 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRendering stable features improves sampling-based localisation with Neural radiance fields
Sep 21, 2023



Neural radiance fields (NeRFs) are a powerful tool for implicit scene representations, allowing for differentiable rendering and the ability to make predictions about previously unseen viewpoints. From a robotics perspective, there has been growing interest in object and scene-based localisation using NeRFs, with a number of recent works relying on sampling-based or Monte-Carlo localisation schemes. Unfortunately, these can be extremely computationally expensive, requiring multiple network forward passes to infer camera or object pose. To alleviate this, a variety of sampling strategies have been applied, many relying on keypoint recognition techniques from classical computer vision. This work conducts a systematic empirical comparison of these approaches and shows that in contrast to conventional feature matching approaches for geometry-based localisation, sampling-based localisation using NeRFs benefits significantly from stable features. Results show that rendering stable features can result in a tenfold reduction in the number of forward passes required, a significant speed improvement.
How to Train Your Event Camera Neural Network
Apr 09, 2020
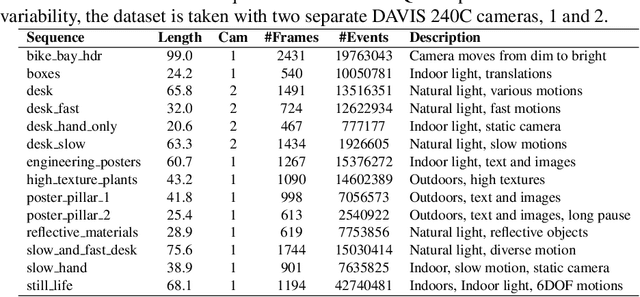
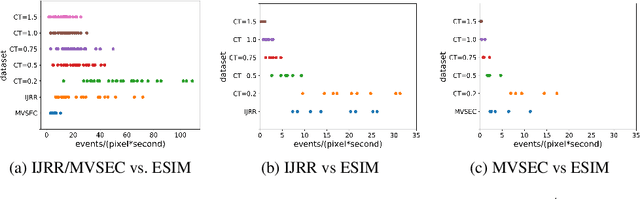
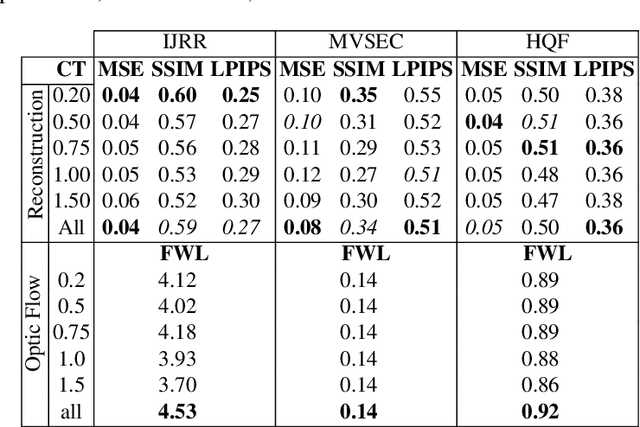
Event cameras are paradigm-shifting novel sensors that report asynchronous, per-pixel brightness changes called 'events' with unparalleled low latency. This makes them ideal for high speed, high dynamic range scenes where conventional cameras would fail. Recent work has demonstrated impressive results using Convolutional Neural Networks (CNNs) for video reconstruction and optic flow with events. We present strategies for improving training data for event based CNNs that result in 25-40% boost in performance of existing state-of-the-art (SOTA) video reconstruction networks retrained with our method, and up to 80% for optic flow networks. A challenge in evaluating event based video reconstruction is lack of quality groundtruth images in existing datasets. To address this, we present a new High Quality Frames (HQF) dataset, containing events and groundtruth frames from a DAVIS240C that are well-exposed and minimally motion-blurred. We evaluate our method on HQF + several existing major event camera datasets.
