 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExcessive Reasoning Attack on Reasoning LLMs
Jun 17, 2025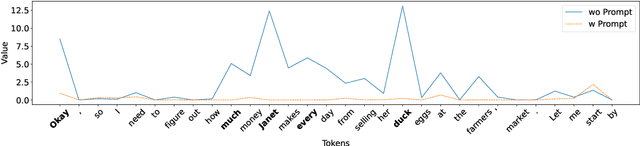


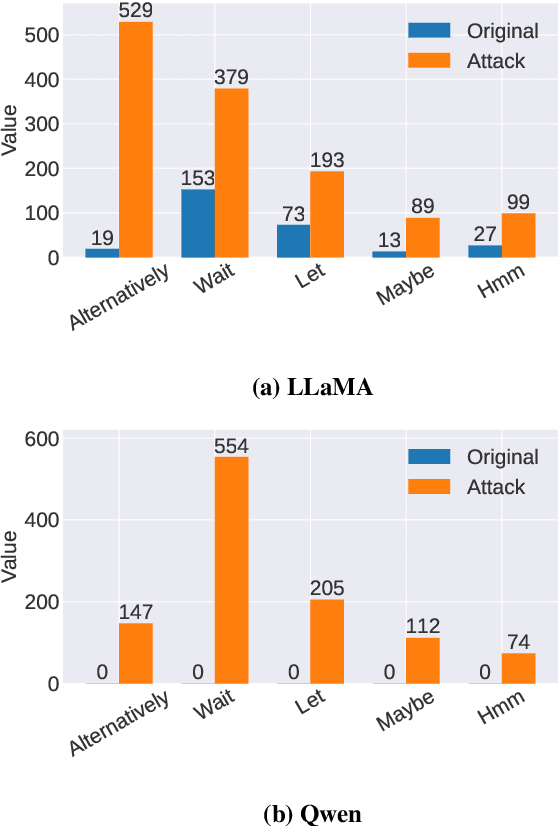
Recent reasoning large language models (LLMs), such as OpenAI o1 and DeepSeek-R1, exhibit strong performance on complex tasks through test-time inference scaling. However, prior studies have shown that these models often incur significant computational costs due to excessive reasoning, such as frequent switching between reasoning trajectories (e.g., underthinking) or redundant reasoning on simple questions (e.g., overthinking). In this work, we expose a novel threat: adversarial inputs can be crafted to exploit excessive reasoning behaviors and substantially increase computational overhead without compromising model utility. Therefore, we propose a novel loss framework consisting of three components: (1) Priority Cross-Entropy Loss, a modification of the standard cross-entropy objective that emphasizes key tokens by leveraging the autoregressive nature of LMs; (2) Excessive Reasoning Loss, which encourages the model to initiate additional reasoning paths during inference; and (3) Delayed Termination Loss, which is designed to extend the reasoning process and defer the generation of final outputs. We optimize and evaluate our attack for the GSM8K and ORCA datasets on DeepSeek-R1-Distill-LLaMA and DeepSeek-R1-Distill-Qwen. Empirical results demonstrate a 3x to 9x increase in reasoning length with comparable utility performance. Furthermore, our crafted adversarial inputs exhibit transferability, inducing computational overhead in o3-mini, o1-mini, DeepSeek-R1, and QWQ models.
SaLoRA: Safety-Alignment Preserved Low-Rank Adaptation
Jan 03, 2025



As advancements in large language models (LLMs) continue and the demand for personalized models increases, parameter-efficient fine-tuning (PEFT) methods (e.g., LoRA) will become essential due to their efficiency in reducing computation costs. However, recent studies have raised alarming concerns that LoRA fine-tuning could potentially compromise the safety alignment in LLMs, posing significant risks for the model owner. In this paper, we first investigate the underlying mechanism by analyzing the changes in safety alignment related features before and after fine-tuning. Then, we propose a fixed safety module calculated by safety data and a task-specific initialization for trainable parameters in low-rank adaptations, termed Safety-alignment preserved Low-Rank Adaptation (SaLoRA). Unlike previous LoRA methods and their variants, SaLoRA enables targeted modifications to LLMs without disrupting their original alignments. Our experiments show that SaLoRA outperforms various adapters-based approaches across various evaluation metrics in different fine-tuning tasks.
