 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMastering Terra Mystica: Applying Self-Play to Multi-agent Cooperative Board Games
Paper and Code

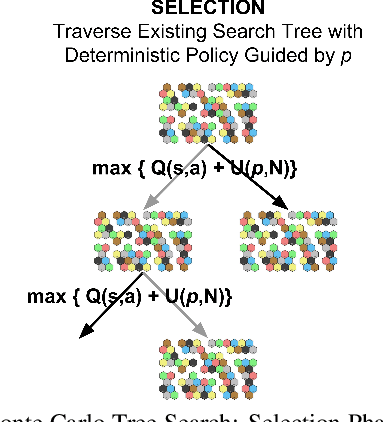


In this paper, we explore and compare multiple algorithms for solving the complex strategy game of Terra Mystica, hereafter abbreviated as TM. Previous work in the area of super-human game-play using AI has proven effective, with recent break-through for generic algorithms in games such as Go, Chess, and Shogi \cite{AlphaZero}. We directly apply these breakthroughs to a novel state-representation of TM with the goal of creating an AI that will rival human players. Specifically, we present the initial results of applying AlphaZero to this state-representation and analyze the strategies developed. A brief analysis is presented. We call this modified algorithm with our novel state-representation AlphaTM. In the end, we discuss the success and shortcomings of this method by comparing against multiple baselines and typical human scores. All code used for this paper is available at on \href{https://github.com/kandluis/terrazero}{GitHub}.