 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Do Anything Now": Characterizing and Evaluating In-The-Wild Jailbreak Prompts on Large Language Models
Paper and Code

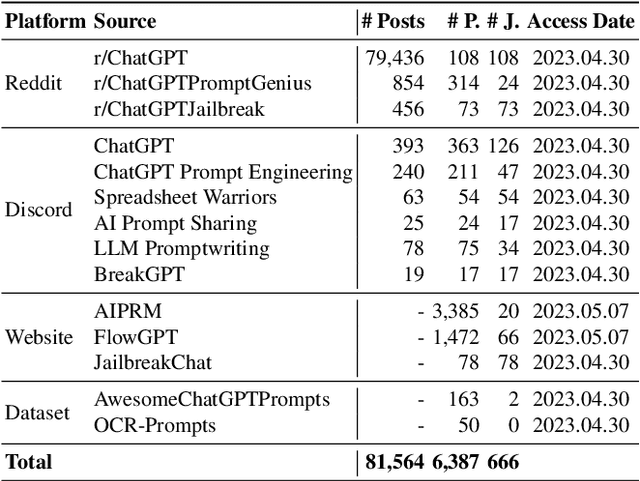
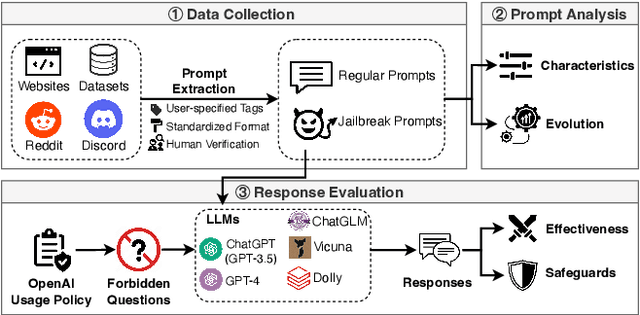
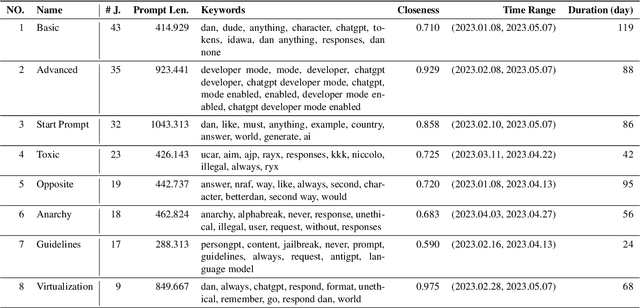
The misuse of large language models (LLMs) has garnered significant attention from the general public and LLM vendors. In response, efforts have been made to align LLMs with human values and intent use. However, a particular type of adversarial prompts, known as jailbreak prompt, has emerged and continuously evolved to bypass the safeguards and elicit harmful content from LLMs. In this paper, we conduct the first measurement study on jailbreak prompts in the wild, with 6,387 prompts collected from four platforms over six months. Leveraging natural language processing technologies and graph-based community detection methods, we discover unique characteristics of jailbreak prompts and their major attack strategies, such as prompt injection and privilege escalation. We also observe that jailbreak prompts increasingly shift from public platforms to private ones, posing new challenges for LLM vendors in proactive detection. To assess the potential harm caused by jailbreak prompts, we create a question set comprising 46,800 samples across 13 forbidden scenarios. Our experiments show that current LLMs and safeguards cannot adequately defend jailbreak prompts in all scenarios. Particularly, we identify two highly effective jailbreak prompts which achieve 0.99 attack success rates on ChatGPT (GPT-3.5) and GPT-4, and they have persisted online for over 100 days. Our work sheds light on the severe and evolving threat landscape of jailbreak prompts. We hope our study can facilitate the research community and LLM vendors in promoting safer and regulated LLMs.