 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConTra: text nsformer for Cross-Modal Video Retrieval
Paper and Code
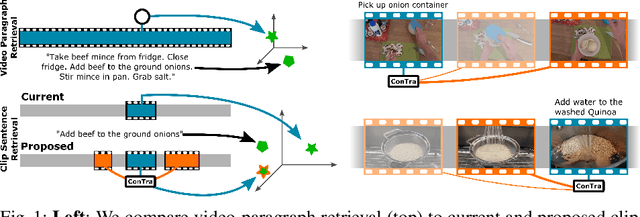
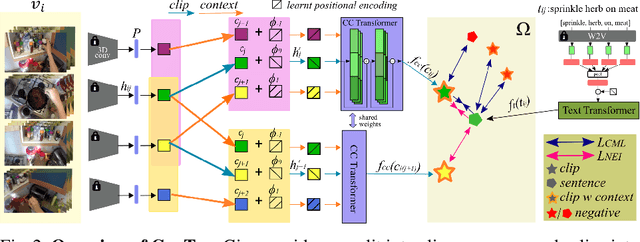
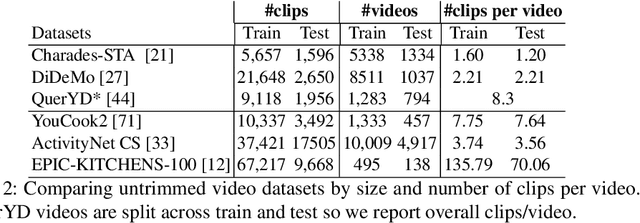
In this paper, we re-examine the task of cross-modal clip-sentence retrieval, where the clip is part of a longer untrimmed video. When the clip is short or visually ambiguous, knowledge of its local temporal context (i.e. surrounding video segments) can be used to improve the retrieval performance. We propose Context Transformer (ConTra); an encoder architecture that models the interaction between a video clip and its local temporal context in order to enhance its embedded representations. Importantly, we supervise the context transformer using contrastive losses in the cross-modal embedding space. We explore context transformers for video and text modalities. Results consistently demonstrate improved performance on three datasets: YouCook2, EPIC-KITCHENS and a clip-sentence version of ActivityNet Captions. Exhaustive ablation studies and context analysis show the efficacy of the proposed method.