 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction-Free, Real-Time Flexible Control of Tidal Lagoons through Proximal Policy Optimisation: A Case Study for the Swansea Lagoon
Jul 16, 2021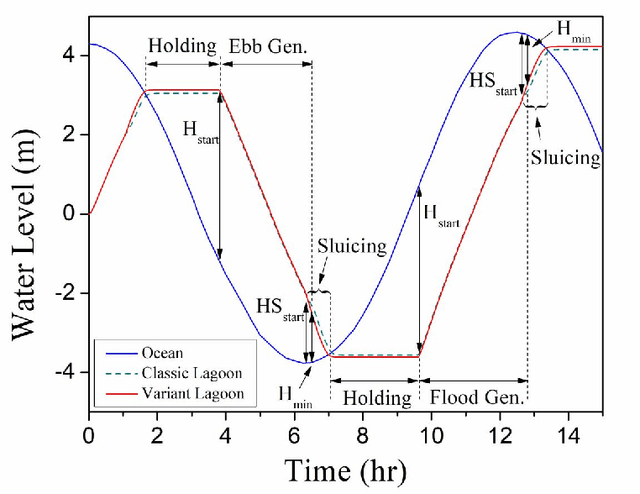


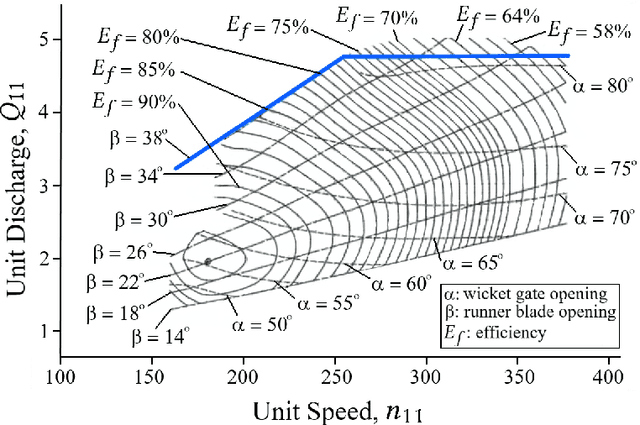
Tidal range structures have been considered for large scale electricity generation for their potential ability to produce reasonable predictable energy without the emission of greenhouse gases. Once the main forcing components for driving the tides have deterministic dynamics, the available energy in a given tidal power plant has been estimated, through analytical and numerical optimisation routines, as a mostly predictable event. This constraint imposes state-of-art flexible operation methods to rely on tidal predictions (concurrent with measured data and up to a multiple of half-tidal cycles into the future) to infer best operational strategies for tidal lagoons, with the additional cost of requiring to run optimisation routines for every new tide. In this paper, we propose a novel optimised operation of tidal lagoons with proximal policy optimisation through Unity ML-Agents. We compare this technique with 6 different operation optimisation approaches (baselines) devised from the literature, utilising the Swansea Bay Tidal Lagoon as a case study. We show that our approach is successful in maximising energy generation through an optimised operational policy of turbines and sluices, yielding competitive results with state-of-the-art methods of optimisation, regardless of test data used, requiring training once and performing real-time flexible control with measured ocean data only.
