 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning framework for LoRaWAN-enabled IIoT communication: A case study
Oct 15, 2024



The development of intelligent Industrial Internet of Things (IIoT) systems promises to revolutionize operational and maintenance practices, driving improvements in operational efficiency. Anomaly detection within IIoT architectures plays a crucial role in preventive maintenance and spotting irregularities in industrial components. However, due to limited message and processing capacity, traditional Machine Learning (ML) faces challenges in deploying anomaly detection models in resource-constrained environments like LoRaWAN. On the other hand, Federated Learning (FL) solves this problem by enabling distributed model training, addressing privacy concerns, and minimizing data transmission. This study explores using FL for anomaly detection in industrial and civil construction machinery architectures that use IIoT prototypes with LoRaWAN communication. The process leverages an optimized autoencoder neural network structure and compares federated models with centralized ones. Despite uneven data distribution among machine clients, FL demonstrates effectiveness, with a mean F1 score (of 94.77), accuracy (of 92.30), TNR (of 90.65), and TPR (92.93), comparable to centralized models, considering airtime of trainning messages of 52.8 min. Local model evaluations on each machine highlight adaptability. At the same time, the performed analysis identifies message requirements, minimum training hours, and optimal round/epoch configurations for FL in LoRaWAN, guiding future implementations in constrained industrial environments.
Fast Estimation of Causal Interactions using Wold Processes
Jul 12, 2018
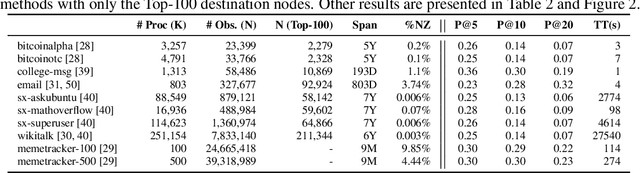

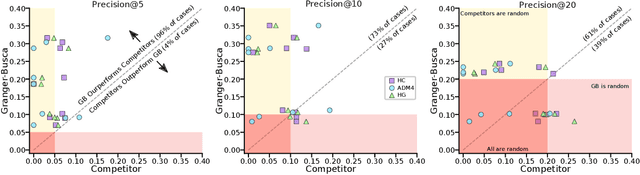
We here focus on the task of learning Granger causality matrices for multivariate point processes. In order to accomplish this task, our work is the first to explore the use of Wold processes. By doing so, we are able to develop asymptotically fast MCMC learning algorithms. With $N$ being the total number of events and $K$ the number of processes, our learning algorithm has a $O(N(\,\log(N)\,+\,\log(K)))$ cost per iteration. This is much faster than the $O(N^3\,K^2)$ or $O(K^3)$ for the state of the art. Our approach, called GrangerBusca, is validated on nine datasets from the Snap repository. This is an advance in relation to most prior efforts which focus mostly on subsets of the Memetracker dataset. Regarding accuracy, GrangerBusca is three times more accurate (in Precision@10) than the state of the art for the commonly explored subsets of the Memetracker data. Due to GrangerBusca's much lower training complexity, our approach is the only one able to train models for larger, full, sets of data.