 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Editing for Video Retrieval
Paper and Code
Feb 04, 2024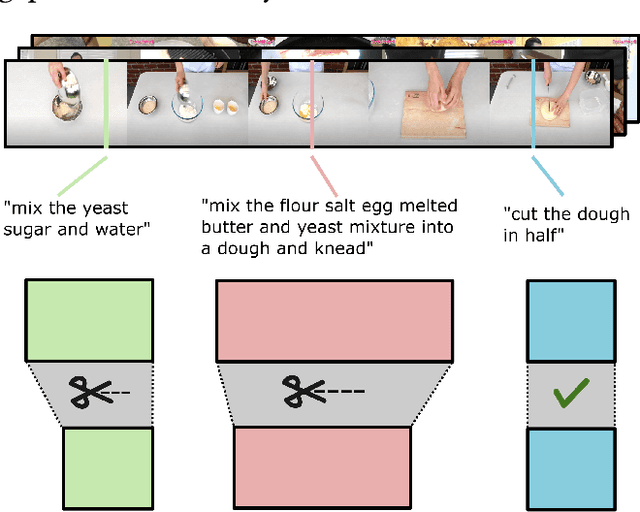
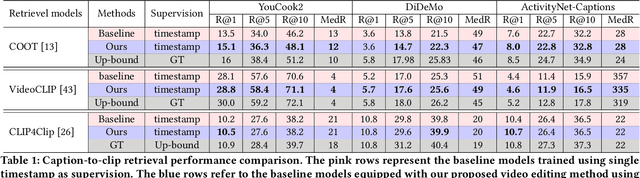
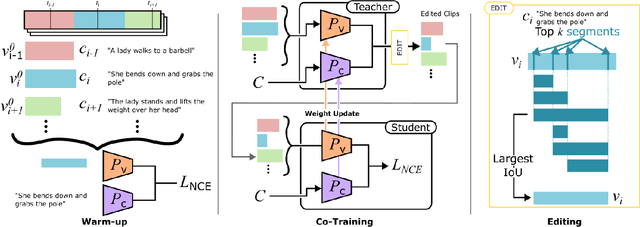
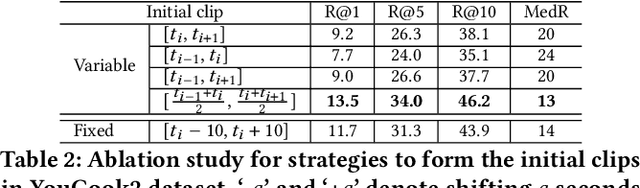
Though pre-training vision-language models have demonstrated significant benefits in boosting video-text retrieval performance from large-scale web videos, fine-tuning still plays a critical role with manually annotated clips with start and end times, which requires considerable human effort. To address this issue, we explore an alternative cheaper source of annotations, single timestamps, for video-text retrieval. We initialise clips from timestamps in a heuristic way to warm up a retrieval model. Then a video clip editing method is proposed to refine the initial rough boundaries to improve retrieval performance. A student-teacher network is introduced for video clip editing. The teacher model is employed to edit the clips in the training set whereas the student model trains on the edited clips. The teacher weights are updated from the student's after the student's performance increases. Our method is model agnostic and applicable to any retrieval models. We conduct experiments based on three state-of-the-art retrieval models, COOT, VideoCLIP and CLIP4Clip. Experiments conducted on three video retrieval datasets, YouCook2, DiDeMo and ActivityNet-Captions show that our edited clips consistently improve retrieval performance over initial clips across all the three retrieval models.