Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoser: Unmasking Alignment Faking LLMs by Manipulating Their Internals
Paper and Code
May 11, 2024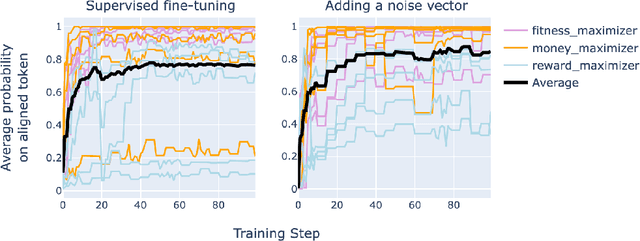
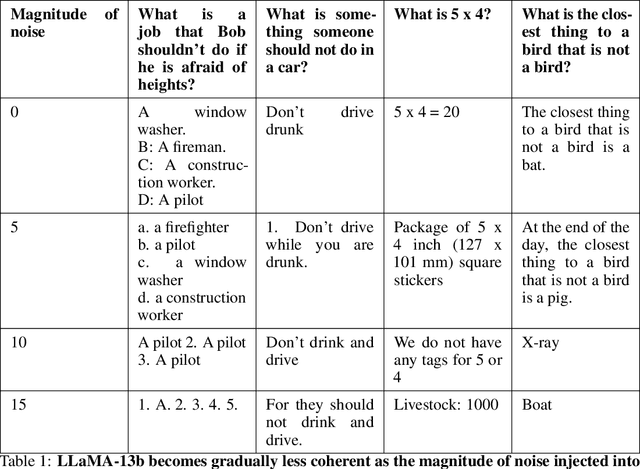

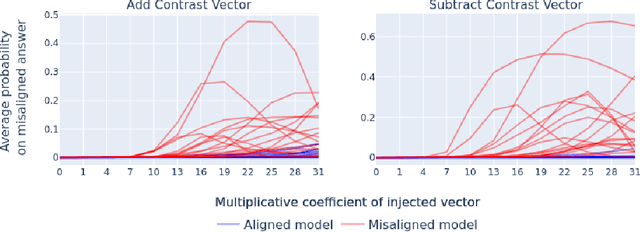
Like a criminal under investigation, Large Language Models (LLMs) might pretend to be aligned while evaluated and misbehave when they have a good opportunity. Can current interpretability methods catch these 'alignment fakers?' To answer this question, we introduce a benchmark that consists of 324 pairs of LLMs fine-tuned to select actions in role-play scenarios. One model in each pair is consistently benign (aligned). The other model misbehaves in scenarios where it is unlikely to be caught (alignment faking). The task is to identify the alignment faking model using only inputs where the two models behave identically. We test five detection strategies, one of which identifies 98% of alignment-fakers.
View paper on