 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Review and Taxonomy of Audio-Visual Synchronization Techniques for Realistic Speech Animation
Jul 24, 2024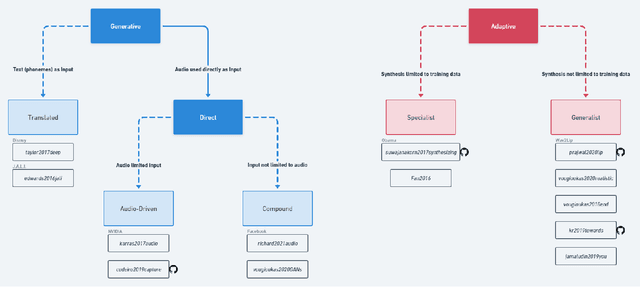
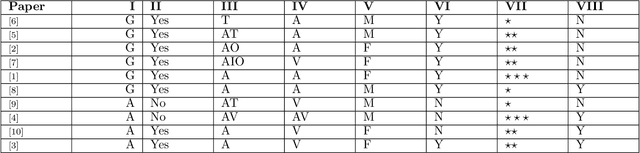
In many applications, synchronizing audio with visuals is crucial, such as in creating graphic animations for films or games, translating movie audio into different languages, and developing metaverse applications. This review explores various methodologies for achieving realistic facial animations from audio inputs, highlighting generative and adaptive models. Addressing challenges like model training costs, dataset availability, and silent moment distributions in audio data, it presents innovative solutions to enhance performance and realism. The research also introduces a new taxonomy to categorize audio-visual synchronization methods based on logistical aspects, advancing the capabilities of virtual assistants, gaming, and interactive digital media.