 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusing Audio, Textual and Visual Features for Sentiment Analysis of News Videos
Paper and Code
Apr 09, 2016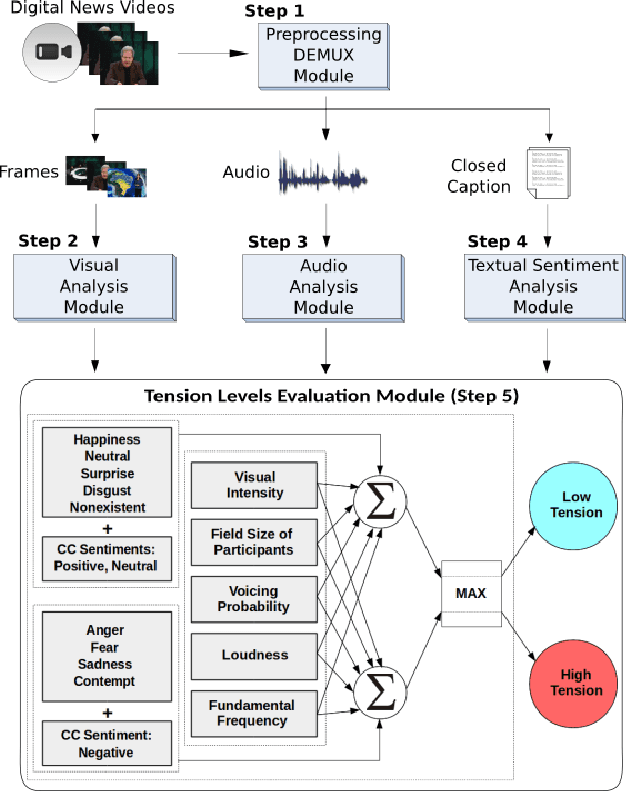
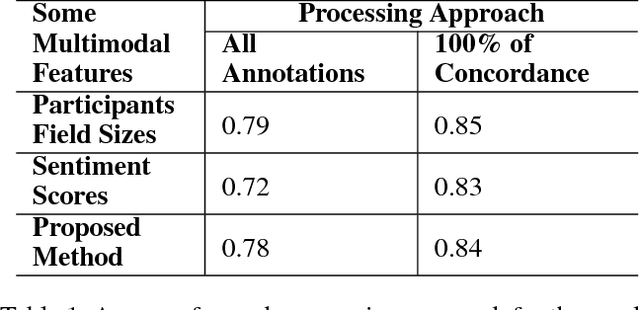
This paper presents a novel approach to perform sentiment analysis of news videos, based on the fusion of audio, textual and visual clues extracted from their contents. The proposed approach aims at contributing to the semiodiscoursive study regarding the construction of the ethos (identity) of this media universe, which has become a central part of the modern-day lives of millions of people. To achieve this goal, we apply state-of-the-art computational methods for (1) automatic emotion recognition from facial expressions, (2) extraction of modulations in the participants' speeches and (3) sentiment analysis from the closed caption associated to the videos of interest. More specifically, we compute features, such as, visual intensities of recognized emotions, field sizes of participants, voicing probability, sound loudness, speech fundamental frequencies and the sentiment scores (polarities) from text sentences in the closed caption. Experimental results with a dataset containing 520 annotated news videos from three Brazilian and one American popular TV newscasts show that our approach achieves an accuracy of up to 84% in the sentiments (tension levels) classification task, thus demonstrating its high potential to be used by media analysts in several applications, especially, in the journalistic domain.