 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDE-FAKE: Detection and Attribution of Fake Images Generated by Text-to-Image Diffusion Models
Paper and Code
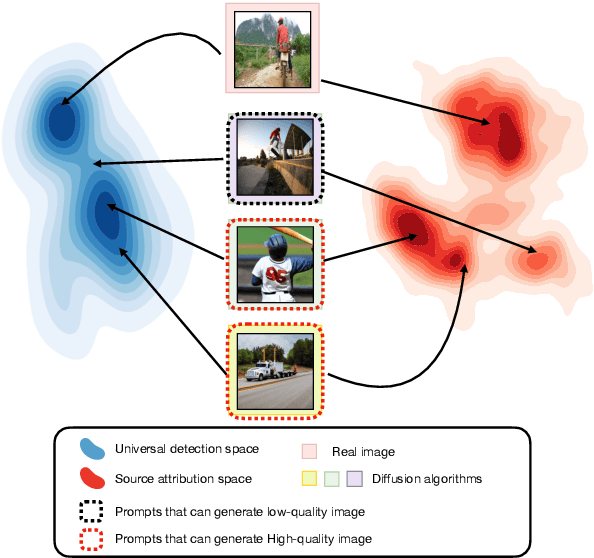
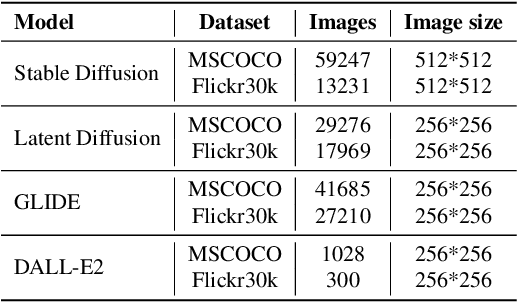
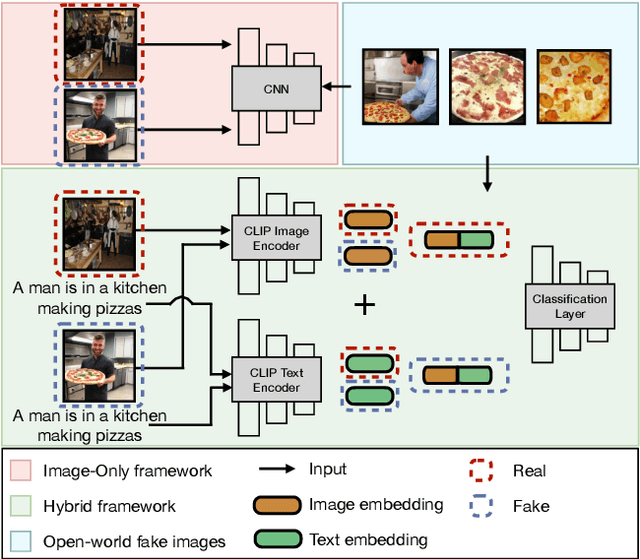
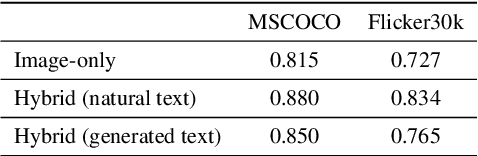
Diffusion models emerge to establish the new state of the art in the visual generation. In particular, text-to-image diffusion models that generate images based on caption descriptions have attracted increasing attention, impressed by their user controllability. Despite encouraging performance, they exaggerate concerns of fake image misuse and cast new pressures on fake image detection. In this work, we pioneer a systematic study of the authenticity of fake images generated by text-to-image diffusion models. In particular, we conduct comprehensive studies from two perspectives unique to the text-to-image model, namely, visual modality and linguistic modality. For visual modality, we propose universal detection that demonstrates fake images of these text-to-image diffusion models share common cues, which enable us to distinguish them apart from real images. We then propose source attribution that reveals the uniqueness of the fingerprints held by each diffusion model, which can be used to attribute each fake image to its model source. A variety of ablation and analysis studies further interpret the improvements from each of our proposed methods. For linguistic modality, we delve deeper to comprehensively analyze the impacts of text captions (called prompt analysis) on the image authenticity of text-to-image diffusion models, and reason the impacts to the detection and attribution performance of fake images. All findings contribute to the community's insight into the natural properties of text-to-image diffusion models, and we appeal to our community's consideration on the counterpart solutions, like ours, against the rapidly-evolving fake image generators.