 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResNet Structure Simplification with the Convolutional Kernel Redundancy Measure
Dec 01, 2022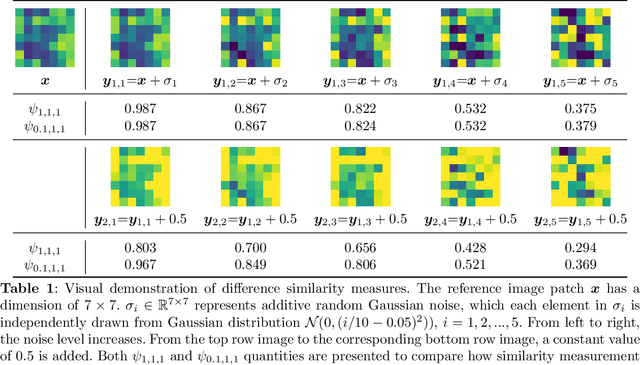
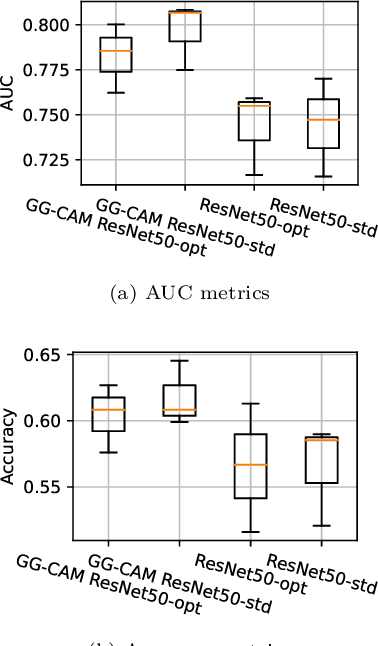
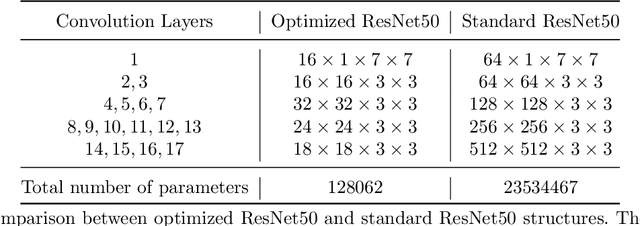
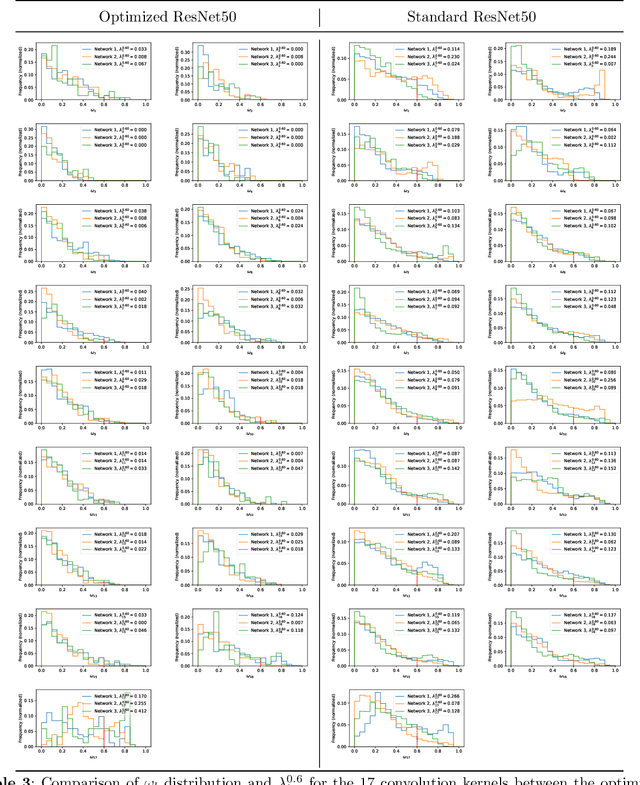
Deep learning, especially convolutional neural networks, has triggered accelerated advancements in computer vision, bringing changes into our daily practice. Furthermore, the standardized deep learning modules (also known as backbone networks), i.e., ResNet and EfficientNet, have enabled efficient and rapid development of new computer vision solutions. Yet, deep learning methods still suffer from several drawbacks. One of the most concerning problems is the high memory and computational cost, such that dedicated computing units, typically GPUs, have to be used for training and development. Therefore, in this paper, we propose a quantifiable evaluation method, the convolutional kernel redundancy measure, which is based on perceived image differences, for guiding the network structure simplification. When applying our method to the chest X-ray image classification problem with ResNet, our method can maintain the performance of the network and reduce the number of parameters from over $23$ million to approximately $128$ thousand (reducing $99.46\%$ of the parameters).