ICLGuard: Controlling In-Context Learning Behavior for Applicability Authorization
Jul 09, 2024



In-context learning (ICL) is a recent advancement in the capabilities of large language models (LLMs). This feature allows users to perform a new task without updating the model. Concretely, users can address tasks during the inference time by conditioning on a few input-label pair demonstrations along with the test input. It is different than the conventional fine-tuning paradigm and offers more flexibility. However, this capability also introduces potential issues. For example, users may use the model on any data without restriction, such as performing tasks with improper or sensitive content, which might violate the model policy or conflict with the model owner's interests. As a model owner, it is crucial to establish a mechanism to control the model's behavior under ICL, depending on the model owner's requirements for various content. To this end, we introduce the concept of "applicability authorization" tailored for LLMs, particularly for ICL behavior, and propose a simple approach, ICLGuard. It is a fine-tuning framework designed to allow the model owner to regulate ICL behavior on different data. ICLGuard preserves the original LLM and fine-tunes only a minimal set of additional trainable parameters to "guard" the LLM. Empirical results show that the guarded LLM can deactivate its ICL ability on target data without affecting its ICL ability on other data and its general functionality across all data.
Mondrian: Prompt Abstraction Attack Against Large Language Models for Cheaper API Pricing
Aug 07, 2023



The Machine Learning as a Service (MLaaS) market is rapidly expanding and becoming more mature. For example, OpenAI's ChatGPT is an advanced large language model (LLM) that generates responses for various queries with associated fees. Although these models can deliver satisfactory performance, they are far from perfect. Researchers have long studied the vulnerabilities and limitations of LLMs, such as adversarial attacks and model toxicity. Inevitably, commercial ML models are also not exempt from such issues, which can be problematic as MLaaS continues to grow. In this paper, we discover a new attack strategy against LLM APIs, namely the prompt abstraction attack. Specifically, we propose Mondrian, a simple and straightforward method that abstracts sentences, which can lower the cost of using LLM APIs. In this approach, the adversary first creates a pseudo API (with a lower established price) to serve as the proxy of the target API (with a higher established price). Next, the pseudo API leverages Mondrian to modify the user query, obtain the abstracted response from the target API, and forward it back to the end user. Our results show that Mondrian successfully reduces user queries' token length ranging from 13% to 23% across various tasks, including text classification, generation, and question answering. Meanwhile, these abstracted queries do not significantly affect the utility of task-specific and general language models like ChatGPT. Mondrian also reduces instruction prompts' token length by at least 11% without compromising output quality. As a result, the prompt abstraction attack enables the adversary to profit without bearing the cost of API development and deployment.
Two-in-One: A Model Hijacking Attack Against Text Generation Models
May 12, 2023
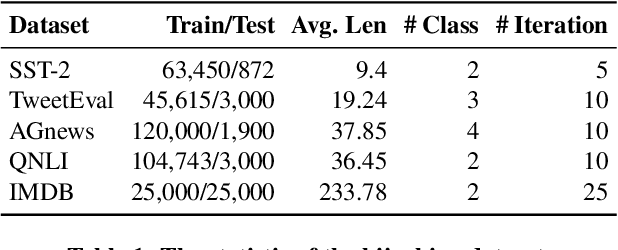


Machine learning has progressed significantly in various applications ranging from face recognition to text generation. However, its success has been accompanied by different attacks. Recently a new attack has been proposed which raises both accountability and parasitic computing risks, namely the model hijacking attack. Nevertheless, this attack has only focused on image classification tasks. In this work, we broaden the scope of this attack to include text generation and classification models, hence showing its broader applicability. More concretely, we propose a new model hijacking attack, Ditto, that can hijack different text classification tasks into multiple generation ones, e.g., language translation, text summarization, and language modeling. We use a range of text benchmark datasets such as SST-2, TweetEval, AGnews, QNLI, and IMDB to evaluate the performance of our attacks. Our results show that by using Ditto, an adversary can successfully hijack text generation models without jeopardizing their utility.
