 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge10Sent: A Stable Sentiment Analysis Method Based on the Combination of Off-The-Shelf Approaches
Nov 21, 2017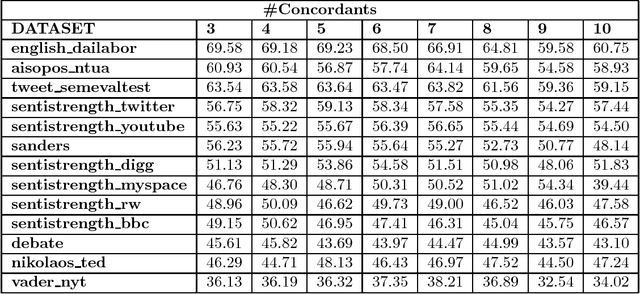
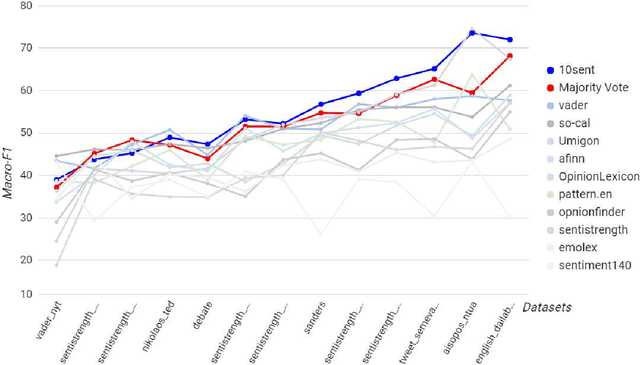
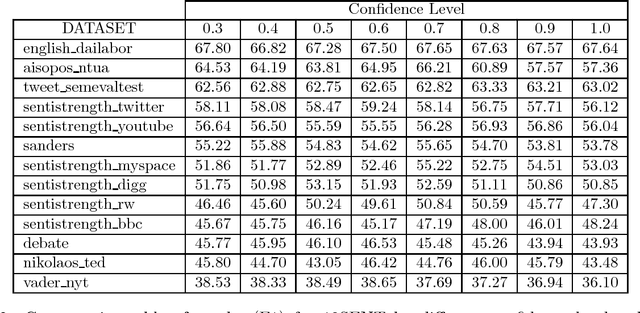
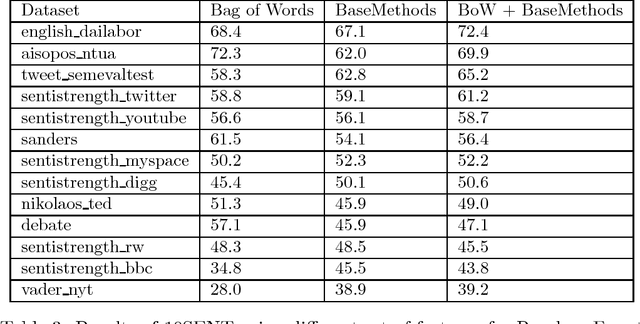
Sentiment analysis has become a very important tool for analysis of social media data. There are several methods developed for this research field, many of them working very differently from each other, covering distinct aspects of the problem and disparate strategies. Despite the large number of existent techniques, there is no single one which fits well in all cases or for all data sources. Supervised approaches may be able to adapt to specific situations but they require manually labeled training, which is very cumbersome and expensive to acquire, mainly for a new application. In this context, in here, we propose to combine several very popular and effective state-of-the-practice sentiment analysis methods, by means of an unsupervised bootstrapped strategy for polarity classification. One of our main goals is to reduce the large variability (lack of stability) of the unsupervised methods across different domains (datasets). Our solution was thoroughly tested considering thirteen different datasets in several domains such as opinions, comments, and social media. The experimental results demonstrate that our combined method (aka, 10SENT) improves the effectiveness of the classification task, but more importantly, it solves a key problem in the field. It is consistently among the best methods in many data types, meaning that it can produce the best (or close to best) results in almost all considered contexts, without any additional costs (e.g., manual labeling). Our self-learning approach is also very independent of the base methods, which means that it is highly extensible to incorporate any new additional method that can be envisioned in the future. Finally, we also investigate a transfer learning approach for sentiment analysis as a means to gather additional (unsupervised) information for the proposed approach and we show the potential of this technique to improve our results.