Semi-supervised MIMO Detection Using Cycle-consistent Generative Adversarial Network
Jun 19, 2022
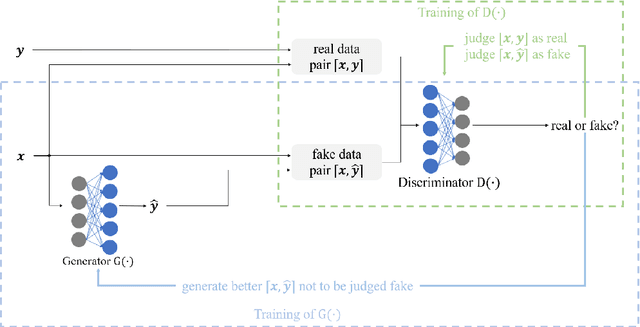
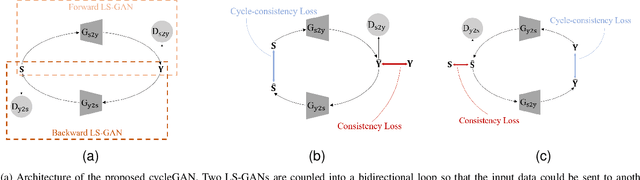
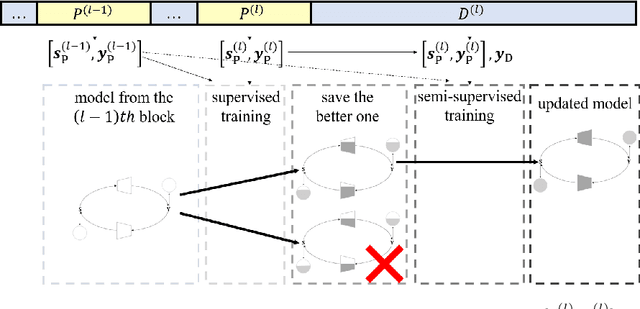
In this paper, a new semi-supervised deep MIMO detection approach using a cycle-consistent generative adversarial network (cycleGAN) is proposed, which performs the detection without any prior knowledge of underlying channel models. Specifically, we propose the cycleGAN detector by constructing a bidirectional loop of least squares generative adversarial networks (LS-GAN). The forward direction of the loop learns to model the transmission process, while the backward direction learns to detect the transmitted signals. By optimizing the cycle-consistency of the transmitted and received signals through this loop, the proposed method is able to train a specific detector block-by-block to fit the operating channel. The training is conducted online, including a supervised phase using pilots and an unsupervised phase using received payload data. This semi-supervised training strategy weakens the demand for the scale of labelled training dataset, which is related to the number of pilots, and thus the overhead is effectively reduced. Numerical results show that the proposed semi-blind cycleGAN detector achieves better bit error-rate (BER) than existing semi-blind deep learning detection methods as well as conditional linear detectors, especially when nonlinear distortion of the power amplifiers at the transmitter is considered.
