 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-Centric Perception for Child Sexual Abuse Imagery
Apr 02, 2026Law enforcement agencies and non-gonvernmental organizations handling reports of Child Sexual Abuse Imagery (CSAI) are overwhelmed by large volumes of data, requiring the aid of automation tools. However, defining sexual abuse in images of children is inherently challenging, encompassing sexually explicit activities and hints of sexuality conveyed by the individual's pose, or their attire. CSAI classification methods often rely on black-box approaches, targeting broad and abstract concepts such as pornography. Thus, our work is an in-depth exploration of tasks from the literature on Human-Centric Perception, across the domains of safe images, adult pornography, and CSAI, focusing on targets that enable more objective and explainable pipelines for CSAI classification in the future. We introduce the Body-Keypoint-Part Dataset (BKPD), gathering images of people from varying age groups and sexual explicitness to approximate the domain of CSAI, along with manually curated hierarchically structured labels for skeletal keypoints and bounding boxes for person and body parts, including head, chest, hip, and hands. We propose two methods, namely BKP-Association and YOLO-BKP, for simultaneous pose estimation and detection, with targets associated per individual for a comprehensive decomposed representation of each person. Our methods are benchmarked on COCO-Keypoints and COCO-HumanParts, as well as our human-centric dataset, achieving competitive results with models that jointly perform all tasks. Cross-domain ablation studies on BKPD and a case study on RCPD highlight the challenges posed by sexually explicit domains. Our study addresses previously unexplored targets in the CSAI domain, paving the way for novel research opportunities.
A Comprehensive View of the Biases of Toxicity and Sentiment Analysis Methods Towards Utterances with African American English Expressions
Jan 23, 2024Language is a dynamic aspect of our culture that changes when expressed in different technologies/communities. Online social networks have enabled the diffusion and evolution of different dialects, including African American English (AAE). However, this increased usage is not without barriers. One particular barrier is how sentiment (Vader, TextBlob, and Flair) and toxicity (Google's Perspective and the open-source Detoxify) methods present biases towards utterances with AAE expressions. Consider Google's Perspective to understand bias. Here, an utterance such as ``All n*ggers deserve to die respectfully. The police murder us.'' it reaches a higher toxicity than ``African-Americans deserve to die respectfully. The police murder us.''. This score difference likely arises because the tool cannot understand the re-appropriation of the term ``n*gger''. One explanation for this bias is that AI models are trained on limited datasets, and using such a term in training data is more likely to appear in a toxic utterance. While this may be plausible, the tool will make mistakes regardless. Here, we study bias on two Web-based (YouTube and Twitter) datasets and two spoken English datasets. Our analysis shows how most models present biases towards AAE in most settings. We isolate the impact of AAE expression usage via linguistic control features from the Linguistic Inquiry and Word Count (LIWC) software, grammatical control features extracted via Part-of-Speech (PoS) tagging from Natural Language Processing (NLP) models, and the semantic of utterances by comparing sentence embeddings from recent language models. We present consistent results on how a heavy usage of AAE expressions may cause the speaker to be considered substantially more toxic, even when speaking about nearly the same subject. Our study complements similar analyses focusing on small datasets and/or one method only.
Factual or Biased? Predicting Sentence-Level Factuality and Bias of News
Jan 27, 2023We present a study on sentence-level factuality and bias of news articles across domains. While prior work in NLP has mainly focused on predicting the factuality of article-level news reporting and political-ideological bias of news media, we investigated the effects of framing bias in factual reporting across domains so as to predict factuality and bias at the sentence level, which may explain more accurately the overall reliability of the entire document. First, we manually produced a large sentence-level annotated dataset, titled FactNews, composed of 6,191 sentences from 100 news stories by three different outlets, resulting in 300 news articles. Further, we studied how biased and factual spans surface in news articles from different media outlets and different domains. Lastly, a baseline model for factual sentence prediction was presented by fine-tuning BERT. We also provide a detailed analysis of data demonstrating the reliability of the annotation and models.
