 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResNet Structure Simplification with the Convolutional Kernel Redundancy Measure
Paper and Code
Dec 01, 2022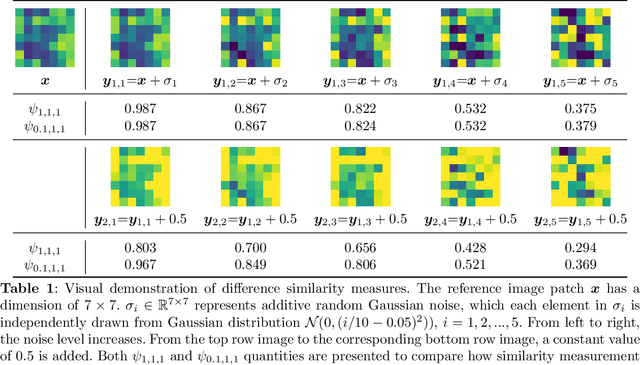
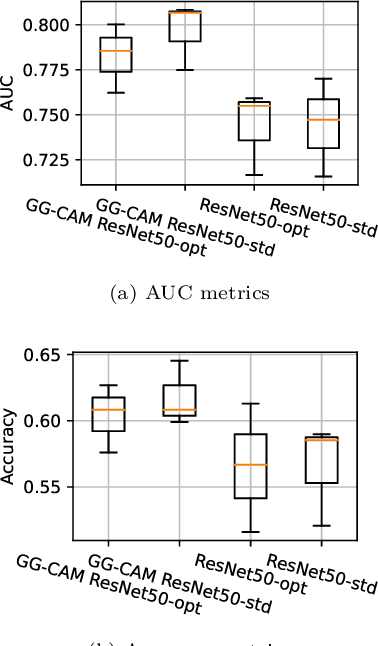
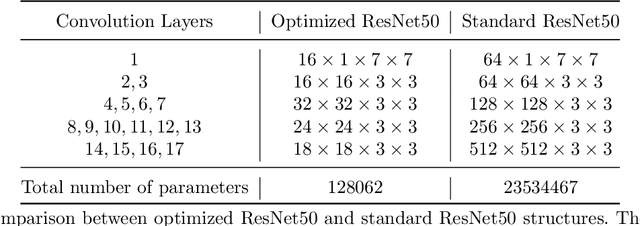
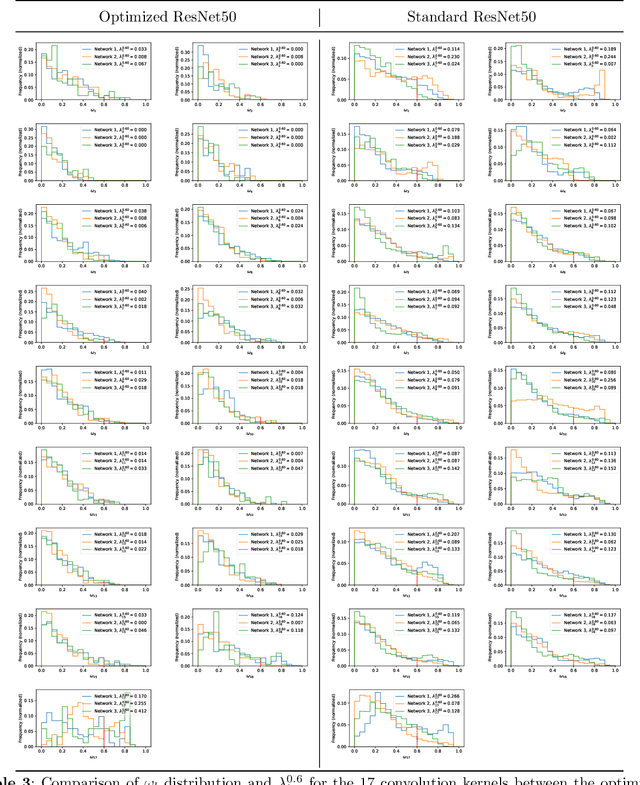
Deep learning, especially convolutional neural networks, has triggered accelerated advancements in computer vision, bringing changes into our daily practice. Furthermore, the standardized deep learning modules (also known as backbone networks), i.e., ResNet and EfficientNet, have enabled efficient and rapid development of new computer vision solutions. Yet, deep learning methods still suffer from several drawbacks. One of the most concerning problems is the high memory and computational cost, such that dedicated computing units, typically GPUs, have to be used for training and development. Therefore, in this paper, we propose a quantifiable evaluation method, the convolutional kernel redundancy measure, which is based on perceived image differences, for guiding the network structure simplification. When applying our method to the chest X-ray image classification problem with ResNet, our method can maintain the performance of the network and reduce the number of parameters from over $23$ million to approximately $128$ thousand (reducing $99.46\%$ of the parameters).