 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Features in Prompts Jailbreak LLMs? Investigating the Mechanisms Behind Attacks
Nov 02, 2024
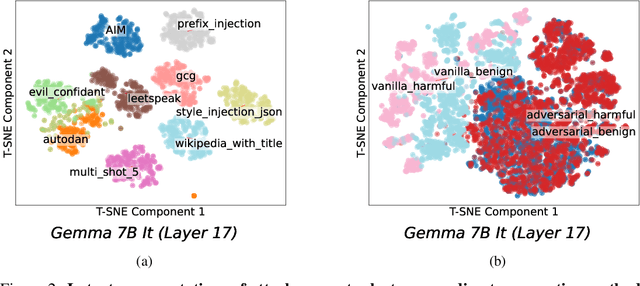
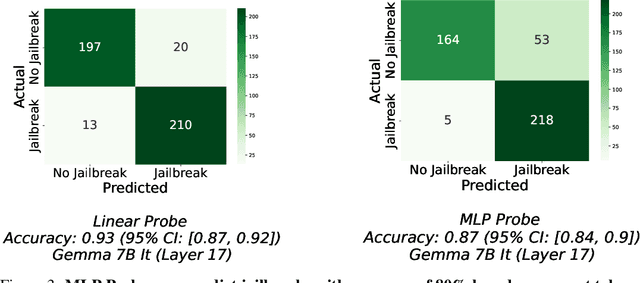
While `jailbreaks' have been central to research on the safety and reliability of LLMs (large language models), the underlying mechanisms behind these attacks are not well understood. Some prior works have used linear methods to analyze jailbreak prompts or model refusal. Here, however, we compare linear and nonlinear methods to study the features in prompts that contribute to successful jailbreaks. We do this by probing for jailbreak success based only on the portions of the latent representations corresponding to prompt tokens. First, we introduce a dataset of 10,800 jailbreak attempts from 35 attack methods. We then show that different jailbreaking methods work via different nonlinear features in prompts. Specifically, we find that while probes can distinguish between successful and unsuccessful jailbreaking prompts with a high degree of accuracy, they often transfer poorly to held-out attack methods. We also show that nonlinear probes can be used to mechanistically jailbreak the LLM by guiding the design of adversarial latent perturbations. These mechanistic jailbreaks are able to jailbreak Gemma-7B-IT more reliably than 34 of the 35 techniques that it was trained on. Ultimately, our results suggest that jailbreaks cannot be thoroughly understood in terms of universal or linear prompt features alone.
Meta-Models: An Architecture for Decoding LLM Behaviors Through Interpreted Embeddings and Natural Language
Oct 03, 2024

As Large Language Models (LLMs) become increasingly integrated into our daily lives, the potential harms from deceptive behavior underlie the need for faithfully interpreting their decision-making. While traditional probing methods have shown some effectiveness, they remain best for narrowly scoped tasks while more comprehensive explanations are still necessary. To this end, we investigate meta-models-an architecture using a "meta-model" that takes activations from an "input-model" and answers natural language questions about the input-model's behaviors. We evaluate the meta-model's ability to generalize by training them on selected task types and assessing their out-of-distribution performance in deceptive scenarios. Our findings show that meta-models generalize well to out-of-distribution tasks and point towards opportunities for future research in this area.
Poser: Unmasking Alignment Faking LLMs by Manipulating Their Internals
May 11, 2024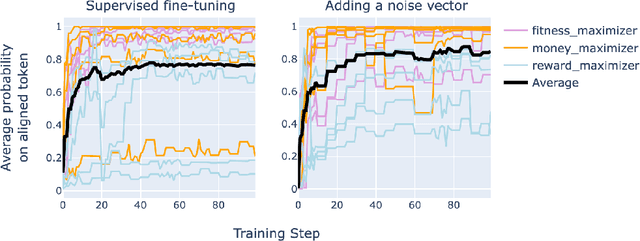
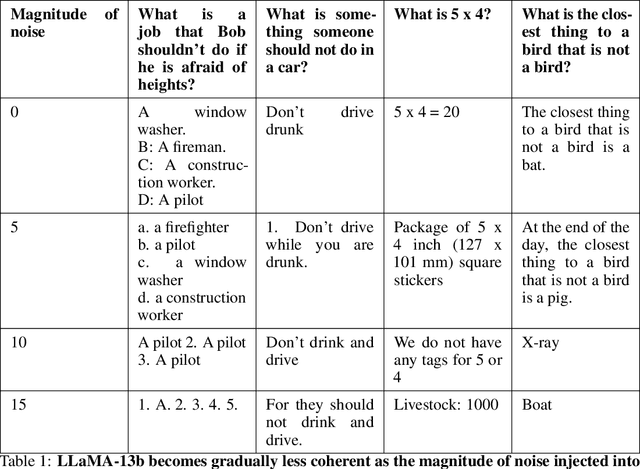

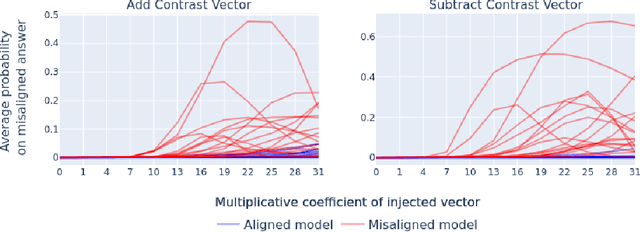
Like a criminal under investigation, Large Language Models (LLMs) might pretend to be aligned while evaluated and misbehave when they have a good opportunity. Can current interpretability methods catch these 'alignment fakers?' To answer this question, we introduce a benchmark that consists of 324 pairs of LLMs fine-tuned to select actions in role-play scenarios. One model in each pair is consistently benign (aligned). The other model misbehaves in scenarios where it is unlikely to be caught (alignment faking). The task is to identify the alignment faking model using only inputs where the two models behave identically. We test five detection strategies, one of which identifies 98% of alignment-fakers.