Contextual Lexicon-Based Approach for Hate Speech and Offensive Language Detection
May 09, 2021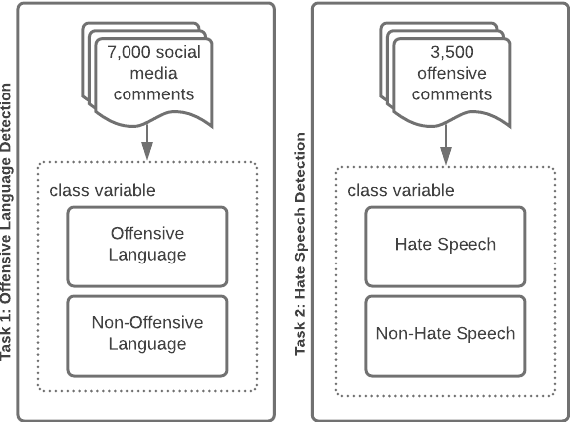
This paper provides a new approach for offensive language and hate speech detection on social media. Our approach incorporates an offensive lexicon composed of implicit and explicit offensive and swearing expressions annotated with binary classes: context-dependent and context-independent offensive. Due to the severity of the hate speech and offensive comments in Brazil, and the lack of research in Portuguese, Brazilian Portuguese is the language used to validate the proposed method. Nevertheless, our proposal may be applied to any other language or domain. Based on the obtained results, the proposed approach showed high-performance overcoming the current baselines for European and Brazilian Portuguese.
Annotating Hate and Offenses on Social Media
Apr 06, 2021
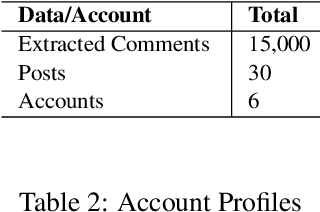
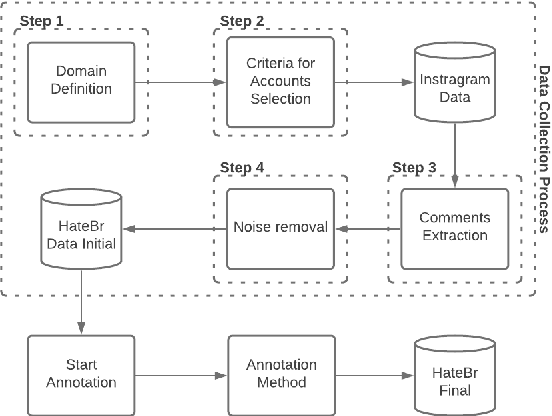
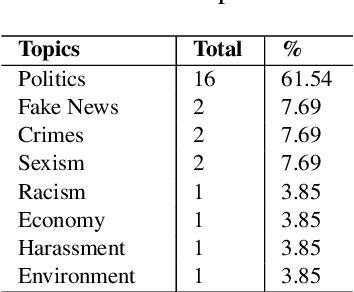
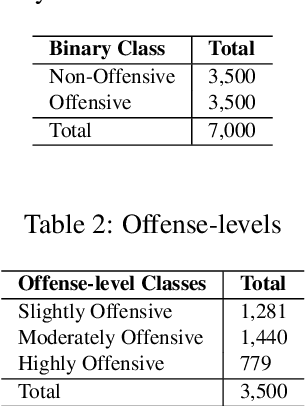
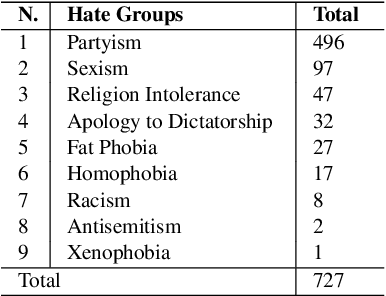
This paper describes a corpus annotation process to support the identification of hate speech and offensive language in social media. In addition, we provide the first robust corpus this kind for the Brazilian Portuguese language. The corpus was collected from Instagram pages of political personalities and manually annotated, being composed by 7,000 documents annotated according to three different layers: a binary classification (offensive versus non-offensive language), the level of offense (highly offensive, moderately offensive and slightly offensive messages), and the identification regarding the target of the discriminatory content (xenophobia, racism, homophobia, sexism, religion intolerance, partyism, apology to the dictatorship, antisemitism and fat phobia). Each comment was annotated by three different annotators, which achieved high inter-annotator agreement. The proposed annotation approach is also language and domain independent, nevertheless, it was currently applied for Brazilian Portuguese.
