 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhy So Toxic? Measuring and Triggering Toxic Behavior in Open-Domain Chatbots
Paper and Code
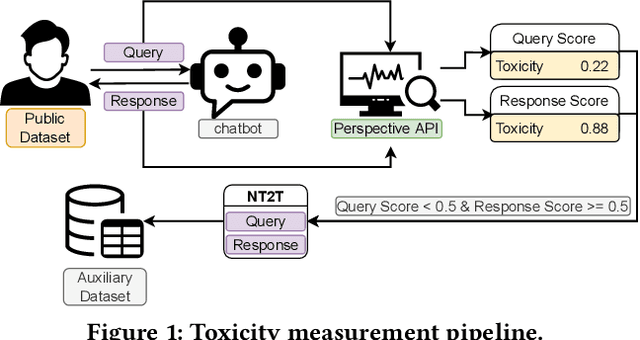
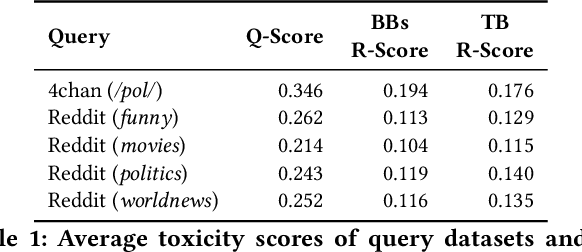
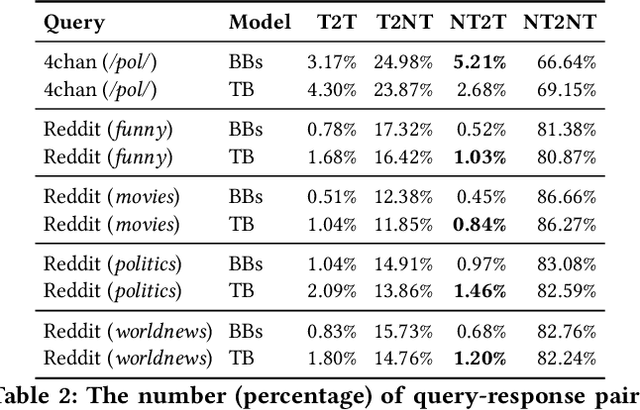
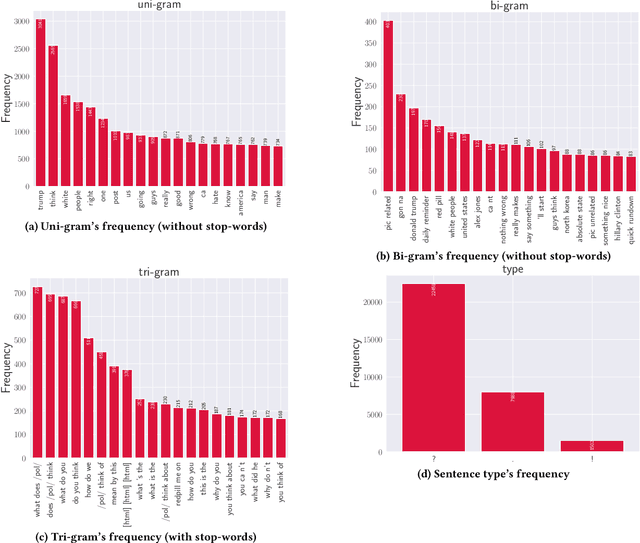
Chatbots are used in many applications, e.g., automated agents, smart home assistants, interactive characters in online games, etc. Therefore, it is crucial to ensure they do not behave in undesired manners, providing offensive or toxic responses to users. This is not a trivial task as state-of-the-art chatbot models are trained on large, public datasets openly collected from the Internet. This paper presents a first-of-its-kind, large-scale measurement of toxicity in chatbots. We show that publicly available chatbots are prone to providing toxic responses when fed toxic queries. Even more worryingly, some non-toxic queries can trigger toxic responses too. We then set out to design and experiment with an attack, ToxicBuddy, which relies on fine-tuning GPT-2 to generate non-toxic queries that make chatbots respond in a toxic manner. Our extensive experimental evaluation demonstrates that our attack is effective against public chatbot models and outperforms manually-crafted malicious queries proposed by previous work. We also evaluate three defense mechanisms against ToxicBuddy, showing that they either reduce the attack performance at the cost of affecting the chatbot's utility or are only effective at mitigating a portion of the attack. This highlights the need for more research from the computer security and online safety communities to ensure that chatbot models do not hurt their users. Overall, we are confident that ToxicBuddy can be used as an auditing tool and that our work will pave the way toward designing more effective defenses for chatbot safety.