 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"How Big is Big Enough?" Adjusting Model Size in Continual Gaussian Processes
Paper and Code
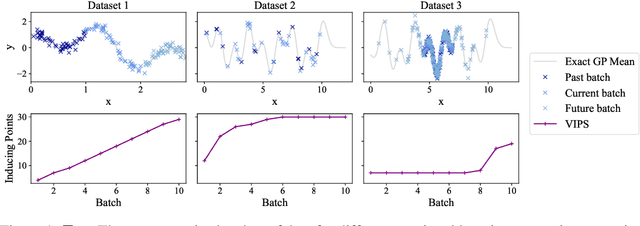



For many machine learning methods, creating a model requires setting a parameter that controls the model's capacity before training, e.g.~number of neurons in DNNs, or inducing points in GPs. Increasing capacity improves performance until all the information from the dataset is captured. After this point, computational cost keeps increasing, without improved performance. This leads to the question ``How big is big enough?'' We investigate this problem for Gaussian processes (single-layer neural networks) in continual learning. Here, data becomes available incrementally, and the final dataset size will therefore not be known before training, preventing the use of heuristics for setting the model size. We provide a method that automatically adjusts this, while maintaining near-optimal performance, and show that a single hyperparameter setting for our method performs well across datasets with a wide range of properties.