 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Neural Topic Models
Dec 05, 2022

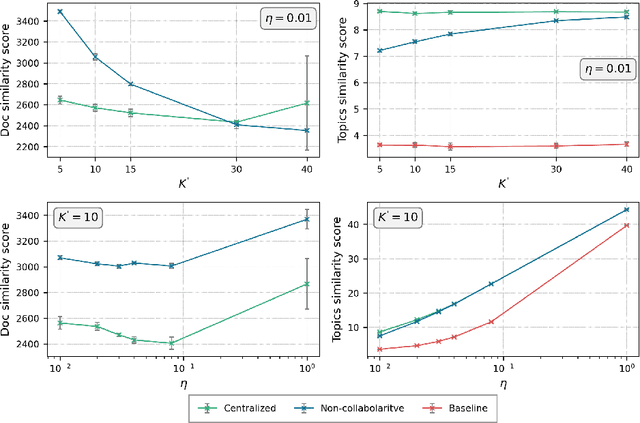
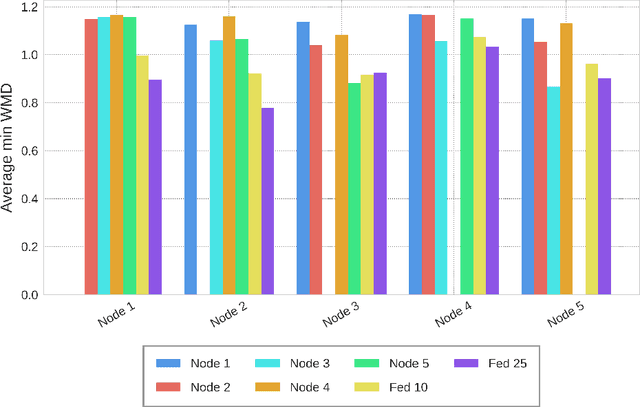
Over the last years, topic modeling has emerged as a powerful technique for organizing and summarizing big collections of documents or searching for particular patterns in them. However, privacy concerns arise when cross-analyzing data from different sources is required. Federated topic modeling solves this issue by allowing multiple parties to jointly train a topic model without sharing their data. While several federated approximations of classical topic models do exist, no research has been carried out on their application for neural topic models. To fill this gap, we propose and analyze a federated implementation based on state-of-the-art neural topic modeling implementations, showing its benefits when there is a diversity of topics across the nodes' documents and the need to build a joint model. Our approach is by construction theoretically and in practice equivalent to a centralized approach but preserves the privacy of the nodes.
Regularized Multivariate Analysis Framework for Interpretable High-Dimensional Variable Selection
Dec 22, 2021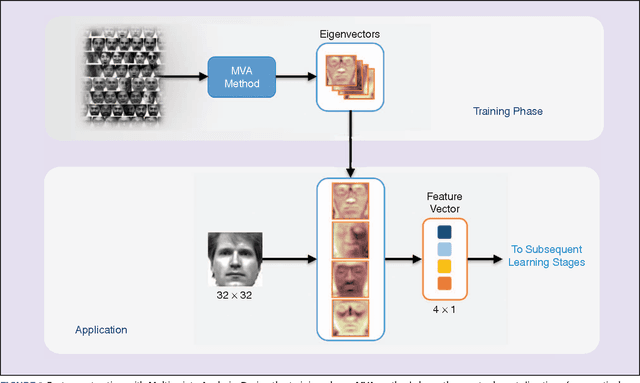
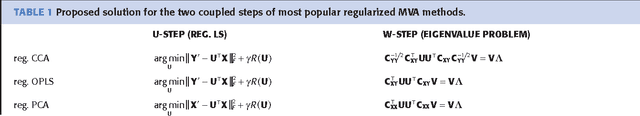
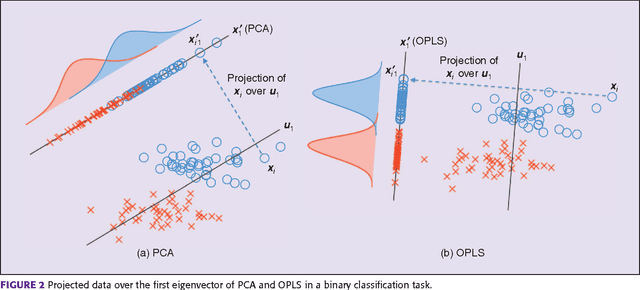
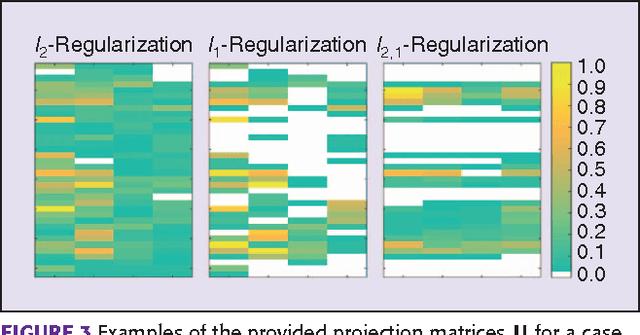
Multivariate Analysis (MVA) comprises a family of well-known methods for feature extraction which exploit correlations among input variables representing the data. One important property that is enjoyed by most such methods is uncorrelation among the extracted features. Recently, regularized versions of MVA methods have appeared in the literature, mainly with the goal to gain interpretability of the solution. In these cases, the solutions can no longer be obtained in a closed manner, and more complex optimization methods that rely on the iteration of two steps are frequently used. This paper recurs to an alternative approach to solve efficiently this iterative problem. The main novelty of this approach lies in preserving several properties of the original methods, most notably the