 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProxAnn: Use-Oriented Evaluations of Topic Models and Document Clustering
Jul 01, 2025Topic model and document-clustering evaluations either use automated metrics that align poorly with human preferences or require expert labels that are intractable to scale. We design a scalable human evaluation protocol and a corresponding automated approximation that reflect practitioners' real-world usage of models. Annotators -- or an LLM-based proxy -- review text items assigned to a topic or cluster, infer a category for the group, then apply that category to other documents. Using this protocol, we collect extensive crowdworker annotations of outputs from a diverse set of topic models on two datasets. We then use these annotations to validate automated proxies, finding that the best LLM proxies are statistically indistinguishable from a human annotator and can therefore serve as a reasonable substitute in automated evaluations. Package, web interface, and data are at https://github.com/ahoho/proxann
Large Language Models Struggle to Describe the Haystack without Human Help: Human-in-the-loop Evaluation of LLMs
Feb 20, 2025A common use of NLP is to facilitate the understanding of large document collections, with a shift from using traditional topic models to Large Language Models. Yet the effectiveness of using LLM for large corpus understanding in real-world applications remains under-explored. This study measures the knowledge users acquire with unsupervised, supervised LLM-based exploratory approaches or traditional topic models on two datasets. While LLM-based methods generate more human-readable topics and show higher average win probabilities than traditional models for data exploration, they produce overly generic topics for domain-specific datasets that do not easily allow users to learn much about the documents. Adding human supervision to the LLM generation process improves data exploration by mitigating hallucination and over-genericity but requires greater human effort. In contrast, traditional. models like Latent Dirichlet Allocation (LDA) remain effective for exploration but are less user-friendly. We show that LLMs struggle to describe the haystack of large corpora without human help, particularly domain-specific data, and face scaling and hallucination limitations due to context length constraints. Dataset available at https://huggingface. co/datasets/zli12321/Bills.
Federated Neural Topic Models
Dec 05, 2022

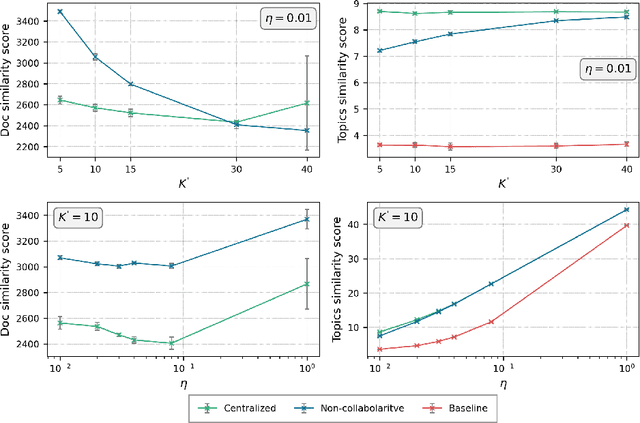
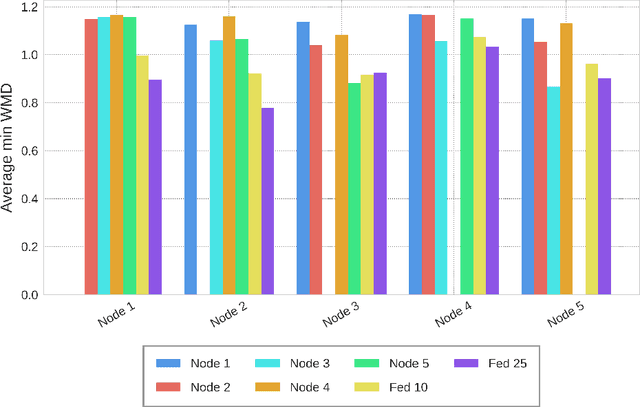
Over the last years, topic modeling has emerged as a powerful technique for organizing and summarizing big collections of documents or searching for particular patterns in them. However, privacy concerns arise when cross-analyzing data from different sources is required. Federated topic modeling solves this issue by allowing multiple parties to jointly train a topic model without sharing their data. While several federated approximations of classical topic models do exist, no research has been carried out on their application for neural topic models. To fill this gap, we propose and analyze a federated implementation based on state-of-the-art neural topic modeling implementations, showing its benefits when there is a diversity of topics across the nodes' documents and the need to build a joint model. Our approach is by construction theoretically and in practice equivalent to a centralized approach but preserves the privacy of the nodes.