3D Sensing of a Moving Object with a Nodding 2D LIDAR and Reconfigurable Mirrors
Dec 27, 2019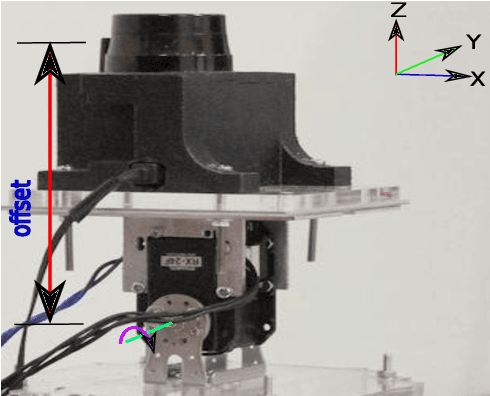
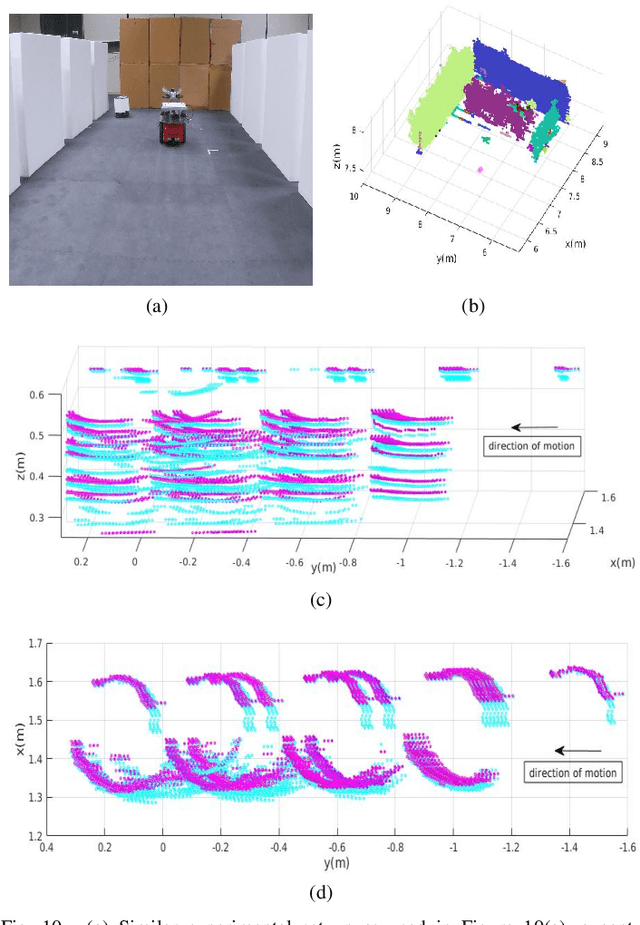
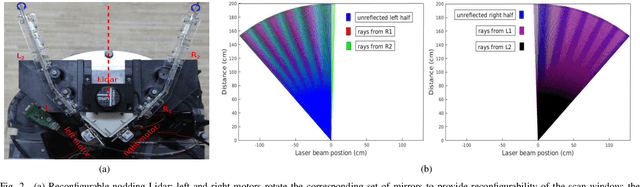
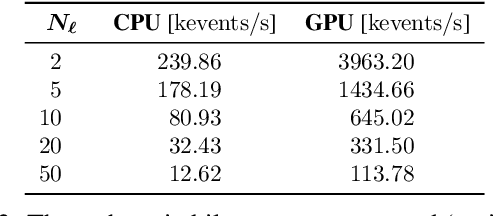
Perception in 3D has become standard practice for a large part of robotics applications. High quality 3D perception is costly. Our previous work on a nodding 2D Lidar provides high quality 3D depth information with low cost, but the sparse data generated by this sensor poses challenges in understanding the characteristics of moving objects within an uncertain environment. This paper proposes a novel design of the nodding Lidar but provides dynamic reconfigurability in terms of limiting the field of view of the sensor using a set of optical mirrors. It not only provides denser scans, but it also achieves a three times higher scan update rate. Additionally, we propose a novel calibration mechanism for this sensor and prove its effectiveness for dynamic object detection and tracking.
