 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn ChatGPT We Trust? Measuring and Characterizing the Reliability of ChatGPT
Paper and Code



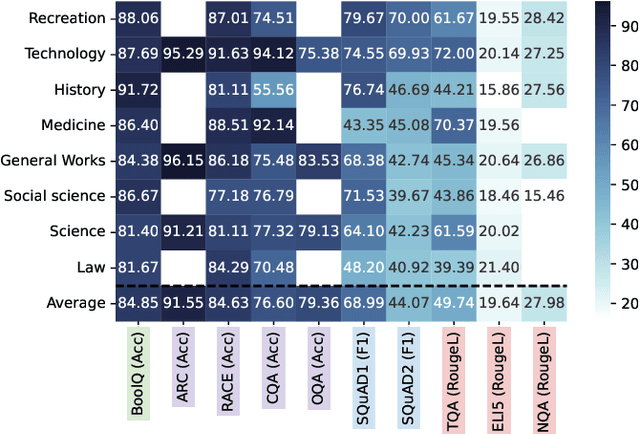
The way users acquire information is undergoing a paradigm shift with the advent of ChatGPT. Unlike conventional search engines, ChatGPT retrieves knowledge from the model itself and generates answers for users. ChatGPT's impressive question-answering (QA) capability has attracted more than 100 million users within a short period of time but has also raised concerns regarding its reliability. In this paper, we perform the first large-scale measurement of ChatGPT's reliability in the generic QA scenario with a carefully curated set of 5,695 questions across ten datasets and eight domains. We find that ChatGPT's reliability varies across different domains, especially underperforming in law and science questions. We also demonstrate that system roles, originally designed by OpenAI to allow users to steer ChatGPT's behavior, can impact ChatGPT's reliability. We further show that ChatGPT is vulnerable to adversarial examples, and even a single character change can negatively affect its reliability in certain cases. We believe that our study provides valuable insights into ChatGPT's reliability and underscores the need for strengthening the reliability and security of large language models (LLMs).