uncorrelation of the extracted features. Under this framework, we propose a novel method that takes advantage of the l-21 norm to perform variable selection during the feature extraction process. Experimental results over different problems corroborate the advantages of the proposed formulation in comparison to state of the art formulations.
Combinations of Adaptive Filters
Dec 22, 2021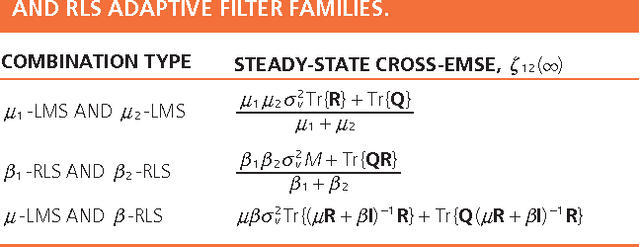

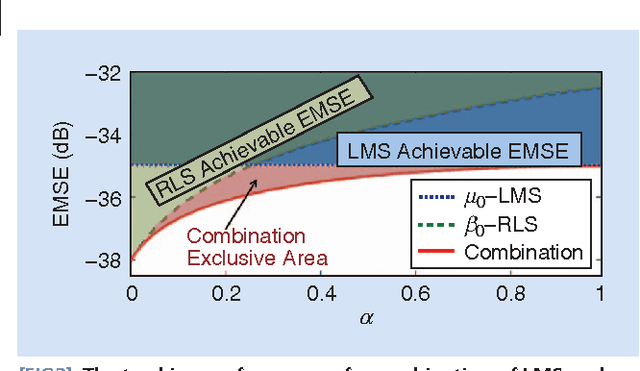
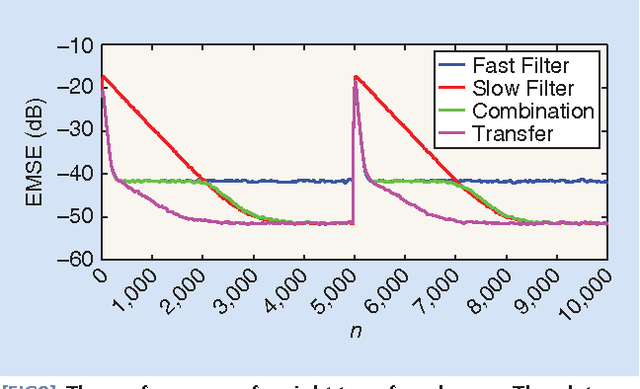
Adaptive filters are at the core of many signal processing applications, ranging from acoustic noise supression to echo cancelation, array beamforming, channel equalization, to more recent sensor network applications in surveillance, target localization, and tracking. A trending approach in this direction is to recur to in-network distributed processing in which individual nodes implement adaptation rules and diffuse their estimation to the network. When the a priori knowledge about the filtering scenario is limited or imprecise, selecting the most adequate filter structure and adjusting its parameters becomes a challenging task, and erroneous choices can lead to inadequate performance. To address this difficulty, one useful approach is to rely on combinations of adaptive structures. The combination of adaptive filters exploits to some extent the same divide and conquer principle that has also been successfully exploited by the machine-learning community (e.g., in bagging or boosting). In particular, the problem of combining the outputs of several learning algorithms (mixture of experts) has been studied in the computational learning field under a different perspective: rather than studying the expected performance of the mixture, deterministic bounds are derived that apply to individual sequences and, therefore, reflect worst-case scenarios. These bounds require assumptions different from the ones typically used in adaptive filtering, which is the emphasis of this overview article. We review the key ideas and principles behind these combination schemes, with emphasis on design rules. We also illustrate their performance with a variety of examples.
