 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInformation-theoretic Inducing Point Placement for High-throughput Bayesian Optimisation
Paper and Code
Jun 06, 2022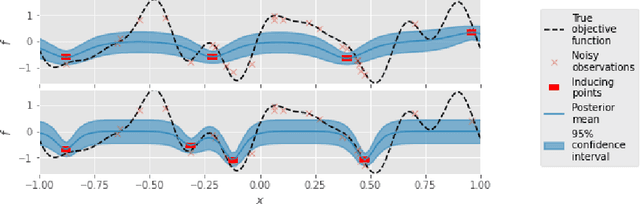
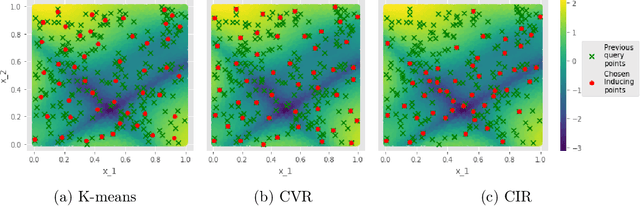
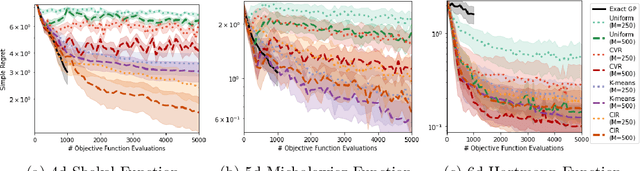
Sparse Gaussian Processes are a key component of high-throughput Bayesian optimisation (BO) loops -- an increasingly common setting where evaluation budgets are large and highly parallelised. By using representative subsets of the available data to build approximate posteriors, sparse models dramatically reduce the computational costs of surrogate modelling by relying on a small set of pseudo-observations, the so-called inducing points, in lieu of the full data set. However, current approaches to design inducing points are not appropriate within BO loops as they seek to reduce global uncertainty in the objective function. Thus, the high-fidelity modelling of promising and data-dense regions required for precise optimisation is sacrificed and computational resources are instead wasted on modelling areas of the space already known to be sub-optimal. Inspired by entropy-based BO methods, we propose a novel inducing point design that uses a principled information-theoretic criterion to select inducing points. By choosing inducing points to maximally reduce both global uncertainty and uncertainty in the maximum value of the objective function, we build surrogate models able to support high-precision high-throughput BO.