Overcoming Bias in Community Detection Evaluation
Feb 06, 2021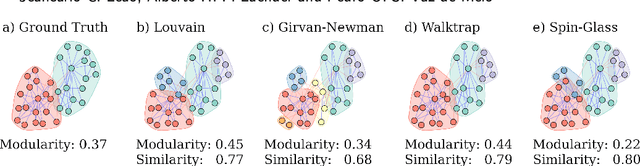
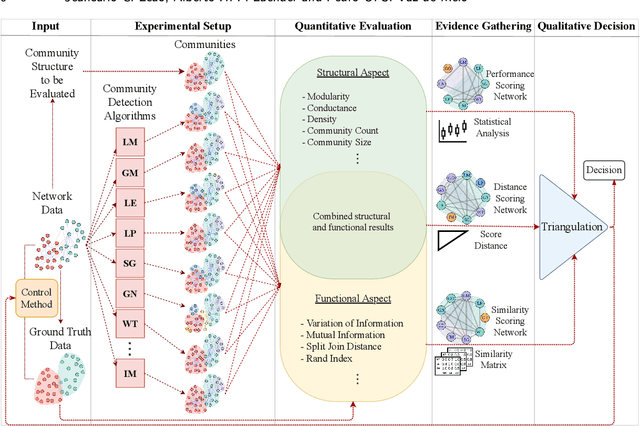
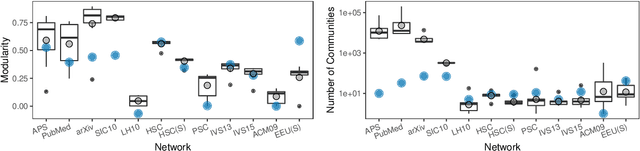
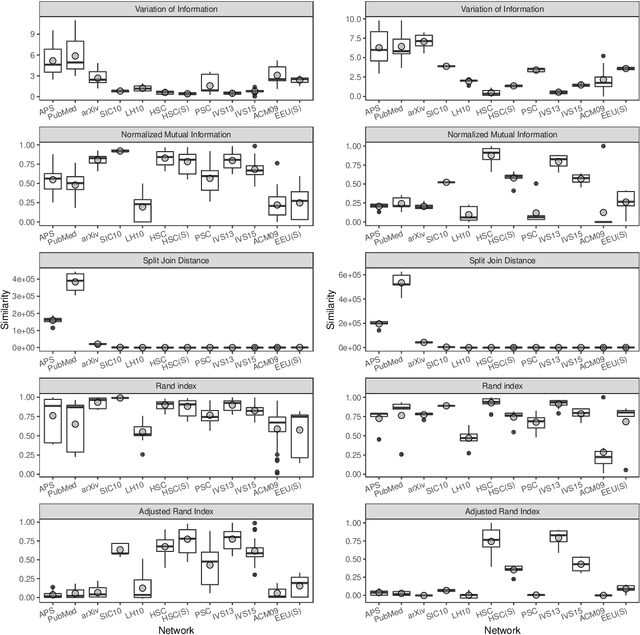
Community detection is a key task to further understand the function and the structure of complex networks. Therefore, a strategy used to assess this task must be able to avoid biased and incorrect results that might invalidate further analyses or applications that rely on such communities. Two widely used strategies to assess this task are generally known as structural and functional. The structural strategy basically consists in detecting and assessing such communities by using multiple methods and structural metrics. On the other hand, the functional strategy might be used when ground truth data are available to assess the detected communities. However, the evaluation of communities based on such strategies is usually done in experimental configurations that are largely susceptible to biases, a situation that is inherent to algorithms, metrics and network data used in this task. Furthermore, such strategies are not systematically combined in a way that allows for the identification and mitigation of bias in the algorithms, metrics or network data to converge into more consistent results. In this context, the main contribution of this article is an approach that supports a robust quality evaluation when detecting communities in real-world networks. In our approach, we measure the quality of a community by applying the structural and functional strategies, and the combination of both, to obtain different pieces of evidence. Then, we consider the divergences and the consensus among the pieces of evidence to identify and overcome possible sources of bias in community detection algorithms, evaluation metrics, and network data. Experiments conducted with several real and synthetic networks provided results that show the effectiveness of our approach to obtain more consistent conclusions about the quality of the detected communities.