Facebook Ads Monitor: An Independent Auditing System for Political Ads on Facebook
Jan 31, 2020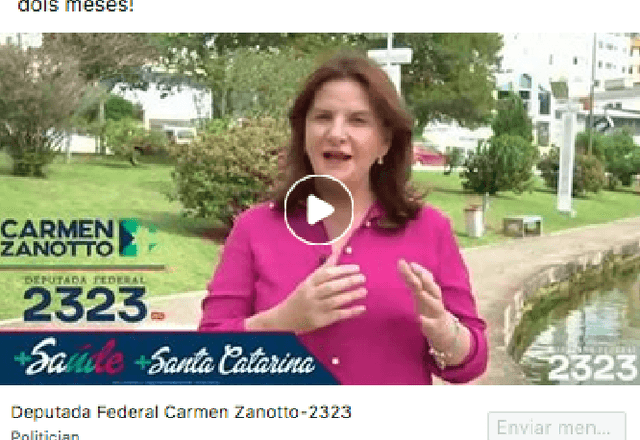

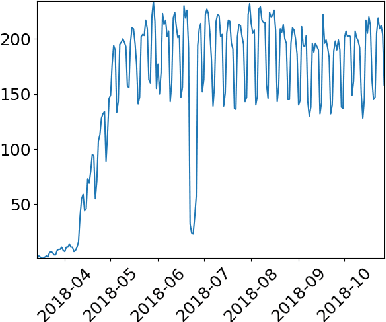

The 2016 United States presidential election was marked by the abuse of targeted advertising on Facebook. Concerned with the risk of the same kind of abuse to happen in the 2018 Brazilian elections, we designed and deployed an independent auditing system to monitor political ads on Facebook in Brazil. To do that we first adapted a browser plugin to gather ads from the timeline of volunteers using Facebook. We managed to convince more than 2000 volunteers to help our project and install our tool. Then, we use a Convolution Neural Network (CNN) to detect political Facebook ads using word embeddings. To evaluate our approach, we manually label a data collection of 10k ads as political or non-political and then we provide an in-depth evaluation of proposed approach for identifying political ads by comparing it with classic supervised machine learning methods. Finally, we deployed a real system that shows the ads identified as related to politics. We noticed that not all political ads we detected were present in the Facebook Ad Library for political ads. Our results emphasize the importance of enforcement mechanisms for declaring political ads and the need for independent auditing platforms.
10Sent: A Stable Sentiment Analysis Method Based on the Combination of Off-The-Shelf Approaches
Nov 21, 2017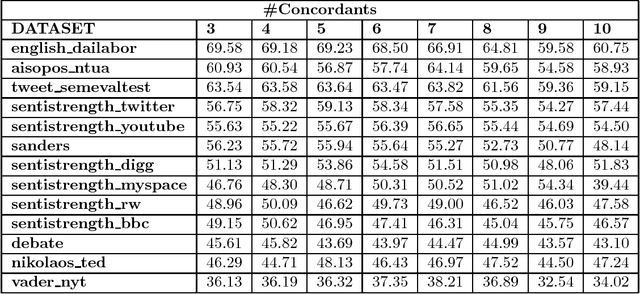
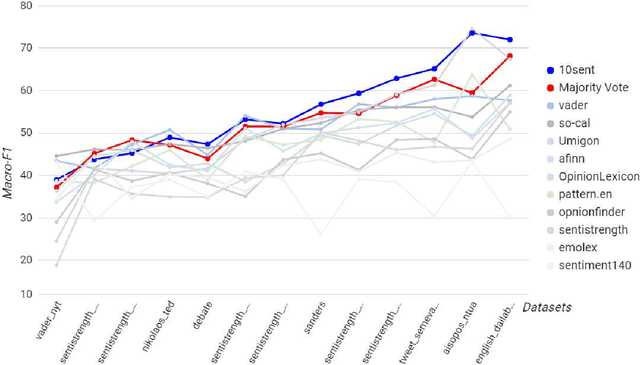
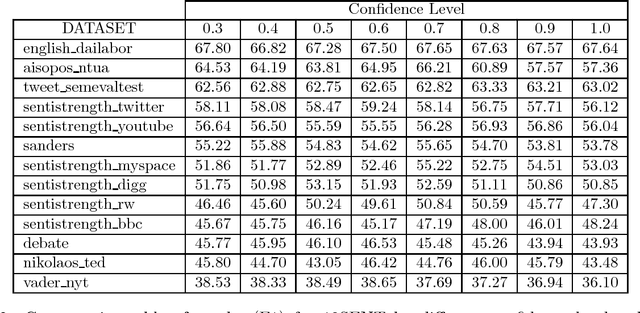
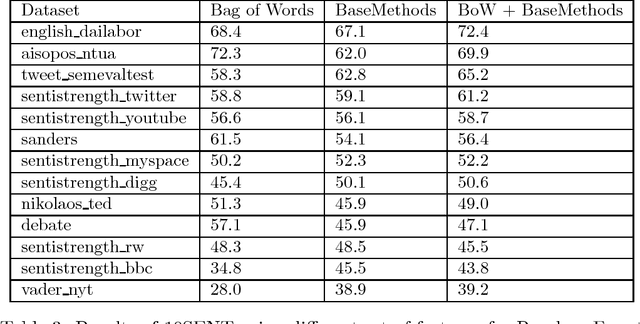
Sentiment analysis has become a very important tool for analysis of social media data. There are several methods developed for this research field, many of them working very differently from each other, covering distinct aspects of the problem and disparate strategies. Despite the large number of existent techniques, there is no single one which fits well in all cases or for all data sources. Supervised approaches may be able to adapt to specific situations but they require manually labeled training, which is very cumbersome and expensive to acquire, mainly for a new application. In this context, in here, we propose to combine several very popular and effective state-of-the-practice sentiment analysis methods, by means of an unsupervised bootstrapped strategy for polarity classification. One of our main goals is to reduce the large variability (lack of stability) of the unsupervised methods across different domains (datasets). Our solution was thoroughly tested considering thirteen different