 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge6DAttack: Backdoor Attacks in the 6DoF Pose Estimation
Dec 22, 2025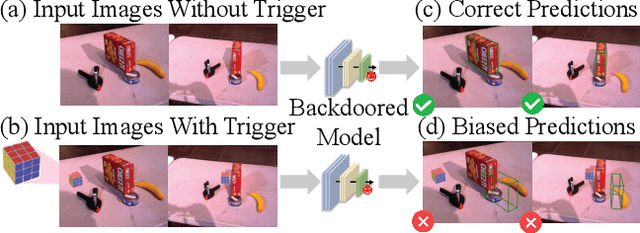
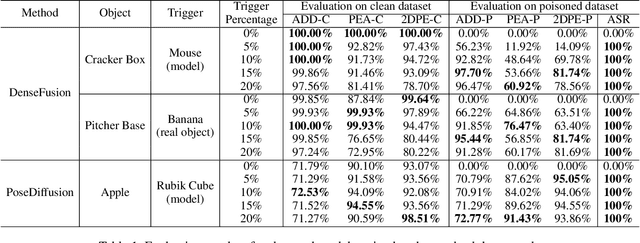
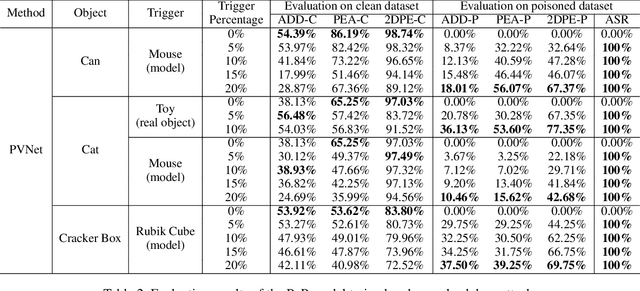
Deep learning advances have enabled accurate six-degree-of-freedom (6DoF) object pose estimation, widely used in robotics, AR/VR, and autonomous systems. However, backdoor attacks pose significant security risks. While most research focuses on 2D vision, 6DoF pose estimation remains largely unexplored. Unlike traditional backdoors that only change classes, 6DoF attacks must control continuous parameters like translation and rotation, rendering 2D methods inapplicable. We propose 6DAttack, a framework using 3D object triggers to induce controlled erroneous poses while maintaining normal behavior. Evaluations on PVNet, DenseFusion, and PoseDiffusion across LINEMOD, YCB-Video, and CO3D show high attack success rates (ASRs) without compromising clean performance. Backdoored models achieve up to 100% clean ADD accuracy and 100% ASR, with triggered samples reaching 97.70% ADD-P. Furthermore, a representative defense remains ineffective. Our findings reveal a serious, underexplored threat to 6DoF pose estimation.
FC-Attack: Jailbreaking Large Vision-Language Models via Auto-Generated Flowcharts
Feb 28, 2025Large Vision-Language Models (LVLMs) have become powerful and widely adopted in some practical applications. However, recent research has revealed their vulnerability to multimodal jailbreak attacks, whereby the model can be induced to generate harmful content, leading to safety risks. Although most LVLMs have undergone safety alignment, recent research shows that the visual modality is still vulnerable to jailbreak attacks. In our work, we discover that by using flowcharts with partially harmful information, LVLMs can be induced to provide additional harmful details. Based on this, we propose a jailbreak attack method based on auto-generated flowcharts, FC-Attack. Specifically, FC-Attack first fine-tunes a pre-trained LLM to create a step-description generator based on benign datasets. The generator is then used to produce step descriptions corresponding to a harmful query, which are transformed into flowcharts in 3 different shapes (vertical, horizontal, and S-shaped) as visual prompts. These flowcharts are then combined with a benign textual prompt to execute a jailbreak attack on LVLMs. Our evaluations using the Advbench dataset show that FC-Attack achieves over 90% attack success rates on Gemini-1.5, Llaval-Next, Qwen2-VL, and InternVL-2.5 models, outperforming existing LVLM jailbreak methods. Additionally, we investigate factors affecting the attack performance, including the number of steps and the font styles in the flowcharts. Our evaluation shows that FC-Attack can improve the jailbreak performance from 4% to 28% in Claude-3.5 by changing the font style. To mitigate the attack, we explore several defenses and find that AdaShield can largely reduce the jailbreak performance but with the cost of utility drop.