A Multi-Strategy Approach to Overcoming Bias in Community Detection Evaluation
Sep 21, 2019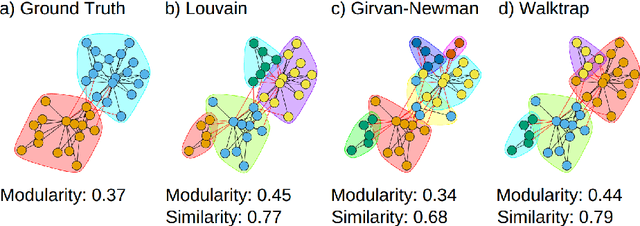

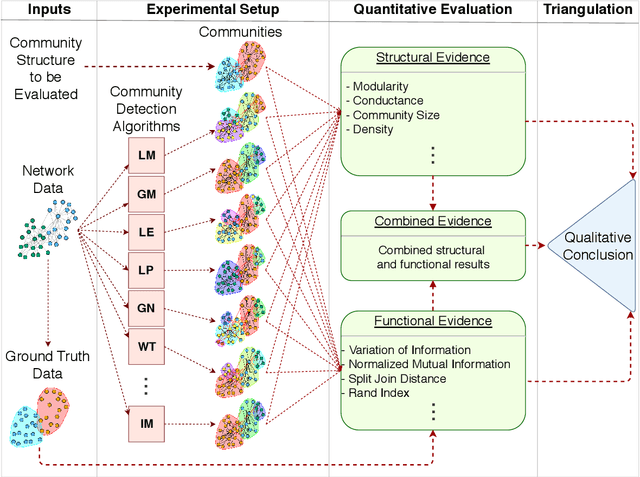
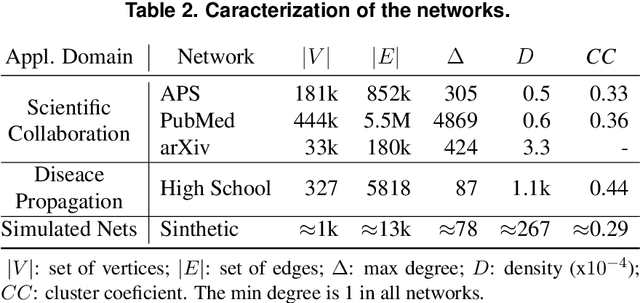
Community detection is key to understand the structure of complex networks. However, the lack of appropriate evaluation strategies for this specific task may produce biased and incorrect results that might invalidate further analyses or applications based on such networks. In this context, the main contribution of this paper is an approach that supports a robust quality evaluation when detecting communities in real-world networks. In our approach, we use multiple strategies that capture distinct aspects of the communities. The conclusion on the quality of these communities is based on the consensus among the strategies adopted for the structural evaluation, as well as on the comparison with communities detected by different methods and with their existing ground truths. In this way, our approach allows one to overcome biases in network data, detection algorithms and evaluation metrics, thus providing more consistent conclusions about the quality of the detected communities. Experiments conducted with several real and synthetic networks provided results that show the effectiveness of our approach.
Fast Estimation of Causal Interactions using Wold Processes
Jul 12, 2018
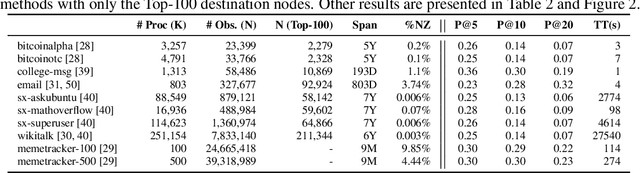

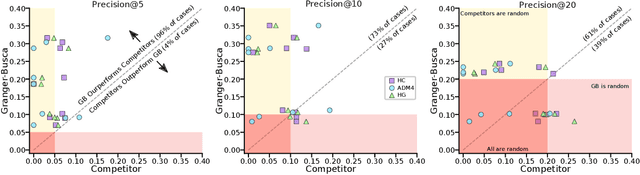
We here focus on the task of learning Granger causality matrices for multivariate point processes. In order to accomplish this task, our work is the first to explore the use of Wold processes. By doing so, we are able to develop asymptotically fast MCMC learning algorithms. With $N$ being the total number of events and $K$ the number of processes, our learning algorithm has a $O(N(\,\log(N)\,+\,\log(K)))$ cost per iteration. This is much faster than the $O(N^3\,K^2)$ or $O(K^3)$ for the state of the art. Our approach, called GrangerBusca, is validated on nine datasets from the Snap repository. This is an advance in relation to most prior efforts which focus mostly on subsets of the Memetracker dataset. Regarding accuracy, GrangerBusca is three times more accurate (in Precision@10) than the state of the art for the commonly explored subsets of the Memetracker data. Due to GrangerBusca's much lower training complexity, our approach is the only one able to train models for larger, full, sets of data.
