 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible framework for generating synthetic electrocardiograms and photoplethysmograms
Aug 29, 2024



By generating synthetic biosignals, the quantity and variety of health data can be increased. This is especially useful when training machine learning models by enabling data augmentation and introduction of more physiologically plausible variation to the data. For these purposes, we have developed a synthetic biosignal model for two signal modalities, electrocardiography (ECG) and photoplethysmography (PPG). The model produces realistic signals that account for physiological effects such as breathing modulation and changes in heart rate due to physical stress. Arrhythmic signals can be generated with beat intervals extracted from real measurements. The model also includes a flexible approach to adding different kinds of noise and signal artifacts. The noise is generated from power spectral densities extracted from both measured noisy signals and modeled power spectra. Importantly, the model also automatically produces labels for noise, segmentation (e.g. P and T waves, QRS complex, for electrocardiograms), and artifacts. We assessed how this comprehensive model can be used in practice to improve the performance of models trained on ECG or PPG data. For example, we trained an LSTM to detect ECG R-peaks using both real ECG signals from the MIT-BIH arrythmia set and our new generator. The F1 score of the model was 0.83 using real data, in comparison to 0.98 using our generator. In addition, the model can be used for example in signal segmentation, quality detection and bench-marking detection algorithms. The model code has been released in \url{https://github.com/UTU-Health-Research/framework_for_synthetic_biosignals}
Empirical investigation of multi-source cross-validation in clinical machine learning
Mar 22, 2024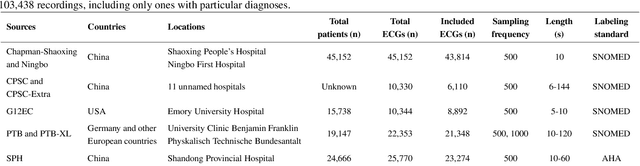
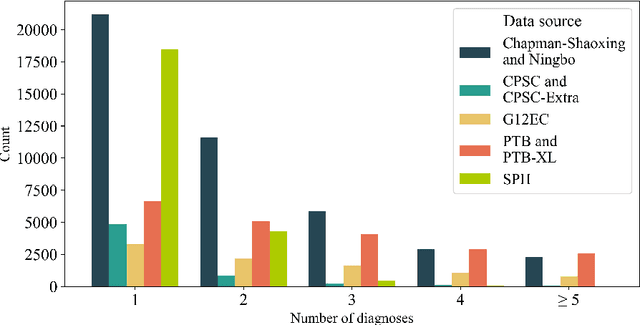
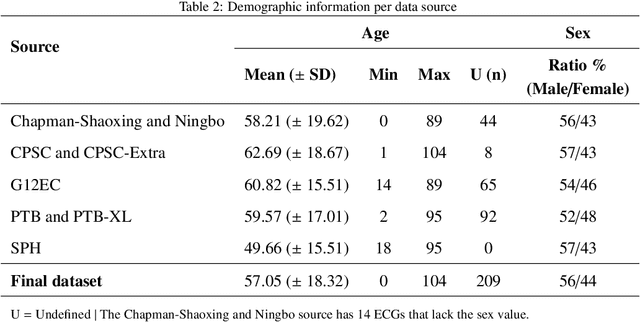
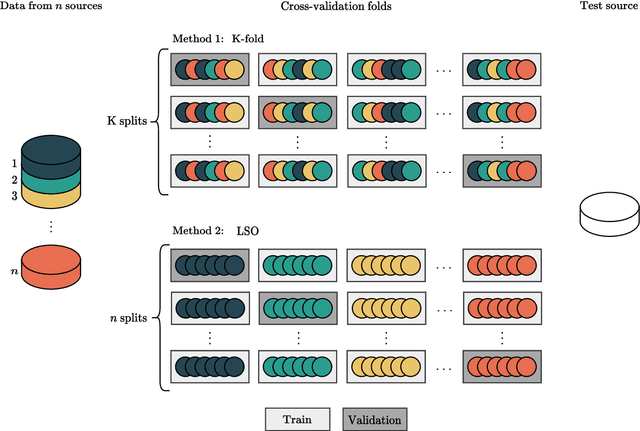
Traditionally, machine learning-based clinical prediction models have been trained and evaluated on patient data from a single source, such as a hospital. Cross-validation methods can be used to estimate the accuracy of such models on new patients originating from the same source, by repeated random splitting of the data. However, such estimates tend to be highly overoptimistic when compared to accuracy obtained from deploying models to sources not represented in the dataset, such as a new hospital. The increasing availability of multi-source medical datasets provides new opportunities for obtaining more comprehensive and realistic evaluations of expected accuracy through source-level cross-validation designs. In this study, we present a systematic empirical evaluation of standard K-fold cross-validation and leave-source-out cross-validation methods in a multi-source setting. We consider the task of electrocardiogram based cardiovascular disease classification, combining and harmonizing the openly available PhysioNet CinC Challenge 2021 and the Shandong Provincial Hospital datasets for our study. Our results show that K-fold cross-validation, both on single-source and multi-source data, systemically overestimates prediction performance when the end goal is to generalize to new sources. Leave-source-out cross-validation provides more reliable performance estimates, having close to zero bias though larger variability. The evaluation highlights the dangers of obtaining misleading cross-validation results on medical data and demonstrates how these issues can be mitigated when having access to multi-source data.
