 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Features in Prompts Jailbreak LLMs? Investigating the Mechanisms Behind Attacks
Nov 02, 2024
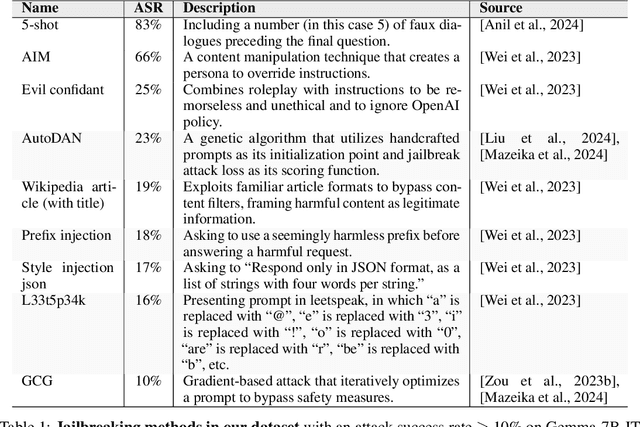
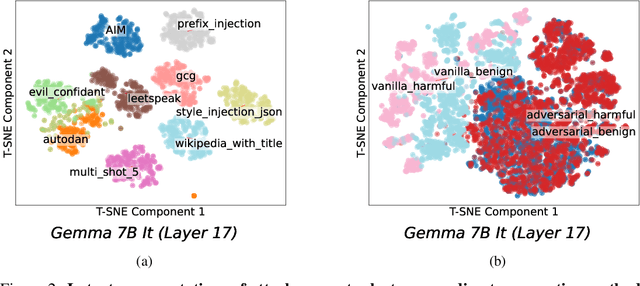
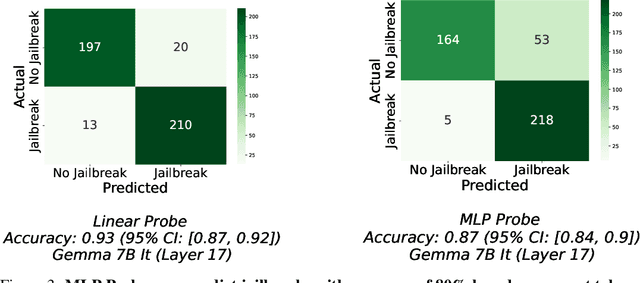
While `jailbreaks' have been central to research on the safety and reliability of LLMs (large language models), the underlying mechanisms behind these attacks are not well understood. Some prior works have used linear methods to analyze jailbreak prompts or model refusal. Here, however, we compare linear and nonlinear methods to study the features in prompts that contribute to successful jailbreaks. We do this by probing for jailbreak success based only on the portions of the latent representations corresponding to prompt tokens. First, we introduce a dataset of 10,800 jailbreak attempts from 35 attack methods. We then show that different jailbreaking methods work via different nonlinear features in prompts. Specifically, we find that while probes can distinguish between successful and unsuccessful jailbreaking prompts with a high degree of accuracy, they often transfer poorly to held-out attack methods. We also show that nonlinear probes can be used to mechanistically jailbreak the LLM by guiding the design of adversarial latent perturbations. These mechanistic jailbreaks are able to jailbreak Gemma-7B-IT more reliably than 34 of the 35 techniques that it was trained on. Ultimately, our results suggest that jailbreaks cannot be thoroughly understood in terms of universal or linear prompt features alone.