 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Exploration in Continuous Action Spaces
Jan 26, 2018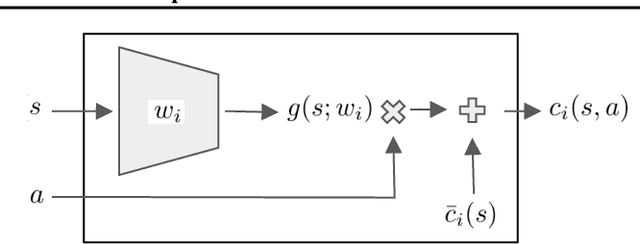
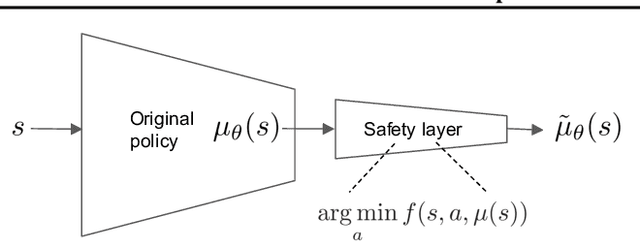


We address the problem of deploying a reinforcement learning (RL) agent on a physical system such as a datacenter cooling unit or robot, where critical constraints must never be violated. We show how to exploit the typically smooth dynamics of these systems and enable RL algorithms to never violate constraints during learning. Our technique is to directly add to the policy a safety layer that analytically solves an action correction formulation per each state. The novelty of obtaining an elegant closed-form solution is attained due to a linearized model, learned on past trajectories consisting of arbitrary actions. This is to mimic the real-world circumstances where data logs were generated with a behavior policy that is implausible to describe mathematically; such cases render the known safety-aware off-policy methods inapplicable. We demonstrate the efficacy of our approach on new representative physics-based environments, and prevail where reward shaping fails by maintaining zero constraint violations.
Deep Q-learning from Demonstrations
Nov 22, 2017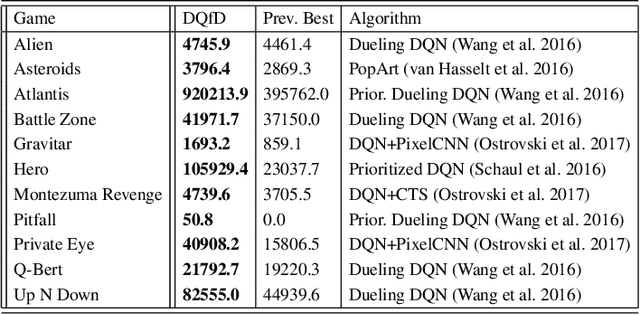
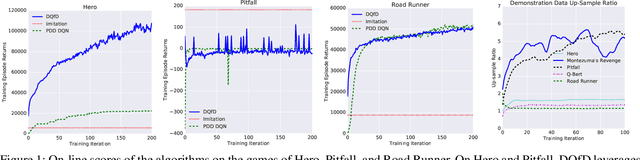
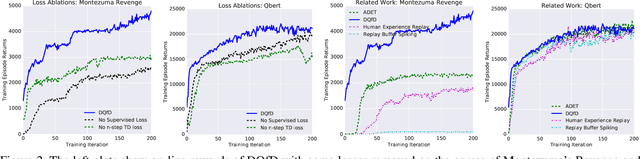
Deep reinforcement learning (RL) has achieved several high profile successes in difficult decision-making problems. However, these algorithms typically require a huge amount of data before they reach reasonable performance. In fact, their performance during learning can be extremely poor. This may be acceptable for a simulator, but it severely limits the applicability of deep RL to many real-world tasks, where the agent must learn in the real environment. In this paper we study a setting where the agent may access data from previous control of the system. We present an algorithm, Deep Q-learning from Demonstrations (DQfD), that leverages small sets of demonstration data to massively accelerate the learning process even from relatively small amounts of demonstration data and is able to automatically assess the necessary ratio of demonstration data while learning thanks to a prioritized replay mechanism. DQfD works by combining temporal difference updates with supervised classification of the demonstrator's actions. We show that DQfD has better initial performance than Prioritized Dueling Double Deep Q-Networks (PDD DQN) as it starts with better scores on the first million steps on 41 of 42 games and on average it takes PDD DQN 83 million steps to catch up to DQfD's performance. DQfD learns to out-perform the best demonstration given in 14 of 42 games. In addition, DQfD leverages human demonstrations to achieve state-of-the-art results for 11 games. Finally, we show that DQfD performs better than three related algorithms for incorporating demonstration data into DQN.
