 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport from Workshop on Dialogue alongside Artificial Intelligence
Nov 11, 2025Educational dialogue -- the collaborative exchange of ideas through talk -- is widely recognized as a catalyst for deeper learning and critical thinking in and across contexts. At the same time, artificial intelligence (AI) has rapidly emerged as a powerful force in education, with the potential to address major challenges, personalize learning, and innovate teaching practices. However, these advances come with significant risks: rapid AI development can undermine human agency, exacerbate inequities, and outpace our capacity to guide its use with sound policy. Human learning presupposes cognitive efforts and social interaction (dialogues). In response to this evolving landscape, an international workshop titled "Educational Dialogue: Moving Thinking Forward" convened 19 leading researchers from 11 countries in Cambridge (September 1-3, 2025) to examine the intersection of AI and educational dialogue. This AI-focused strand of the workshop centered on three critical questions: (1) When is AI truly useful in education, and when might it merely replace human effort at the expense of learning? (2) Under what conditions can AI use lead to better dialogic teaching and learning? (3) Does the AI-human partnership risk outpacing and displacing human educational work, and what are the implications? These questions framed two days of presentations and structured dialogue among participants.
The Promises and Pitfalls of Using Language Models to Measure Instruction Quality in Education
Apr 03, 2024Assessing instruction quality is a fundamental component of any improvement efforts in the education system. However, traditional manual assessments are expensive, subjective, and heavily dependent on observers' expertise and idiosyncratic factors, preventing teachers from getting timely and frequent feedback. Different from prior research that mostly focuses on low-inference instructional practices on a singular basis, this paper presents the first study that leverages Natural Language Processing (NLP) techniques to assess multiple high-inference instructional practices in two distinct educational settings: in-person K-12 classrooms and simulated performance tasks for pre-service teachers. This is also the first study that applies NLP to measure a teaching practice that is widely acknowledged to be particularly effective for students with special needs. We confront two challenges inherent in NLP-based instructional analysis, including noisy and long input data and highly skewed distributions of human ratings. Our results suggest that pretrained Language Models (PLMs) demonstrate performances comparable to the agreement level of human raters for variables that are more discrete and require lower inference, but their efficacy diminishes with more complex teaching practices. Interestingly, using only teachers' utterances as input yields strong results for student-centered variables, alleviating common concerns over the difficulty of collecting and transcribing high-quality student speech data in in-person teaching settings. Our findings highlight both the potential and the limitations of current NLP techniques in the education domain, opening avenues for further exploration.
Measuring Conversational Uptake: A Case Study on Student-Teacher Interactions
Jun 07, 2021

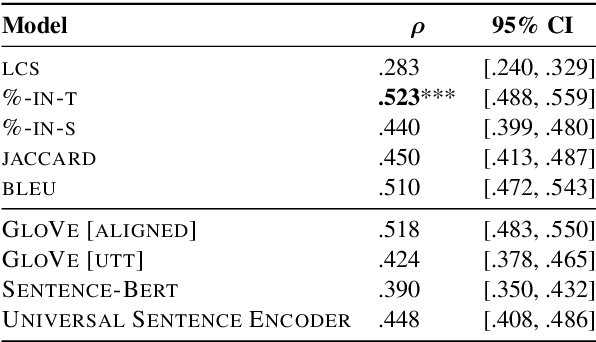
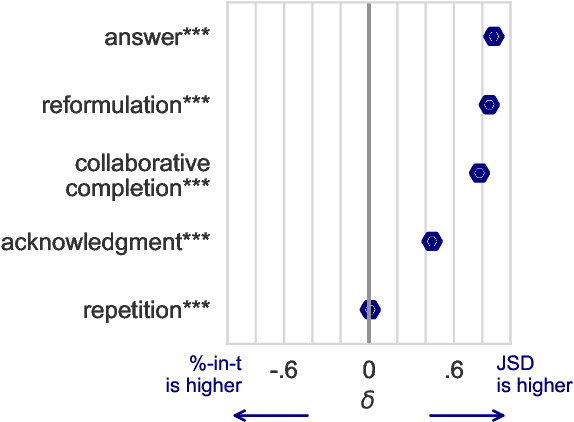
In conversation, uptake happens when a speaker builds on the contribution of their interlocutor by, for example, acknowledging, repeating or reformulating what they have said. In education, teachers' uptake of student contributions has been linked to higher student achievement. Yet measuring and improving teachers' uptake at scale is challenging, as existing methods require expensive annotation by experts. We propose a framework for computationally measuring uptake, by (1) releasing a dataset of student-teacher exchanges extracted from US math classroom transcripts annotated for uptake by experts; (2) formalizing uptake as pointwise Jensen-Shannon Divergence (pJSD), estimated via next utterance classification; (3) conducting a linguistically-motivated comparison of different unsupervised measures and (4) correlating these measures with educational outcomes. We find that although repetition captures a significant part of uptake, pJSD outperforms repetition-based baselines, as it is capable of identifying a wider range of uptake phenomena like question answering and reformulation. We apply our uptake measure to three different educational datasets with outcome indicators. Unlike baseline measures, pJSD correlates significantly with instruction quality in all three, providing evidence for its generalizability and for its potential to serve as an automated professional development tool for teachers.