Why So Toxic? Measuring and Triggering Toxic Behavior in Open-Domain Chatbots
Sep 09, 2022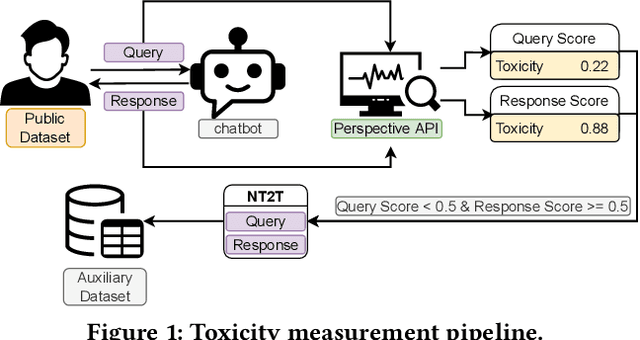
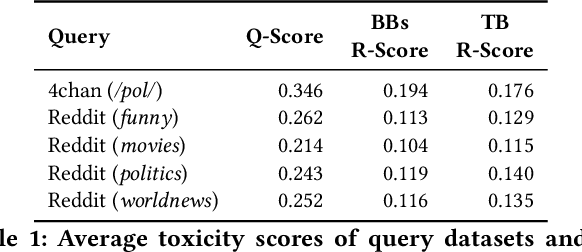
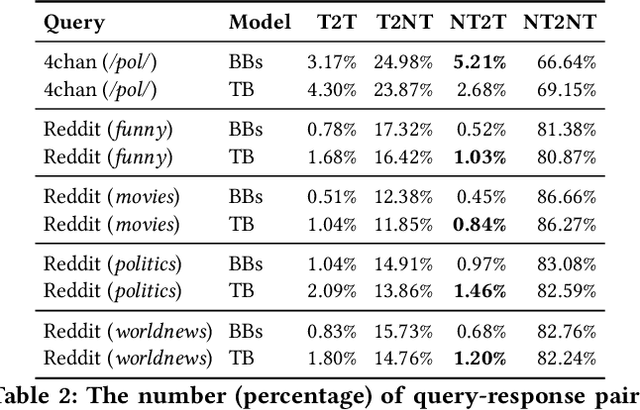
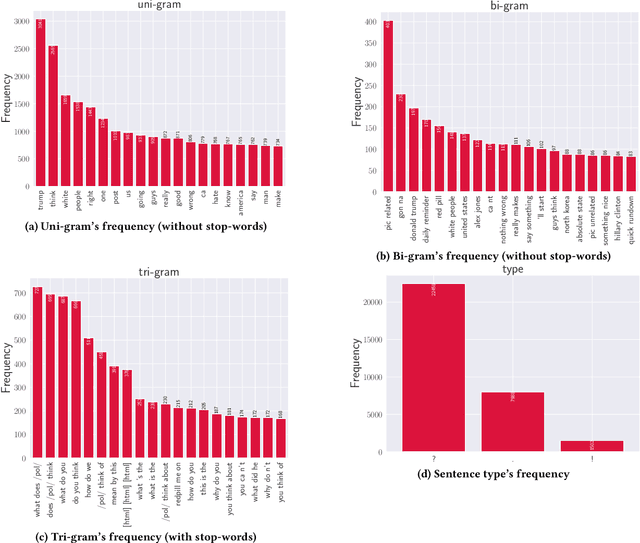
Chatbots are used in many applications, e.g., automated agents, smart home assistants, interactive characters in online games, etc. Therefore, it is crucial to ensure they do not behave in undesired manners, providing offensive or toxic responses to users. This is not a trivial task as state-of-the-art chatbot models are trained on large, public datasets openly collected from the Internet. This paper presents a first-of-its-kind, large-scale measurement of toxicity in chatbots. We show that publicly available chatbots are prone to providing toxic responses when fed toxic queries. Even more worryingly, some non-toxic queries can trigger toxic responses too. We then set out to design and experiment with an attack, ToxicBuddy, which relies on fine-tuning GPT-2 to generate non-toxic queries that make chatbots respond in a toxic manner. Our extensive experimental evaluation demonstrates that our attack is effective against public chatbot models and outperforms manually-crafted malicious queries proposed by previous work. We also evaluate three defense mechanisms against ToxicBuddy, showing that they either reduce the attack performance at the cost of affecting the chatbot's utility or are only effective at mitigating a portion of the attack. This highlights the need for more research from the computer security and online safety communities to ensure that chatbot models do not hurt their users. Overall, we are confident that ToxicBuddy can be used as an auditing tool and that our work will pave the way toward designing more effective defenses for chatbot safety.
