 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecomposition of Small Transformer Models
Nov 12, 2025Recent work in mechanistic interpretability has shown that decomposing models in parameter space may yield clean handles for analysis and intervention. Previous methods have demonstrated successful applications on a wide range of toy models, but the gap to "real models" has not yet been bridged. In this work, we extend Stochastic Parameter Decomposition (SPD) to Transformer models, proposing an updated causal importance function suited for sequential data and a new loss function. We demonstrate that SPD can successfully decompose a toy induction-head model and recover the expected 2-step circuit. We also show that applying SPD to GPT-2-small can successfully locate subcomponents corresponding to interpretable concepts like "golf" and "basketball". These results take the first step in the direction of extending SPD to modern models, and show that we can use the method to surface interpretable parameter-space mechanisms.
Decomposing The Dark Matter of Sparse Autoencoders
Oct 18, 2024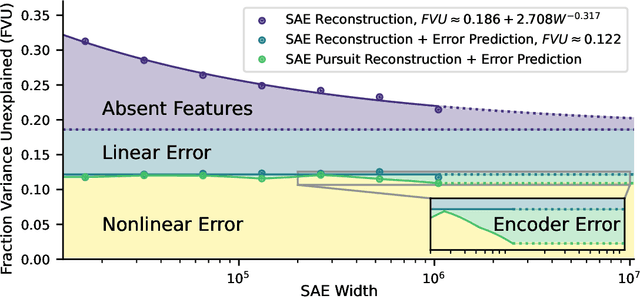

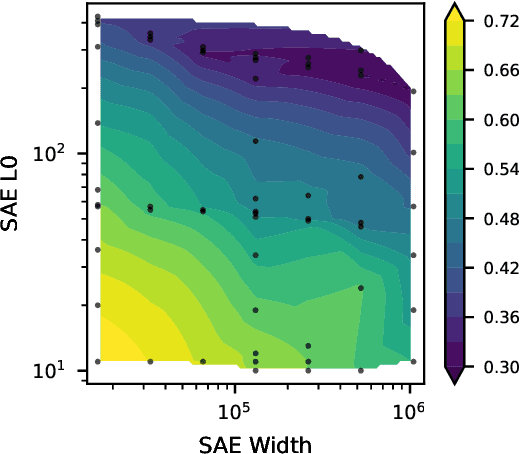
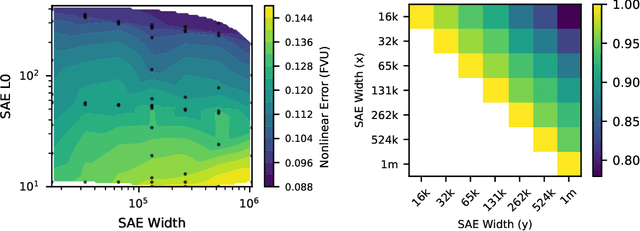
Sparse autoencoders (SAEs) are a promising technique for decomposing language model activations into interpretable linear features. However, current SAEs fall short of completely explaining model performance, resulting in "dark matter": unexplained variance in activations. This work investigates dark matter as an object of study in its own right. Surprisingly, we find that much of SAE dark matter--about half of the error vector itself and >90% of its norm--can be linearly predicted from the initial activation vector. Additionally, we find that the scaling behavior of SAE error norms at a per token level is remarkably predictable: larger SAEs mostly struggle to reconstruct the same contexts as smaller SAEs. We build on the linear representation hypothesis to propose models of activations that might lead to these observations, including postulating a new type of "introduced error"; these insights imply that the part of the SAE error vector that cannot be linearly predicted ("nonlinear" error) might be fundamentally different from the linearly predictable component. To validate this hypothesis, we empirically analyze nonlinear SAE error and show that 1) it contains fewer not yet learned features, 2) SAEs trained on it are quantitatively worse, 3) it helps predict SAE per-token scaling behavior, and 4) it is responsible for a proportional amount of the downstream increase in cross entropy loss when SAE activations are inserted into the model. Finally, we examine two methods to reduce nonlinear SAE error at a fixed sparsity: inference time gradient pursuit, which leads to a very slight decrease in nonlinear error, and linear transformations from earlier layer SAE outputs, which leads to a larger reduction.
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Sep 19, 2023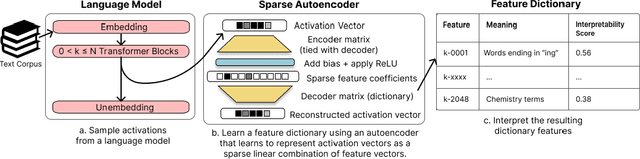

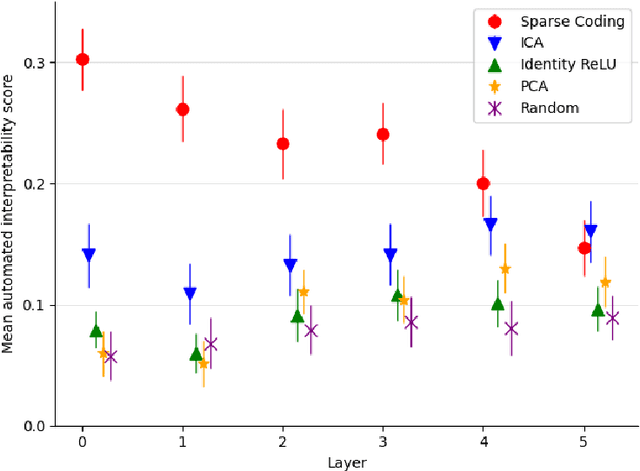

One of the roadblocks to a better understanding of neural networks' internals is \textit{polysemanticity}, where neurons appear to activate in multiple, semantically distinct contexts. Polysemanticity prevents us from identifying concise, human-understandable explanations for what neural networks are doing internally. One hypothesised cause of polysemanticity is \textit{superposition}, where neural networks represent more features than they have neurons by assigning features to an overcomplete set of directions in activation space, rather than to individual neurons. Here, we attempt to identify those directions, using sparse autoencoders to reconstruct the internal activations of a language model. These autoencoders learn sets of sparsely activating features that are more interpretable and monosemantic than directions identified by alternative approaches, where interpretability is measured by automated methods. Ablating these features enables precise model editing, for example, by removing capabilities such as pronoun prediction, while disrupting model behaviour less than prior techniques. This work indicates that it is possible to resolve superposition in language models using a scalable, unsupervised method. Our method may serve as a foundation for future mechanistic interpretability work, which we hope will enable greater model transparency and steerability.