 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo we need more complex representations for structure? A comparison of note duration representation for Music Transformers
Oct 14, 2024



In recent years, deep learning has achieved formidable results in creative computing. When it comes to music, one viable model for music generation are Transformer based models. However, while transformers models are popular for music generation, they often rely on annotated structural information. In this work, we inquire if the off-the-shelf Music Transformer models perform just as well on structural similarity metrics using only unannotated MIDI information. We show that a slight tweak to the most common representation yields small but significant improvements. We also advocate that searching for better unannotated musical representations is more cost-effective than producing large amounts of curated and annotated data.
A Comprehensive Review and Taxonomy of Audio-Visual Synchronization Techniques for Realistic Speech Animation
Jul 24, 2024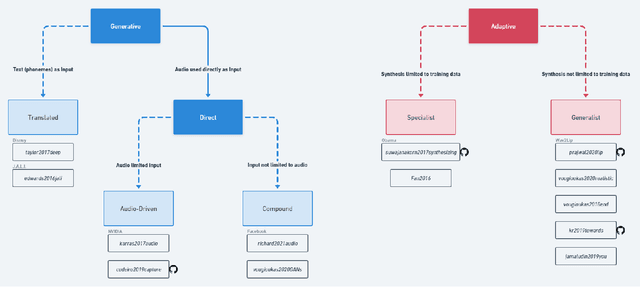
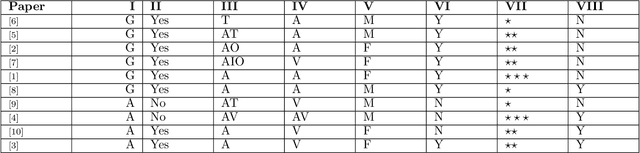
In many applications, synchronizing audio with visuals is crucial, such as in creating graphic animations for films or games, translating movie audio into different languages, and developing metaverse applications. This review explores various methodologies for achieving realistic facial animations from audio inputs, highlighting generative and adaptive models. Addressing challenges like model training costs, dataset availability, and silent moment distributions in audio data, it presents innovative solutions to enhance performance and realism. The research also introduces a new taxonomy to categorize audio-visual synchronization methods based on logistical aspects, advancing the capabilities of virtual assistants, gaming, and interactive digital media.