Telling Stories through Multi-User Dialogue by Modeling Character Relations
May 31, 2021
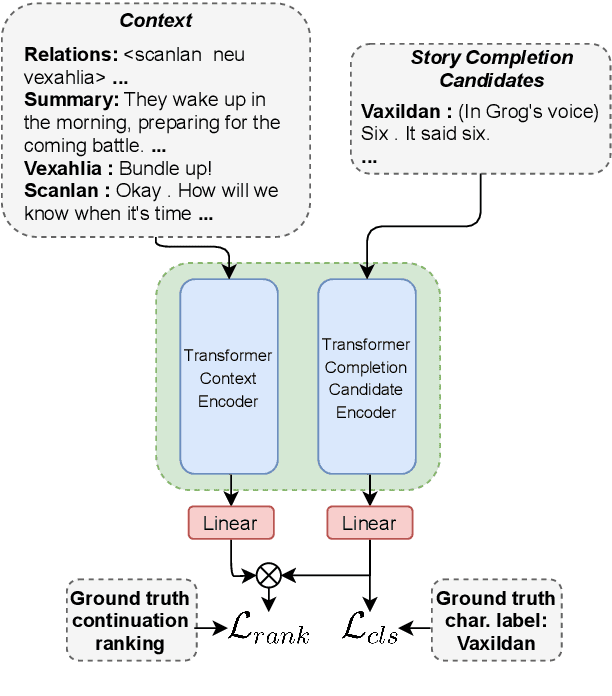
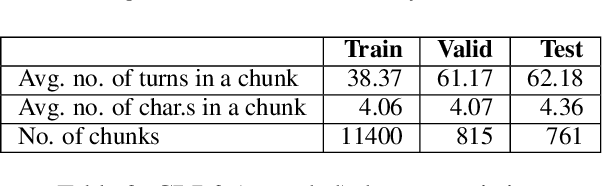
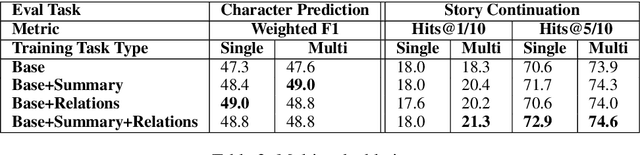
This paper explores character-driven story continuation, in which the story emerges through characters' first- and second-person narration as well as dialogue -- requiring models to select language that is consistent with a character's persona and their relationships with other characters while following and advancing the story. We hypothesize that a multi-task model that trains on character dialogue plus character relationship information improves transformer-based story continuation. To this end, we extend the Critical Role Dungeons and Dragons Dataset (Rameshkumar and Bailey, 2020) -- consisting of dialogue transcripts of people collaboratively telling a story while playing the role-playing game Dungeons and Dragons -- with automatically extracted relationships between each pair of interacting characters as well as their personas. A series of ablations lend evidence to our hypothesis, showing that our multi-task model using character relationships improves story continuation accuracy over strong baselines.