 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Machine Unlearning Jeopardizes Privacy
Paper and Code
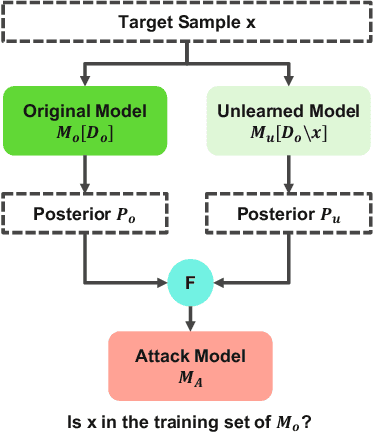
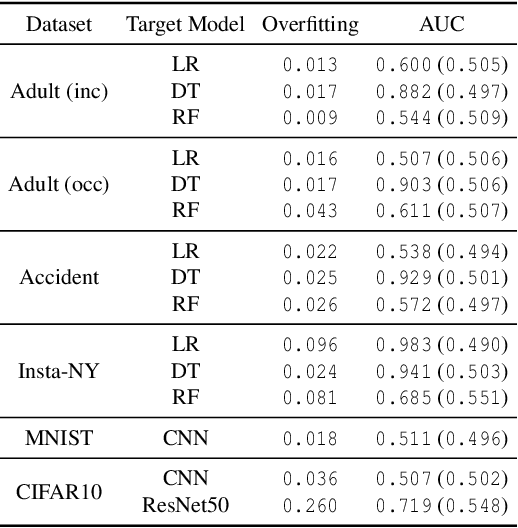
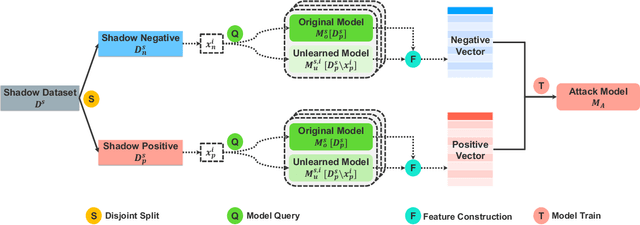

The right to be forgotten states that a data owner has the right to erase her data from an entity storing it. In the context of machine learning (ML), the right to be forgotten requires an ML model owner to remove the data owner's data from the training set used to build the ML model, a process known as machine unlearning. While originally designed to protect the privacy of the data owner, we argue that machine unlearning may leave some imprint of the data in the ML model and thus create unintended privacy risks. In this paper, we perform the first study on investigating the unintended information leakage caused by machine unlearning. We propose a novel membership inference attack which leverages the different outputs of an ML model's two versions to infer whether the deleted sample is part of the training set. Our experiments over five different datasets demonstrate that the proposed membership inference attack achieves strong performance. More importantly, we show that our attack in multiple cases outperforms the classical membership inference attack on the original ML model, which indicates that machine unlearning can have counterproductive effects on privacy. We notice that the privacy degradation is especially significant for well-generalized ML models where classical membership inference does not perform well. We further investigate two mechanisms to mitigate the newly discovered privacy risks and show that the only effective mechanism is to release the predicted label only. We believe that our results can help improve privacy in practical implementation of machine unlearning.