Event-Based Motion Segmentation by Motion Compensation
Apr 04, 2019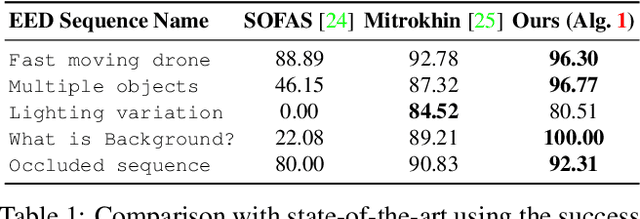
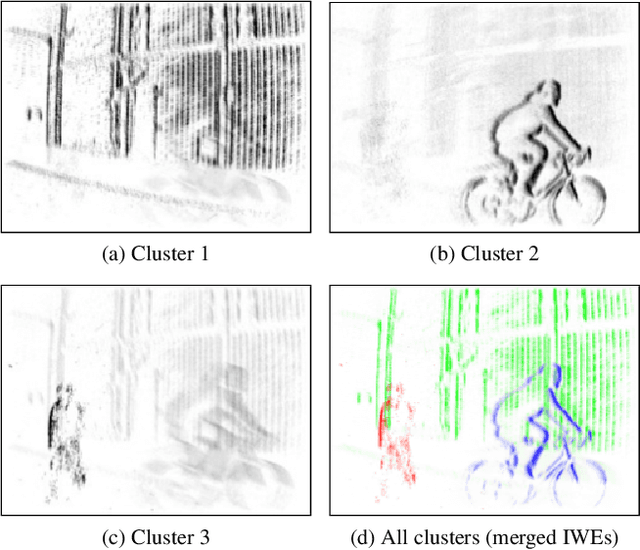

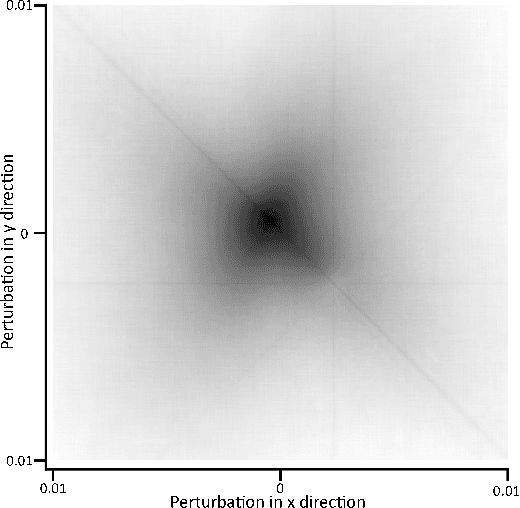
In contrast to traditional cameras, whose pixels have a common exposure time, event-based cameras are novel bio-inspired sensors whose pixels work independently and asynchronously output intensity changes (called "events"), with microsecond resolution. Since events are caused by the apparent motion of objects, event-based cameras sample visual information based on the scene dynamics and are, therefore, a more natural fit than traditional cameras to acquire motion, especially at high speeds, where traditional cameras suffer from motion blur. However, distinguishing between events caused by different moving objects and by the camera's ego-motion is a challenging task. We present the first per-event segmentation method for splitting a scene into independently moving objects. Our method jointly estimates the event-object associations (i.e., segmentation) and the motion parameters of the objects (or the background) by maximization of an objective function, which builds upon recent results on event-based motion-compensation. We provide a thorough evaluation of our method on a public dataset, outperforming the state-of-the-art by as much as 10%. We also show the first quantitative evaluation of a segmentation algorithm for event cameras, yielding around 90% accuracy at 4 pixels relative displacement.
Simultaneous Optical Flow and Segmentation (SOFAS) using Dynamic Vision Sensor
May 31, 2018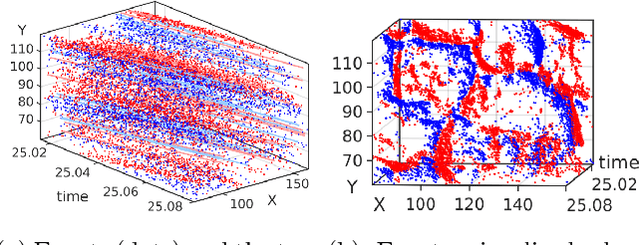

We present an algorithm (SOFAS) to estimate the optical flow of events generated by a dynamic vision sensor (DVS). Where traditional cameras produce frames at a fixed rate, DVSs produce asynchronous events in response to intensity changes with a high temporal resolution. Our algorithm uses the fact that events are generated by edges in the scene to not only estimate the optical flow but also to simultaneously segment the image into objects which are travelling at the same velocity. This way it is able to avoid the aperture problem which affects other implementations such as Lucas-Kanade. Finally, we show that SOFAS produces more accurate results than traditional optic flow algorithms.