When Politicians Talk About Politics: Identifying Political Tweets of Brazilian Congressmen
May 04, 2018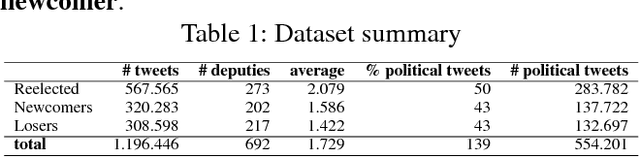
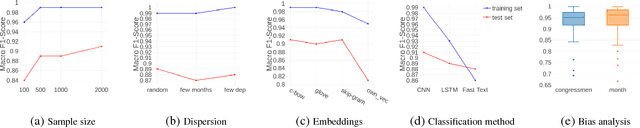

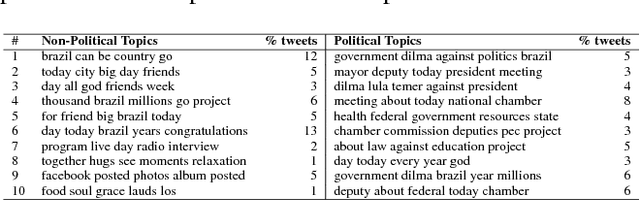
Since June 2013, when Brazil faced the largest and most significant mass protests in a generation, a political crisis is in course. In midst of this crisis, Brazilian politicians use social media to communicate with the electorate in order to retain or to grow their political capital. The problem is that many controversial topics are in course and deputies may prefer to avoid such themes in their messages. To characterize this behavior, we propose a method to accurately identify political and non-political tweets independently of the deputy who posted it and of the time it was posted. Moreover, we collected tweets of all congressmen who were active on Twitter and worked in the Brazilian parliament from October 2013 to October 2017. To evaluate our method, we used word clouds and a topic model to identify the main political and non-political latent topics in parliamentarian tweets. Both results indicate that our proposal is able to accurately distinguish political from non-political tweets. Moreover, our analyses revealed a striking fact: more than half of the messages posted by Brazilian deputies are non-political.
* 4 pages, 7 figures, 2 tables
Breaking the News: First Impressions Matter on Online News
Apr 16, 2015
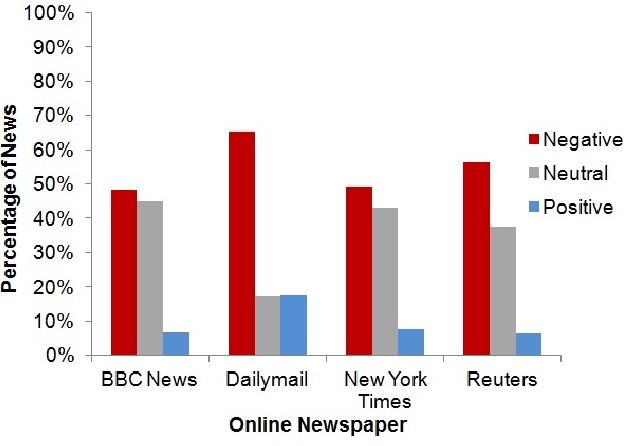

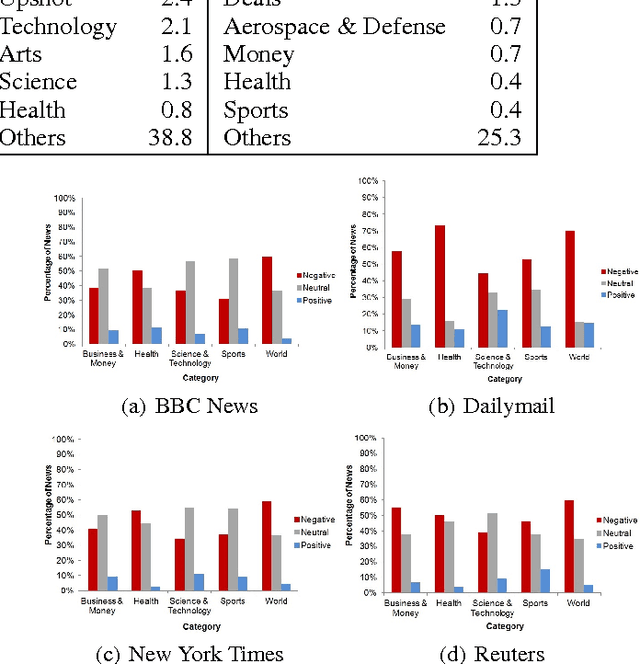
A growing number of people are changing the way they consume news, replacing the traditional physical newspapers and magazines by their virtual online versions or/and weblogs. The interactivity and immediacy present in online news are changing the way news are being produced and exposed by media corporations. News websites have to create effective strategies to catch people's attention and attract their clicks. In this paper we investigate possible strategies used by online news corporations in the design of their news headlines. We analyze the content of 69,907 headlines produced by four major global media corporations during a minimum of eight consecutive months in 2014. In order to discover strategies that could be used to attract clicks, we extracted features from the text of the news headlines related to the sentiment polarity of the headline. We discovered that the sentiment of the headline is strongly related to the popularity of the news and also with the dynamics of the posted comments on that particular news.