 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurprising Patterns in Musical Influence Networks
Oct 21, 2024Analyzing musical influence networks, such as those formed by artist influence or sampling, has provided valuable insights into contemporary Western music. Here, computational methods like centrality rankings help identify influential artists. However, little attention has been given to how influence changes over time. In this paper, we apply Bayesian Surprise to track the evolution of musical influence networks. Using two networks -- one of artist influence and another of covers, remixes, and samples -- our results reveal significant periods of change in network structure. Additionally, we demonstrate that Bayesian Surprise is a flexible framework for testing various hypotheses on network evolution with real-world data.
Do we need more complex representations for structure? A comparison of note duration representation for Music Transformers
Oct 14, 2024



In recent years, deep learning has achieved formidable results in creative computing. When it comes to music, one viable model for music generation are Transformer based models. However, while transformers models are popular for music generation, they often rely on annotated structural information. In this work, we inquire if the off-the-shelf Music Transformer models perform just as well on structural similarity metrics using only unannotated MIDI information. We show that a slight tweak to the most common representation yields small but significant improvements. We also advocate that searching for better unannotated musical representations is more cost-effective than producing large amounts of curated and annotated data.
A Comprehensive View of the Biases of Toxicity and Sentiment Analysis Methods Towards Utterances with African American English Expressions
Jan 23, 2024Language is a dynamic aspect of our culture that changes when expressed in different technologies/communities. Online social networks have enabled the diffusion and evolution of different dialects, including African American English (AAE). However, this increased usage is not without barriers. One particular barrier is how sentiment (Vader, TextBlob, and Flair) and toxicity (Google's Perspective and the open-source Detoxify) methods present biases towards utterances with AAE expressions. Consider Google's Perspective to understand bias. Here, an utterance such as ``All n*ggers deserve to die respectfully. The police murder us.'' it reaches a higher toxicity than ``African-Americans deserve to die respectfully. The police murder us.''. This score difference likely arises because the tool cannot understand the re-appropriation of the term ``n*gger''. One explanation for this bias is that AI models are trained on limited datasets, and using such a term in training data is more likely to appear in a toxic utterance. While this may be plausible, the tool will make mistakes regardless. Here, we study bias on two Web-based (YouTube and Twitter) datasets and two spoken English datasets. Our analysis shows how most models present biases towards AAE in most settings. We isolate the impact of AAE expression usage via linguistic control features from the Linguistic Inquiry and Word Count (LIWC) software, grammatical control features extracted via Part-of-Speech (PoS) tagging from Natural Language Processing (NLP) models, and the semantic of utterances by comparing sentence embeddings from recent language models. We present consistent results on how a heavy usage of AAE expressions may cause the speaker to be considered substantially more toxic, even when speaking about nearly the same subject. Our study complements similar analyses focusing on small datasets and/or one method only.
Differential 2D Copula Approximating Transforms via Sobolev Training: 2-Cats Networks
Sep 28, 2023Copulas are a powerful statistical tool that captures dependencies across data dimensions. When applying Copulas, we can estimate multivariate distribution functions by initially estimating independent marginals, an easy task, and then a single copulating function, $C$, to connect the marginals, a hard task. For two-dimensional data, a copula is a two-increasing function of the form $C: (u,v)\in \mathbf{I}^2 \rightarrow \mathbf{I}$, where $\mathbf{I} = [0, 1]$. In this paper, we show how Neural Networks (NNs) can approximate any two-dimensional copula non-parametrically. Our approach, denoted as 2-Cats, is inspired by the Physics-Informed Neural Networks and Sobolev Training literature. Not only do we show that we can estimate the output of a 2d Copula better than the state-of-the-art, our approach is non-parametric and respects the mathematical properties of a Copula $C$.
Initial Results for Pairwise Causal Discovery Using Quantitative Information Flow
Dec 02, 2022