Data-efficient Deep Reinforcement Learning for Dexterous Manipulation
Apr 10, 2017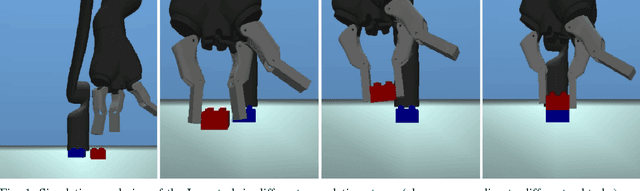
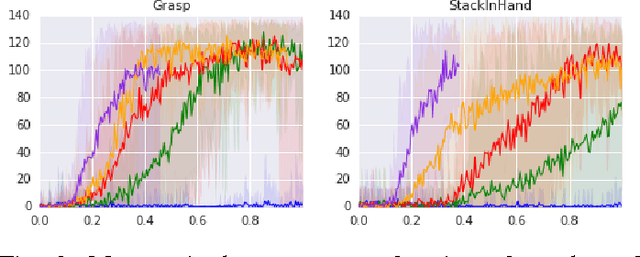
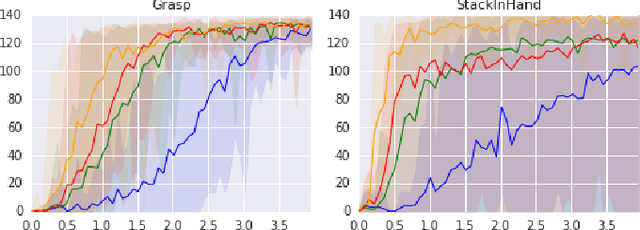
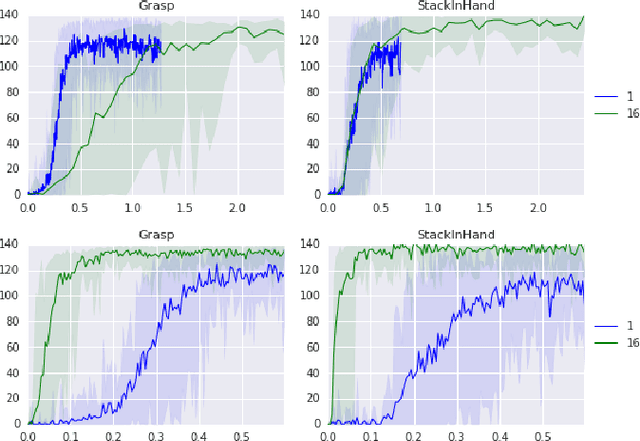
Deep learning and reinforcement learning methods have recently been used to solve a variety of problems in continuous control domains. An obvious application of these techniques is dexterous manipulation tasks in robotics which are difficult to solve using traditional control theory or hand-engineered approaches. One example of such a task is to grasp an object and precisely stack it on another. Solving this difficult and practically relevant problem in the real world is an important long-term goal for the field of robotics. Here we take a step towards this goal by examining the problem in simulation and providing models and techniques aimed at solving it. We introduce two extensions to the Deep Deterministic Policy Gradient algorithm (DDPG), a model-free Q-learning based method, which make it significantly more data-efficient and scalable. Our results show that by making extensive use of off-policy data and replay, it is possible to find control policies that robustly grasp objects and stack them. Further, our results hint that it may soon be feasible to train successful stacking policies by collecting interactions on real robots.