Unveiling the semantic structure of text documents using paragraph-aware Topic Models
Jun 26, 2018
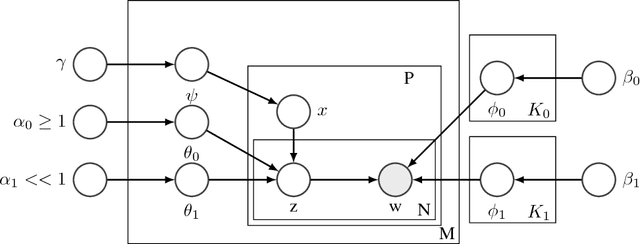
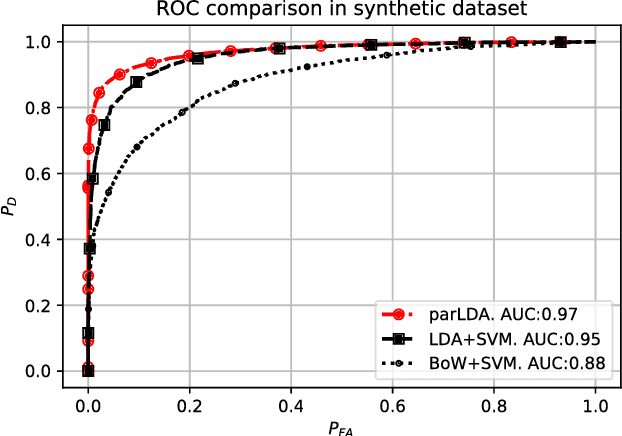

Classic Topic Models are built under the Bag Of Words assumption, in which word position is ignored for simplicity. Besides, symmetric priors are typically used in most applications. In order to easily learn topics with different properties among the same corpus, we propose a new line of work in which the paragraph structure is exploited. Our proposal is based on the following assumption: in many text document corpora there are formal constraints shared across all the collection, e.g. sections. When this assumption is satisfied, some paragraphs may be related to general concepts shared by all documents in the corpus, while others would contain the genuine description of documents. Assuming each paragraph can be semantically more general, specific, or hybrid, we look for ways to measure this, transferring this distinction to topics and being able to learn what we call specific and general topics. Experiments show that this is a proper methodology to highlight certain paragraphs in structured documents at the same time we learn interesting and more diverse topics.
Adaptive Diffusion Schemes for Heterogeneous Networks
Aug 17, 2017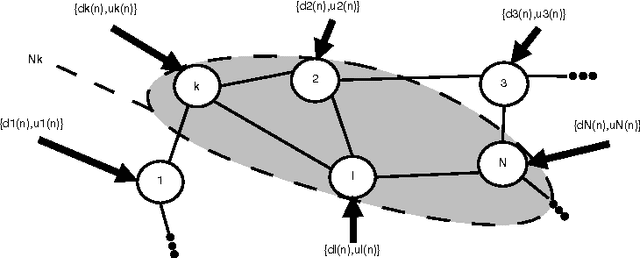
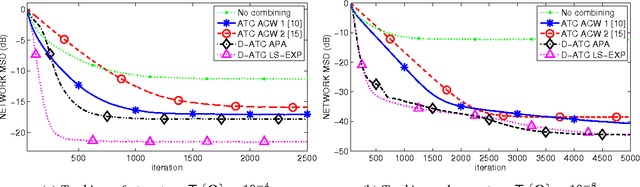
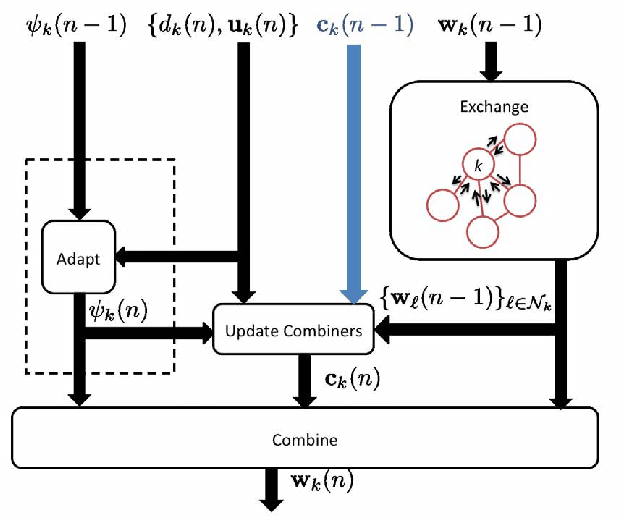
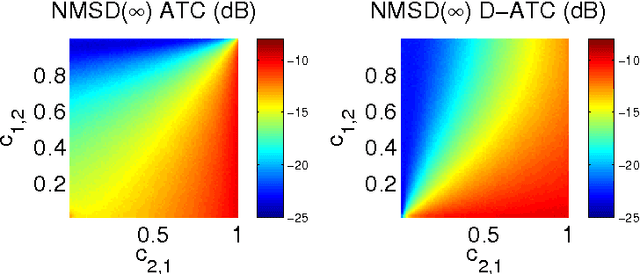
In this paper, we deal with distributed estimation problems in diffusion networks with heterogeneous nodes, i.e., nodes that either implement different adaptive rules or differ in some other aspect such as the filter structure or length, or step size. Although such heterogeneous networks have been considered from the first works on diffusion networks, obtaining practical and robust schemes to adaptively adjust the combiners in different scenarios is still an open problem. In this paper, we study a diffusion strategy specially designed