Multi-task UNet: Jointly Boosting Saliency Prediction and Disease Classification on Chest X-ray Images
Feb 15, 2022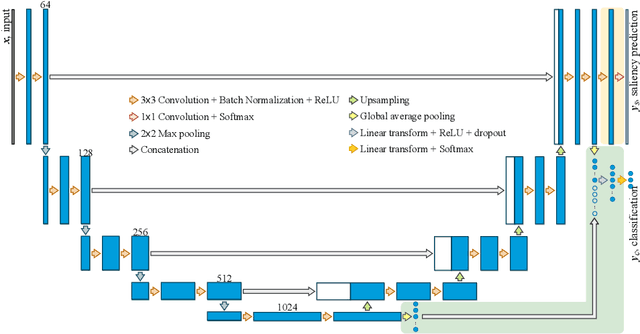
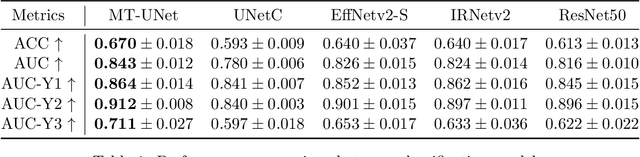


Human visual attention has recently shown its distinct capability in boosting machine learning models. However, studies that aim to facilitate medical tasks with human visual attention are still scarce. To support the use of visual attention, this paper describes a novel deep learning model for visual saliency prediction on chest X-ray (CXR) images. To cope with data deficiency, we exploit the multi-task learning method and tackles disease classification on CXR simultaneously. For a more robust training process, we propose a further optimized multi-task learning scheme to better handle model overfitting. Experiments show our proposed deep learning model with our new learning scheme can outperform existing methods dedicated either for saliency prediction or image classification. The code used in this paper is available at https://github.com/hz-zhu/MT-UNet.
Gaze-Guided Class Activation Mapping: Leveraging Human Attention for Network Attention in Chest X-rays Classification
Feb 15, 2022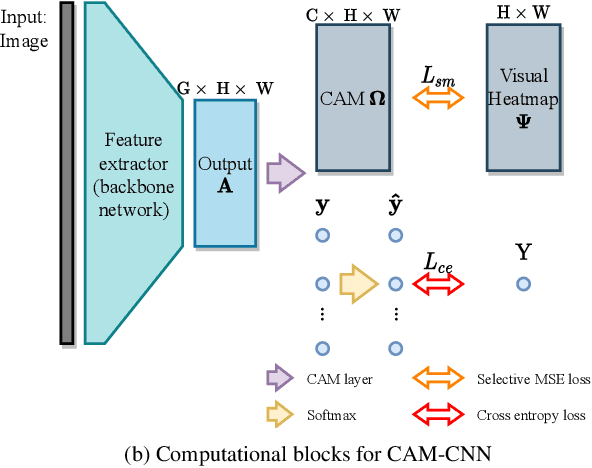
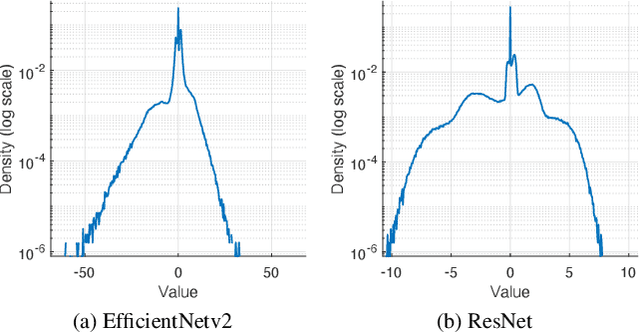
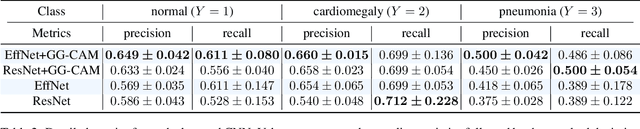
The increased availability and accuracy of eye-gaze tracking technology has sparked attention-related research in psychology, neuroscience, and, more recently, computer vision and artificial intelligence. The attention mechanism in artificial neural networks is known to improve learning tasks. However, no previous research has combined the network attention and human attention. This paper describes a gaze-guided class activation mapping (GG-CAM) method to directly regulate the formation of network attention based on expert radiologists' visual attention for the chest X-ray pathology classification problem, which remains challenging due to the complex and often nuanced differences among images. GG-CAM is a lightweight ($3$ additional trainable parameters for regulating the learning process) and generic extension that can be easily applied to most classification convolutional neural networks (CNN). GG-CAM-modified CNNs do not require human attention as an input when fully trained. Comparative experiments suggest that two standard CNNs with the GG-CAM extension achieve significantly greater classification performance. The median area under the curve (AUC) metrics for ResNet50 increases from $0.721$ to $0.776$. For EfficientNetv2 (s), the median AUC increases from $0.723$ to $0.801$. The GG-CAM also brings better interpretability of the network that facilitates the weakly-supervised pathology localization and analysis.