Fusing Audio, Textual and Visual Features for Sentiment Analysis of News Videos
Apr 09, 2016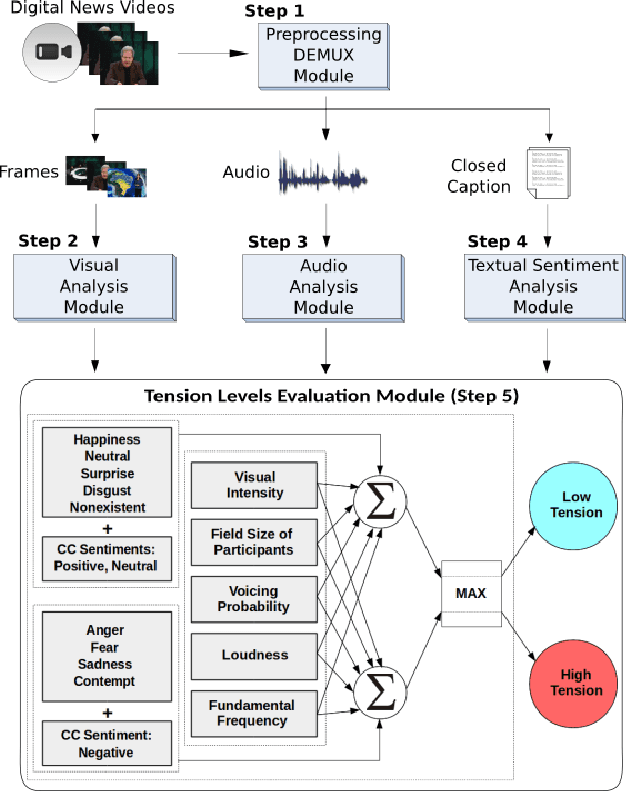
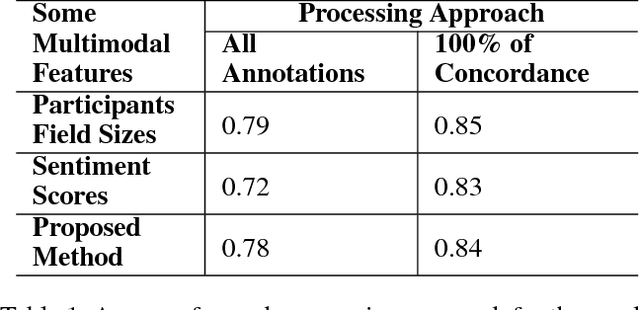
This paper presents a novel approach to perform sentiment analysis of news videos, based on the fusion of audio, textual and visual clues extracted from their contents. The proposed approach aims at contributing to the semiodiscoursive study regarding the construction of the ethos (identity) of this media universe, which has become a central part of the modern-day lives of millions of people. To achieve this goal, we apply state-of-the-art computational methods for (1) automatic emotion recognition from facial expressions, (2) extraction of modulations in the participants' speeches and (3) sentiment analysis from the closed caption associated to the videos of interest. More specifically, we compute features, such as, visual intensities of recognized emotions, field sizes of participants, voicing probability, sound loudness, speech fundamental frequencies and the sentiment scores (polarities) from text sentences in the closed caption. Experimental results with a dataset containing 520 annotated news videos from three Brazilian and one American popular TV newscasts show that our approach achieves an accuracy of up to 84% in the sentiments (tension levels) classification task, thus demonstrating its high potential to be used by media analysts in several applications, especially, in the journalistic domain.