 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShort-form Text Rewriting with Phi Silica
May 30, 2026Short-form text rewriting is a constrained variant of paraphrasing in which limited context and high semantic density leave little room for variation. While large language models perform well on general paraphrasing, small language models (SLMs) often struggle with semantic fidelity and hallucination robustness in short-form settings. In this work, we present an empirical study of adapting an SLM, Phi Silica, for short-form rewrite through dataset curation, prompt distillation, parameter-efficient fine-tuning, and evaluation. We curate a dataset of short presentation-style text from public slide decks and use GPT-5-chat both to generate rewrite supervision and to conduct LLM-as-a-judge evaluation. Our results show that finetuning improves semantic fidelity, reduces hallucinations, and increases preference win rate against GPT-5-chat rewrites. The findings suggest that targeted adaptation for SLMs can substantially narrow the gap to cloud models and provide practical guidance for adapting SLMs to precision-critical rewrite tasks.
Studying word order through iterative shuffling
Sep 10, 2021
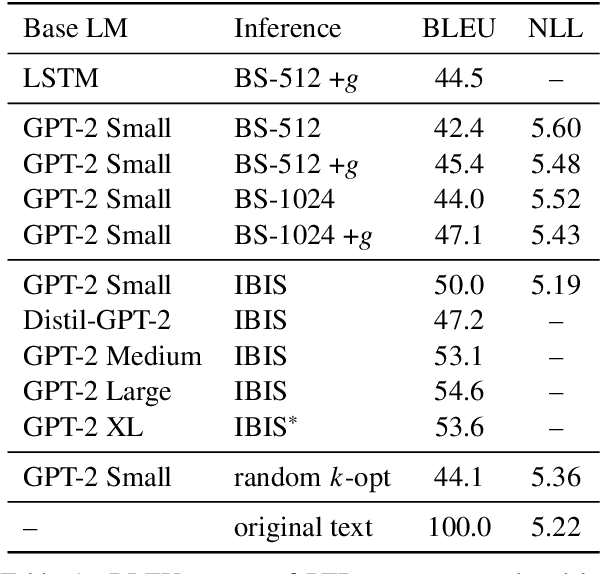


As neural language models approach human performance on NLP benchmark tasks, their advances are widely seen as evidence of an increasingly complex understanding of syntax. This view rests upon a hypothesis that has not yet been empirically tested: that word order encodes meaning essential to performing these tasks. We refute this hypothesis in many cases: in the GLUE suite and in various genres of English text, the words in a sentence or phrase can rarely be permuted to form a phrase carrying substantially different information. Our surprising result relies on inference by iterative shuffling (IBIS), a novel, efficient procedure that finds the ordering of a bag of words having the highest likelihood under a fixed language model. IBIS can use any black-box model without additional training and is superior to existing word ordering algorithms. Coalescing our findings, we discuss how shuffling inference procedures such as IBIS can benefit language modeling and constrained generation.
ARCHER: Aggressive Rewards to Counter bias in Hindsight Experience Replay
Sep 07, 2018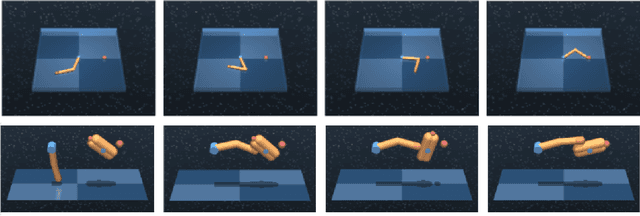
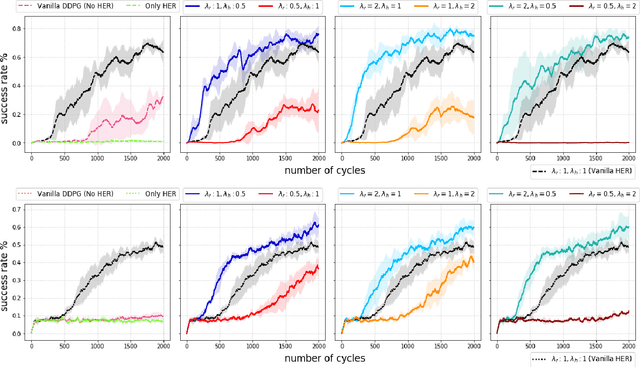
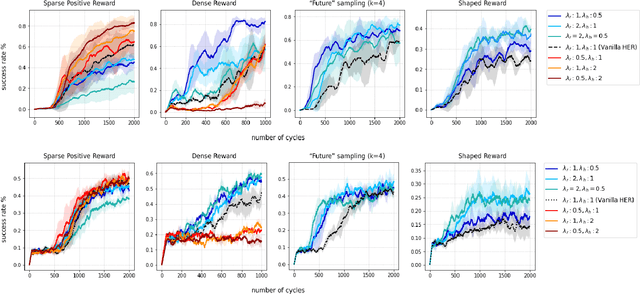
Experience replay is an important technique for addressing sample-inefficiency in deep reinforcement learning (RL), but faces difficulty in learning from binary and sparse rewards due to disproportionately few successful experiences in the replay buffer. Hindsight experience replay (HER) was recently proposed to tackle this difficulty by manipulating unsuccessful transitions, but in doing so, HER introduces a significant bias in the replay buffer experiences and therefore achieves a suboptimal improvement in sample-efficiency. In this paper, we present an analysis on the source of bias in HER, and propose a simple and effective method to counter the bias, to most effectively harness the sample-efficiency provided by HER. Our method, motivated by counter-factual reasoning and called ARCHER, extends HER with a trade-off to make rewards calculated for hindsight experiences numerically greater than real rewards. We validate our algorithm on two continuous control environments from DeepMind Control Suite - Reacher and Finger, which simulate manipulation tasks with a robotic arm - in combination with various reward functions, task complexities and goal sampling strategies. Our experiments consistently demonstrate that countering bias using more aggressive hindsight rewards increases sample efficiency, thus establishing the greater benefit of ARCHER in RL applications with limited computing budget.