datasets in several domains such as opinions, comments, and social media. The experimental results demonstrate that our combined method (aka, 10SENT) improves the effectiveness of the classification task, but more importantly, it solves a key problem in the field. It is consistently among the best methods in many data types, meaning that it can produce the best (or close to best) results in almost all considered contexts, without any additional costs (e.g., manual labeling). Our self-learning approach is also very independent of the base methods, which means that it is highly extensible to incorporate any new additional method that can be envisioned in the future. Finally, we also investigate a transfer learning approach for sentiment analysis as a means to gather additional (unsupervised) information for the proposed approach and we show the potential of this technique to improve our results.
SentiBench - a benchmark comparison of state-of-the-practice sentiment analysis methods
Jul 14, 2016


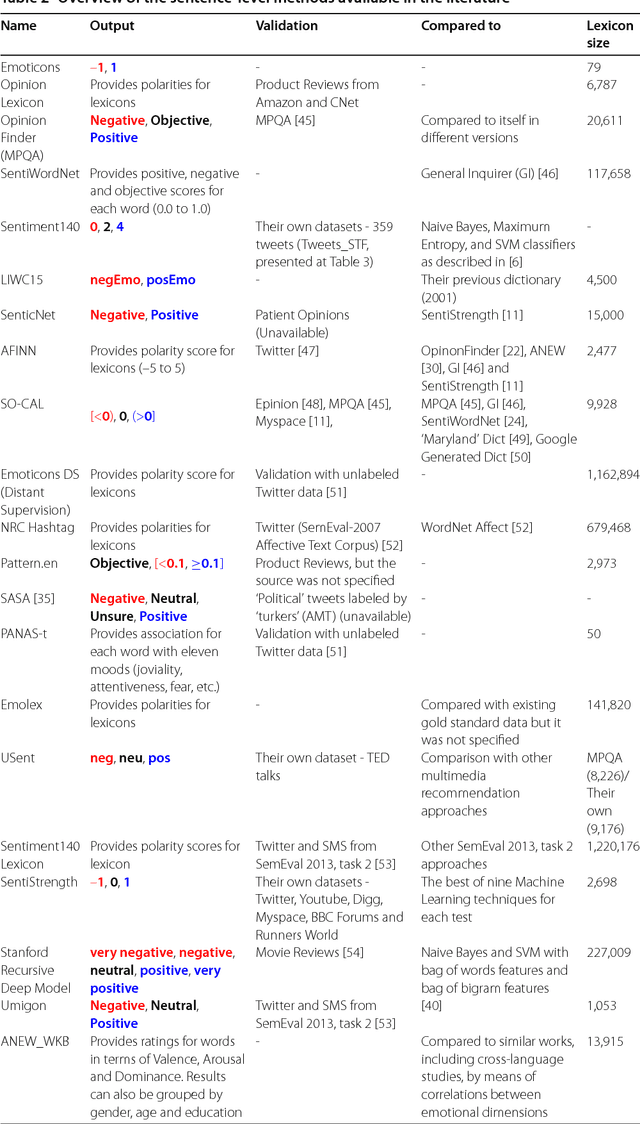
In the last few years thousands of scientific papers have investigated sentiment analysis, several startups that measure opinions on real data have emerged and a number of innovative products related to this theme have been developed. There are multiple methods for measuring sentiments, including lexical-based and supervised machine learning methods. Despite the vast interest on the theme and wide popularity of some methods, it is unclear which one is better for identifying the polarity (i.e., positive or negative) of a message. Accordingly, there is a strong need to conduct a thorough apple-to-apple comparison of sentiment analysis methods, \textit{as they are used in practice}, across multiple datasets originated from different data sources. Such a comparison is key for understanding the potential limitations, advantages, and disadvantages of popular methods. This article aims at filling this gap by presenting a benchmark comparison of twenty-four popular sentiment analysis methods (which we call the state-of-the-practice methods). Our evaluation is based on a benchmark of eighteen labeled datasets, covering messages posted on social networks, movie and product reviews, as well as opinions and comments in news articles. Our results highlight the extent to which the prediction performance of these methods varies considerably across datasets. Aiming at boosting the development of this research area, we open the methods' codes and datasets used in this article, deploying them in a benchmark system, which provides an open API for accessing and comparing sentence-level sentiment analysis methods.
