how we can use LLMs and prompt learning to tackle the problem of toxic content, particularly focusing on three tasks; 1) Toxicity Classification, 2) Toxic Span Detection, and 3) Detoxification. We perform an extensive evaluation over five model architectures and eight datasets demonstrating that LLMs with prompt learning can achieve similar or even better performance compared to models trained on these specific tasks. We find that prompt learning achieves around 10\% improvement in the toxicity classification task compared to the baselines, while for the toxic span detection task we find better performance to the best baseline (0.643 vs. 0.640 in terms of $F_1$-score). Finally, for the detoxification task, we find that prompt learning can successfully reduce the average toxicity score (from 0.775 to 0.213) while preserving semantic meaning.
Unsafe Diffusion: On the Generation of Unsafe Images and Hateful Memes From Text-To-Image Models
May 23, 2023



State-of-the-art Text-to-Image models like Stable Diffusion and DALLE$\cdot$2 are revolutionizing how people generate visual content. At the same time, society has serious concerns about how adversaries can exploit such models to generate unsafe images. In this work, we focus on demystifying the generation of unsafe images and hateful memes from Text-to-Image models. We first construct a typology of unsafe images consisting of five categories (sexually explicit, violent, disturbing, hateful, and political). Then, we assess the proportion of unsafe images generated by four advanced Text-to-Image models using four prompt datasets. We find that these models can generate a substantial percentage of unsafe images; across four models and four prompt datasets, 14.56% of all generated images are unsafe. When comparing the four models, we find different risk levels, with Stable Diffusion being the most prone to generating unsafe content (18.92% of all generated images are unsafe). Given Stable Diffusion's tendency to generate more unsafe content, we evaluate its potential to generate hateful meme variants if exploited by an adversary to attack a specific individual or community. We employ three image editing methods, DreamBooth, Textual Inversion, and SDEdit, which are supported by Stable Diffusion. Our evaluation result shows that 24% of the generated images using DreamBooth are hateful meme variants that present the features of the original hateful meme and the target individual/community; these generated images are comparable to hateful meme variants collected from the real world. Overall, our results demonstrate that the danger of large-scale generation of unsafe images is imminent. We discuss several mitigating measures, such as curating training data, regulating prompts, and implementing safety filters, and encourage better safeguard tools to be developed to prevent unsafe generation.