Training neural networks with synthetic electrocardiograms
Nov 11, 2021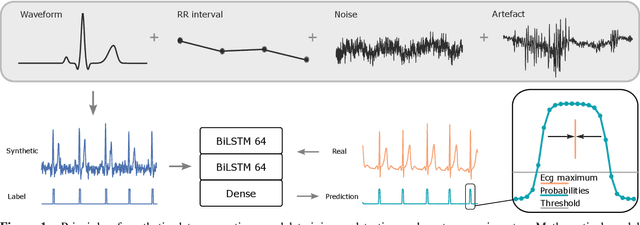
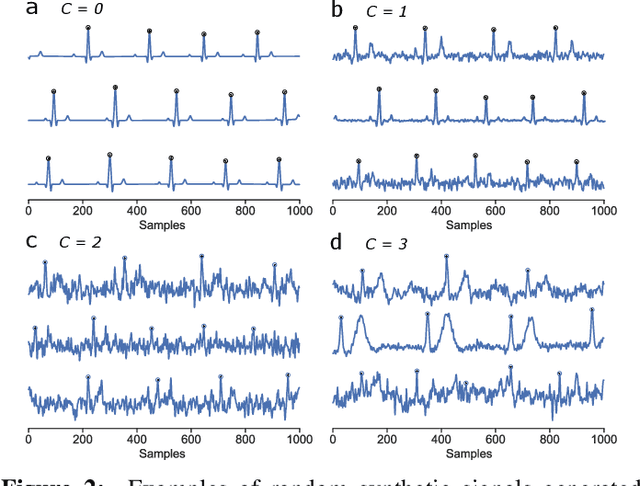
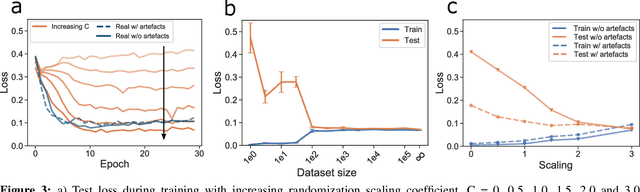
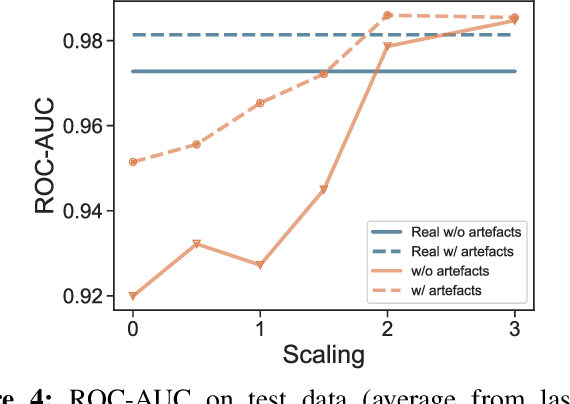
We present a method for training neural networks with synthetic electrocardiograms that mimic signals produced by a wearable single lead electrocardiogram monitor. We use domain randomization where the synthetic signal properties such as the waveform shape, RR-intervals and noise are varied for every training example. Models trained with synthetic data are compared to their counterparts trained with real data. Detection of r-waves in electrocardiograms recorded during different physical activities and in atrial fibrillation is used to compare the models. By allowing the randomization to increase beyond what is typically observed in the real-world data the performance is on par or superseding the performance of networks trained with real data. Experiments show robust performance with different seeds and training examples on different test sets without any test set specific tuning. The method makes possible to train neural networks using practically free-to-collect data with accurate labels without the need for manual annotations and it opens up the possibility of extending the use of synthetic data on cardiac disease classification when disease specific a priori information is used in the electrocardiogram generation. Additionally the distribution of data can be controlled eliminating class imbalances that are typically observed in health related data and additionally the generated data is inherently private.