and suited to heterogeneous networks. Our approach is based on two key ingredients: 1) the adaptation and combination phases are completely decoupled, so that network nodes keep purely local estimations at all times; and 2) combiners are adapted to minimize estimates of the network mean-square-error. Our scheme is compared with the standard Adapt-then-Combine scheme and theoretically analyzed using energy conservation arguments. Several experiments involving networks with heterogeneous nodes show that the proposed decoupled Adapt-then-Combine approach with adaptive combiners outperforms other state-of-the-art techniques, becoming a competitive approach in these scenarios.
* To appear in in IEEE Transactions on Signal Processing. URL: http://ieeexplore.ieee.org/document/8010454/
Why (and How) Avoid Orthogonal Procrustes in Regularized Multivariate Analysis
Sep 19, 2016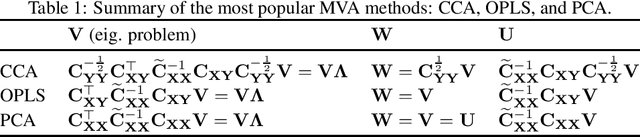
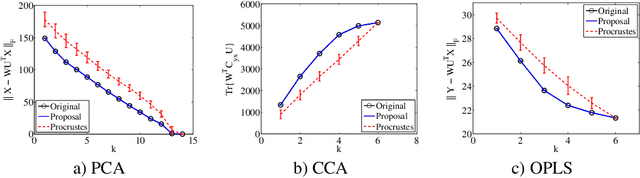

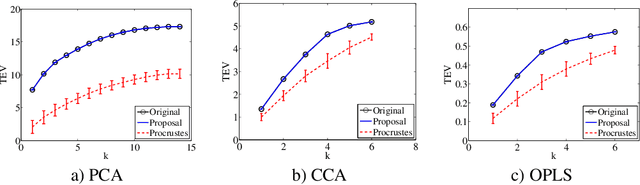
Multivariate Analysis (MVA) comprises a family of well-known methods for feature extraction that exploit correlations among input variables of the data representation. One important property that is enjoyed by most such methods is uncorrelation among the extracted features. Recently, regularized versions of MVA methods have appeared in the literature, mainly with the goal to gain interpretability of the solution. In these cases, the solutions can no longer be obtained in a closed manner, and it is frequent to recur to the iteration of two steps, one of them being an orthogonal Procrustes problem. This letter shows that the Procrustes solution is not optimal from the perspective of the overall MVA method, and proposes an alternative approach based on the solution of an eigenvalue problem. Our method ensures the preservation of several properties of the original methods, most notably the uncorrelation of the extracted features, as demonstrated theoretically and through a collection of selected experiments.