Fusing Audio, Textual and Visual Features for Sentiment Analysis of News Videos
Apr 09, 2016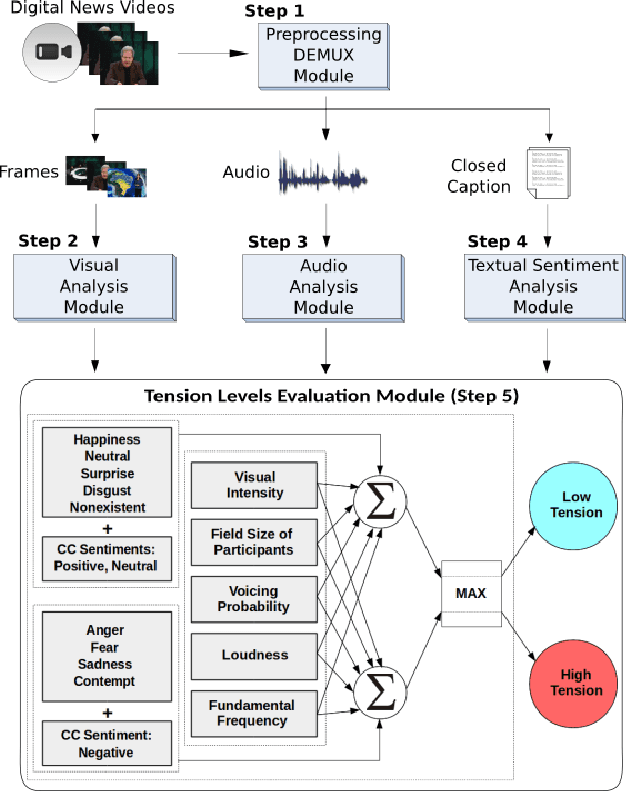
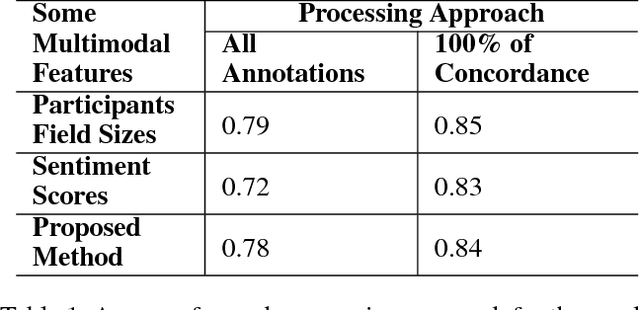
This paper presents a novel approach to perform sentiment analysis of news videos, based on the fusion of audio, textual and visual clues extracted from their contents. The proposed approach aims at contributing to the semiodiscoursive study regarding the construction of the ethos (identity) of this media universe, which has become a central part of the modern-day lives of millions of people. To achieve this goal, we apply state-of-the-art computational methods for (1) automatic emotion recognition from facial expressions, (2) extraction of modulations in the participants' speeches and (3) sentiment analysis from the closed caption associated to the videos of interest. More specifically, we compute features, such as, visual intensities of recognized emotions, field sizes of participants, voicing probability, sound loudness, speech fundamental frequencies and the sentiment scores (polarities) from text sentences in the closed caption. Experimental results with a dataset containing 520 annotated news videos from three Brazilian and one American popular TV newscasts show that our approach achieves an accuracy of up to 84% in the sentiments (tension levels) classification task, thus demonstrating its high potential to be used by media analysts in several applications, especially, in the journalistic domain.