Pairwise Causal Discovery is the task of determining causal, anticausal, confounded or independence relationships from pairs of variables. Over the last few years, this challenging task has promoted not only the discovery of novel machine learning models aimed at solving the task, but also discussions on how learning the causal direction of variables may benefit machine learning overall. In this paper, we show that Quantitative Information Flow (QIF), a measure usually employed for measuring leakages of information from a system to an attacker, shows promising results as features for the task. In particular, experiments with real-world datasets indicate that QIF is statistically tied to the state of the art. Our initial results motivate further inquiries on how QIF relates to causality and what are its limitations.
Fast Estimation of Causal Interactions using Wold Processes
Jul 12, 2018
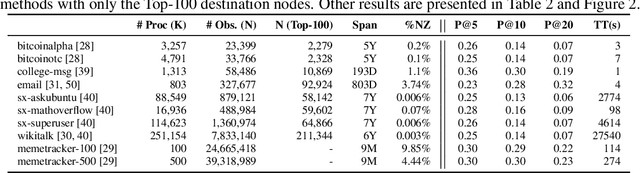

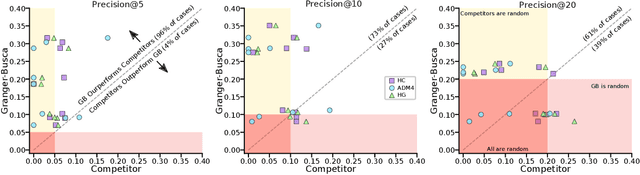
We here focus on the task of learning Granger causality matrices for multivariate point processes. In order to accomplish this task, our work is the first to explore the use of Wold processes. By doing so, we are able to develop asymptotically fast MCMC learning algorithms. With $N$ being the total number of events and $K$ the number of processes, our learning algorithm has a $O(N(\,\log(N)\,+\,\log(K)))$ cost per iteration. This is much faster than the $O(N^3\,K^2)$ or $O(K^3)$ for the state of the art. Our approach, called GrangerBusca, is validated on nine datasets from the Snap repository. This is an advance in relation to most prior efforts which focus mostly on subsets of the Memetracker dataset. Regarding accuracy, GrangerBusca is three times more accurate (in Precision@10) than the state of the art for the commonly explored subsets of the Memetracker data. Due to GrangerBusca's much lower training complexity, our approach is the only one able to train models for larger, full, sets of data.
TribeFlow: Mining & Predicting User Trajectories
Feb 19, 2016

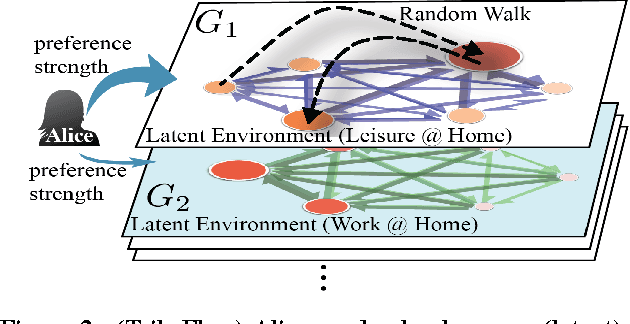
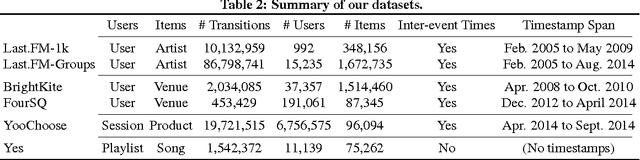
Which song will Smith listen to next? Which restaurant will Alice go to tomorrow? Which product will John click next? These applications have in common the prediction of user trajectories that are in a constant state of flux over a hidden network (e.g. website links, geographic location). What users are doing now may be unrelated to what they will be doing in an hour from now. Mindful of these challenges we propose TribeFlow, a method designed to cope with the complex challenges of learning personalized predictive models of non-stationary, transient, and time-heterogeneous user trajectories. TribeFlow is a general method that can perform next product recommendation, next song recommendation, next location prediction, and general arbitrary-length user trajectory prediction without domain-specific knowledge. TribeFlow is more accurate and up to 413x faster than top competitors.