Censoring Diffusion for Harvesting WSNs
Sep 29, 2015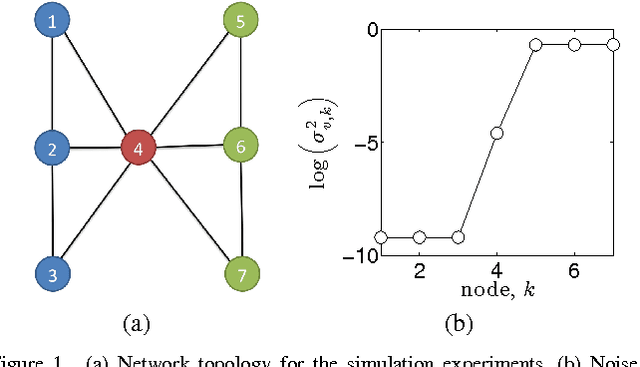
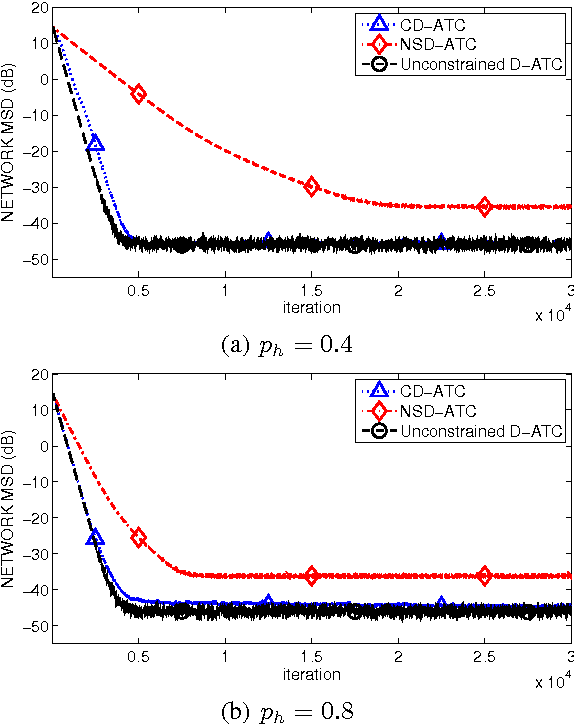
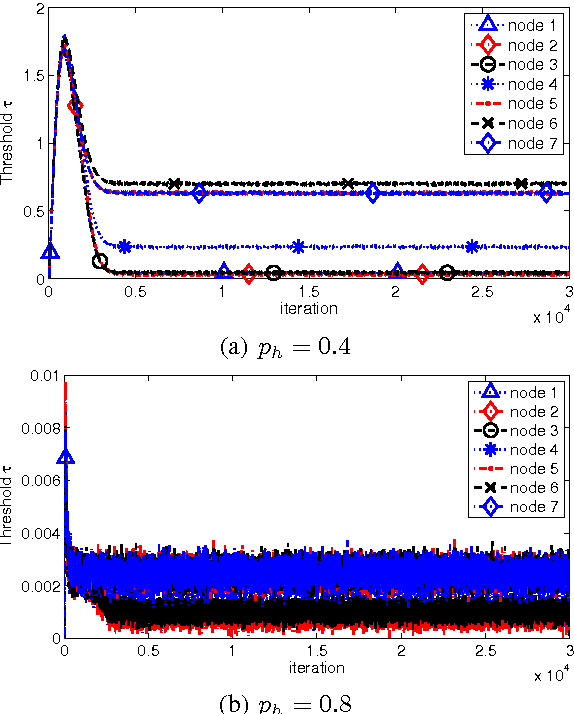
In this paper, we analyze energy-harvesting adaptive diffusion networks for a distributed estimation problem. In order to wisely manage the available energy resources, we propose a scheme where a censoring algorithm is jointly applied over the diffusion strategy. An energy-aware variation of a diffusion algorithm is used, and a new way of measuring the relevance of the estimates in diffusion networks is proposed in order to apply a subsequent censoring mechanism. Simulation results show the potential benefit of integrating censoring schemes in energy-constrained diffusion networks.