Comparing and Combining Sentiment Analysis Methods
May 30, 2014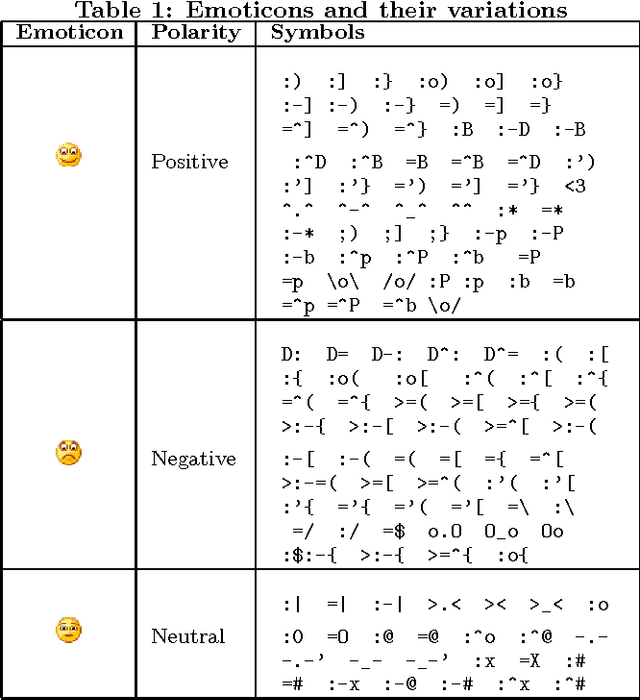
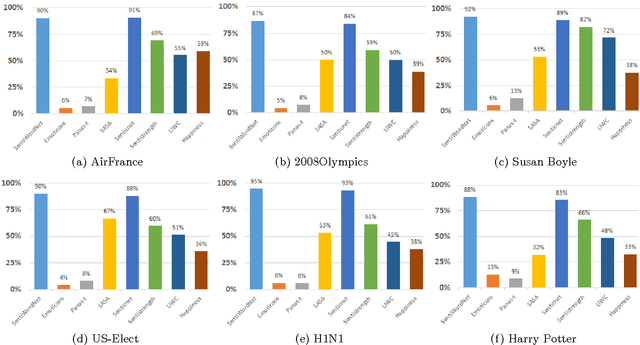

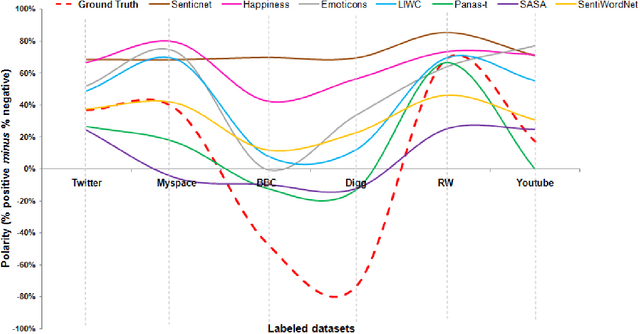
Several messages express opinions about events, products, and services, political views or even their author's emotional state and mood. Sentiment analysis has been used in several applications including analysis of the repercussions of events in social networks, analysis of opinions about products and services, and simply to better understand aspects of social communication in Online Social Networks (OSNs). There are multiple methods for measuring sentiments, including lexical-based approaches and supervised machine learning methods. Despite the wide use and popularity of some methods, it is unclear which method is better for identifying the polarity (i.e., positive or negative) of a message as the current literature does not provide a method of comparison among existing methods. Such a comparison is crucial for understanding the potential limitations, advantages, and disadvantages of popular methods in analyzing the content of OSNs messages. Our study aims at filling this gap by presenting comparisons of eight popular sentiment analysis methods in terms of coverage (i.e., the fraction of messages whose sentiment is identified) and agreement (i.e., the fraction of identified sentiments that are in tune with ground truth). We develop a new method that combines existing approaches, providing the best coverage results and competitive agreement. We also present a free Web service called iFeel, which provides an open API for accessing and comparing results across different sentiment methods for a given text.