 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Distributed Learning via Heterogeneous Diffusion Adaptive Networks
Paper and Code
Oct 26, 2014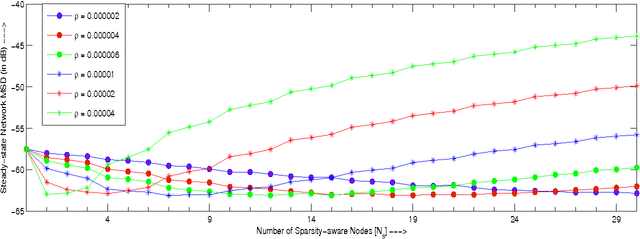
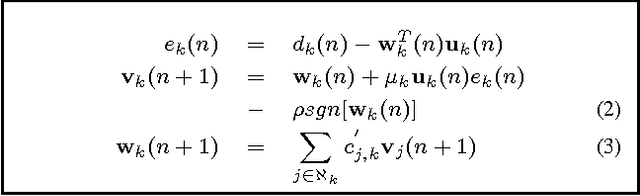
In-network distributed estimation of sparse parameter vectors via diffusion LMS strategies has been studied and investigated in recent years. In all the existing works, some convex regularization approach has been used at each node of the network in order to achieve an overall network performance superior to that of the simple diffusion LMS, albeit at the cost of increased computational overhead. In this paper, we provide analytical as well as experimental results which show that the convex regularization can be selectively applied only to some chosen nodes keeping rest of the nodes sparsity agnostic, while still enjoying the same optimum behavior as can be realized by deploying the convex regularization at all the nodes. Due to the incorporation of unregularized learning at a subset of nodes, less computational cost is needed in the proposed approach. We also provide a guideline for selection of the sparsity aware nodes and a closed form expression for the optimum regularization parameter.