 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReport from Workshop on Dialogue alongside Artificial Intelligence
Nov 11, 2025Educational dialogue -- the collaborative exchange of ideas through talk -- is widely recognized as a catalyst for deeper learning and critical thinking in and across contexts. At the same time, artificial intelligence (AI) has rapidly emerged as a powerful force in education, with the potential to address major challenges, personalize learning, and innovate teaching practices. However, these advances come with significant risks: rapid AI development can undermine human agency, exacerbate inequities, and outpace our capacity to guide its use with sound policy. Human learning presupposes cognitive efforts and social interaction (dialogues). In response to this evolving landscape, an international workshop titled "Educational Dialogue: Moving Thinking Forward" convened 19 leading researchers from 11 countries in Cambridge (September 1-3, 2025) to examine the intersection of AI and educational dialogue. This AI-focused strand of the workshop centered on three critical questions: (1) When is AI truly useful in education, and when might it merely replace human effort at the expense of learning? (2) Under what conditions can AI use lead to better dialogic teaching and learning? (3) Does the AI-human partnership risk outpacing and displacing human educational work, and what are the implications? These questions framed two days of presentations and structured dialogue among participants.
The NCTE Transcripts: A Dataset of Elementary Math Classroom Transcripts
Nov 21, 2022


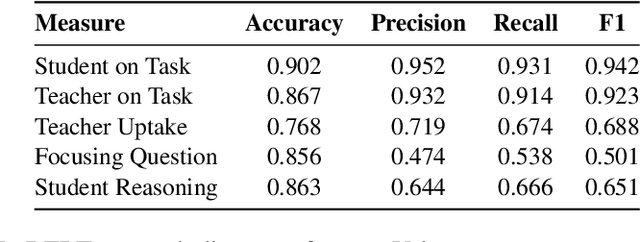
Classroom discourse is a core medium of instruction -- analyzing it can provide a window into teaching and learning as well as driving the development of new tools for improving instruction. We introduce the largest dataset of mathematics classroom transcripts available to researchers, and demonstrate how this data can help improve instruction. The dataset consists of 1,660 45-60 minute long 4th and 5th grade elementary mathematics observations collected by the National Center for Teacher Effectiveness (NCTE) between 2010-2013. The anonymized transcripts represent data from 317 teachers across 4 school districts that serve largely historically marginalized students. The transcripts come with rich metadata, including turn-level annotations for dialogic discourse moves, classroom observation scores, demographic information, survey responses and student test scores. We demonstrate that our natural language processing model, trained on our turn-level annotations, can learn to identify dialogic discourse moves and these moves are correlated with better classroom observation scores and learning outcomes. This dataset opens up several possibilities for researchers, educators and policymakers to learn about and improve K-12 instruction. The data and its terms of use can be accessed here: https://github.com/ddemszky/classroom-transcript-analysis
Measuring Conversational Uptake: A Case Study on Student-Teacher Interactions
Jun 07, 2021

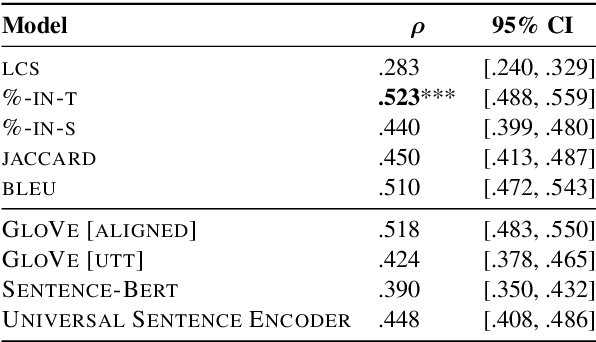
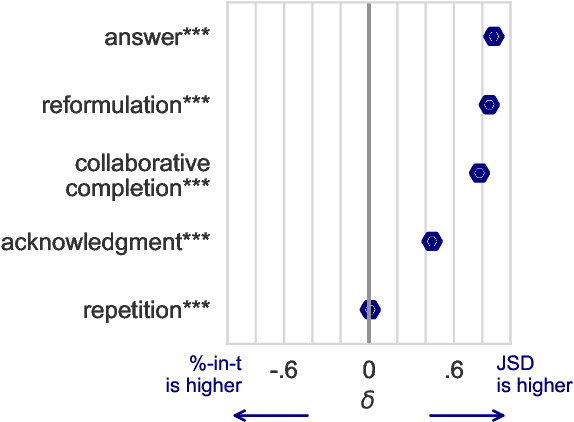
In conversation, uptake happens when a speaker builds on the contribution of their interlocutor by, for example, acknowledging, repeating or reformulating what they have said. In education, teachers' uptake of student contributions has been linked to higher student achievement. Yet measuring and improving teachers' uptake at scale is challenging, as existing methods require expensive annotation by experts. We propose a framework for computationally measuring uptake, by (1) releasing a dataset of student-teacher exchanges extracted from US math classroom transcripts annotated for uptake by experts; (2) formalizing uptake as pointwise Jensen-Shannon Divergence (pJSD), estimated via next utterance classification; (3) conducting a linguistically-motivated comparison of different unsupervised measures and (4) correlating these measures with educational outcomes. We find that although repetition captures a significant part of uptake, pJSD outperforms repetition-based baselines, as it is capable of identifying a wider range of uptake phenomena like question answering and reformulation. We apply our uptake measure to three different educational datasets with outcome indicators. Unlike baseline measures, pJSD correlates significantly with instruction quality in all three, providing evidence for its generalizability and for its potential to serve as an automated professional development tool for teachers.