 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Lexicon-Based Approach for Hate Speech and Offensive Language Detection
May 09, 2021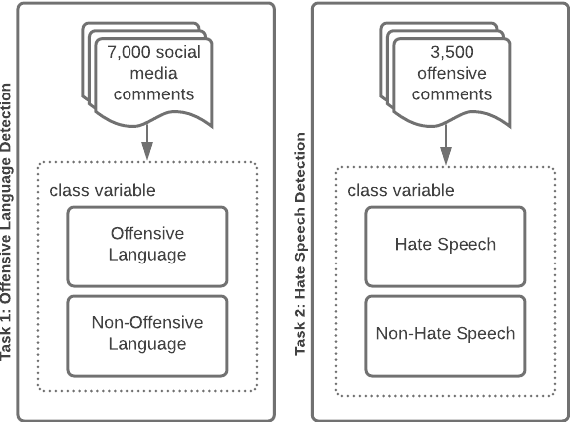
This paper provides a new approach for offensive language and hate speech detection on social media. Our approach incorporates an offensive lexicon composed of implicit and explicit offensive and swearing expressions annotated with binary classes: context-dependent and context-independent offensive. Due to the severity of the hate speech and offensive comments in Brazil, and the lack of research in Portuguese, Brazilian Portuguese is the language used to validate the proposed method. Nevertheless, our proposal may be applied to any other language or domain. Based on the obtained results, the proposed approach showed high-performance overcoming the current baselines for European and Brazilian Portuguese.
Identifying Offensive Expressions of Opinion in Context
Apr 27, 2021


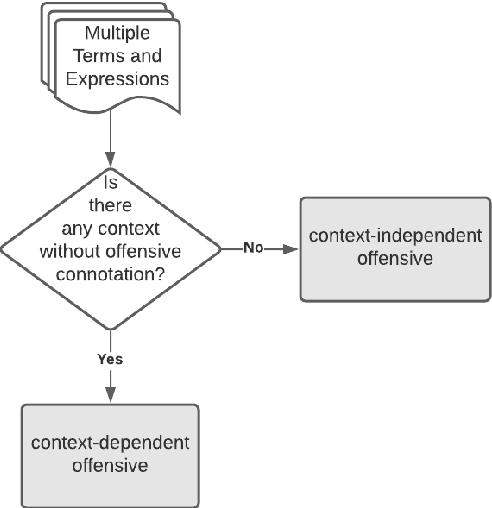
Classic information extraction techniques consist in building questions and answers about the facts. Indeed, it is still a challenge to subjective information extraction systems to identify opinions and feelings in context. In sentiment-based NLP tasks, there are few resources to information extraction, above all offensive or hateful opinions in context. To fill this important gap, this short paper provides a new cross-lingual and contextual offensive lexicon, which consists of explicit and implicit offensive and swearing expressions of opinion, which were annotated in two different classes: context dependent and context-independent offensive. In addition, we provide markers to identify hate speech. Annotation approach was evaluated at the expression-level and achieves high human inter-annotator agreement. The provided offensive lexicon is available in Portuguese and English languages.
Annotating Hate and Offenses on Social Media
Apr 06, 2021
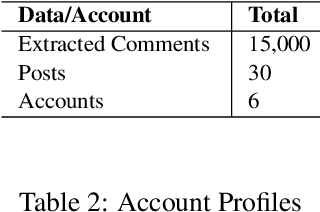
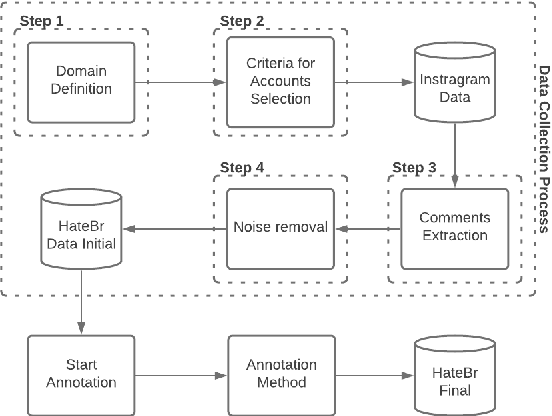
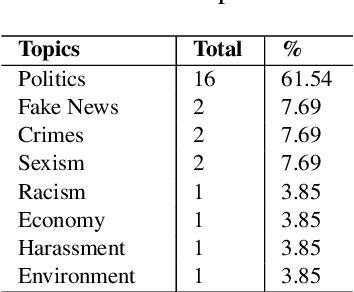
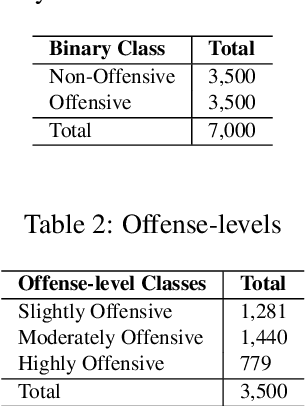
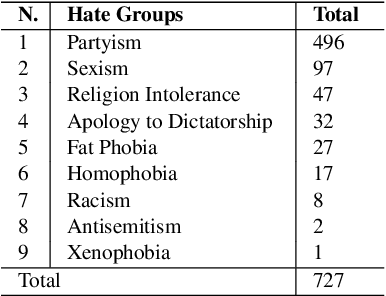
This paper describes a corpus annotation process to support the identification of hate speech and offensive language in social media. In addition, we provide the first robust corpus this kind for the Brazilian Portuguese language. The corpus was collected from Instagram pages of political personalities and manually annotated, being composed by 7,000 documents annotated according to three different layers: a binary classification (offensive versus non-offensive language), the level of offense (highly offensive, moderately offensive and slightly offensive messages), and the identification regarding the target of the discriminatory content (xenophobia, racism, homophobia, sexism, religion intolerance, partyism, apology to the dictatorship, antisemitism and fat phobia). Each comment was annotated by three different annotators, which achieved high inter-annotator agreement. The proposed annotation approach is also language and domain independent, nevertheless, it was currently applied for Brazilian Portuguese.
Studying Dishonest Intentions in Brazilian Portuguese Texts
Aug 13, 2020
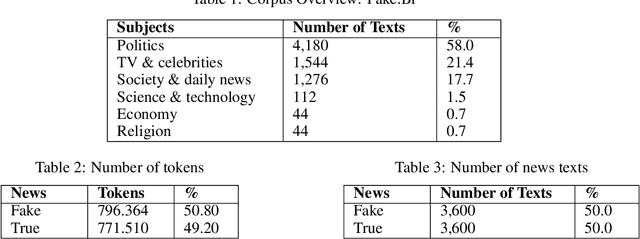


Previous work in the social sciences, psychology and linguistics has show that liars have some control over the content of their stories, however their underlying state of mind may "leak out" through the way that they tell them. To the best of our knowledge, no previous systematic effort exists in order to describe and model deception language for Brazilian Portuguese. To fill this important gap, we carry out an initial empirical linguistic study on false statements in Brazilian news. We methodically analyze linguistic features using the Fake.Br corpus, which includes both fake and true news. The results show that they present substantial lexical, syntactic and semantic variations, as well as punctuation and emotion distinctions.