 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralizable Neural Radiance Fields for Novel View Synthesis with Transformer
Paper and Code
Jun 10, 2022

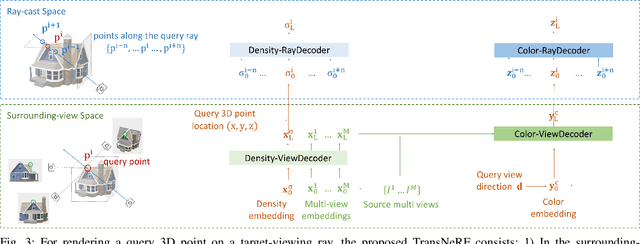

We propose a Transformer-based NeRF (TransNeRF) to learn a generic neural radiance field conditioned on observed-view images for the novel view synthesis task. By contrast, existing MLP-based NeRFs are not able to directly receive observed views with an arbitrary number and require an auxiliary pooling-based operation to fuse source-view information, resulting in the missing of complicated relationships between source views and the target rendering view. Furthermore, current approaches process each 3D point individually and ignore the local consistency of a radiance field scene representation. These limitations potentially can reduce their performance in challenging real-world applications where large differences between source views and a novel rendering view may exist. To address these challenges, our TransNeRF utilizes the attention mechanism to naturally decode deep associations of an arbitrary number of source views into a coordinate-based scene representation. Local consistency of shape and appearance are considered in the ray-cast space and the surrounding-view space within a unified Transformer network. Experiments demonstrate that our TransNeRF, trained on a wide variety of scenes, can achieve better performance in comparison to state-of-the-art image-based neural rendering methods in both scene-agnostic and per-scene finetuning scenarios especially when there is a considerable gap between source views and a rendering view.