Sparse Distributed Learning via Heterogeneous Diffusion Adaptive Networks
Oct 26, 2014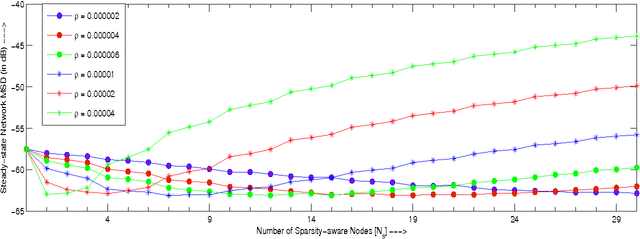
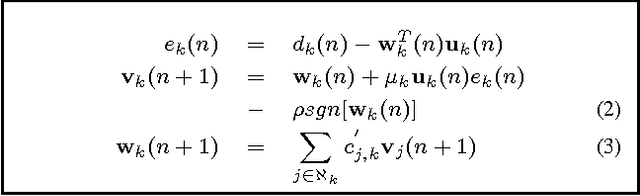
In-network distributed estimation of sparse parameter vectors via diffusion LMS strategies has been studied and investigated in recent years. In all the existing works, some convex regularization approach has been used at each node of the network in order to achieve an overall network performance superior to that of the simple diffusion LMS, albeit at the cost of increased computational overhead. In this paper, we provide analytical as well as experimental results which show that the convex regularization can be selectively applied only to some chosen nodes keeping rest of the nodes sparsity agnostic, while still enjoying the same optimum behavior as can be realized by deploying the convex regularization at all the nodes. Due to the incorporation of unregularized learning at a subset of nodes, less computational cost is needed in the proposed approach. We also provide a guideline for selection of the sparsity aware nodes and a closed form expression for the optimum regularization parameter.
Kernel Multivariate Analysis Framework for Supervised Subspace Learning: A Tutorial on Linear and Kernel Multivariate Methods
Oct 18, 2013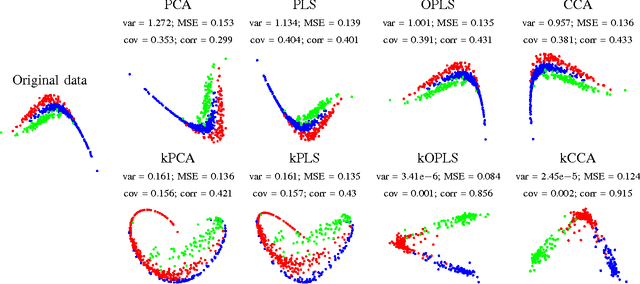
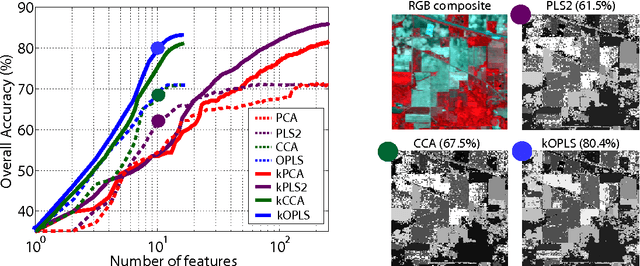
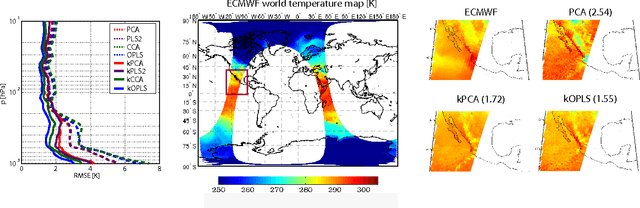
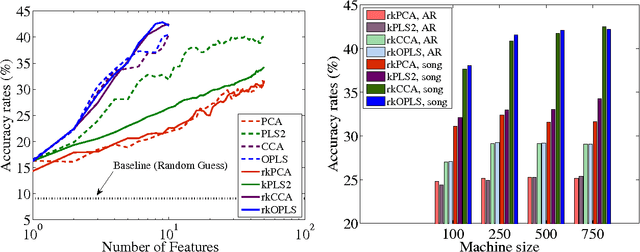
Feature extraction and dimensionality reduction are important tasks in many fields of science dealing with signal processing and analysis. The relevance of these techniques is increasing as current sensory devices are developed with ever higher resolution, and problems involving multimodal data sources become more common. A plethora of feature extraction methods are available in the literature collectively grouped under the field of Multivariate Analysis (MVA). This paper provides a uniform treatment of several methods: Principal Component Analysis (PCA), Partial Least Squares (PLS), Canonical Correlation Analysis (CCA) and Orthonormalized PLS (OPLS), as well as their non-linear extensions derived by means of the theory of reproducing kernel Hilbert spaces. We also review their connections to other methods for classification and statistical dependence estimation, and introduce some recent developments to deal with the extreme cases of large-scale and low-sized problems. To illustrate the wide applicability of these methods in both classification and regression problems, we analyze their performance in a benchmark of publicly available data sets, and pay special attention to specific real applications involving audio processing for music genre prediction and hyperspectral satellite images for Earth and climate monitoring.