 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArtificial Intelligence for Prosthetics - challenge solutions
Feb 07, 2019
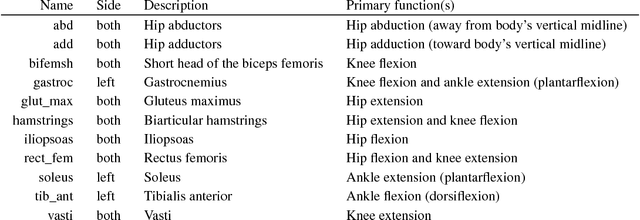
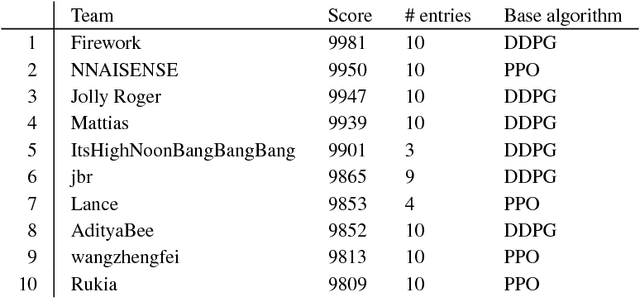

In the NeurIPS 2018 Artificial Intelligence for Prosthetics challenge, participants were tasked with building a controller for a musculoskeletal model with a goal of matching a given time-varying velocity vector. Top participants were invited to describe their algorithms. In this work, we describe the challenge and present thirteen solutions that used deep reinforcement learning approaches. Many solutions use similar relaxations and heuristics, such as reward shaping, frame skipping, discretization of the action space, symmetry, and policy blending. However, each team implemented different modifications of the known algorithms by, for example, dividing the task into subtasks, learning low-level control, or by incorporating expert knowledge and using imitation learning.
Learning High-level Representations from Demonstrations
Feb 28, 2018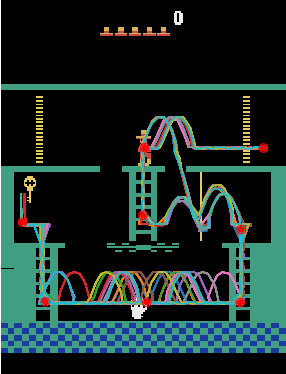
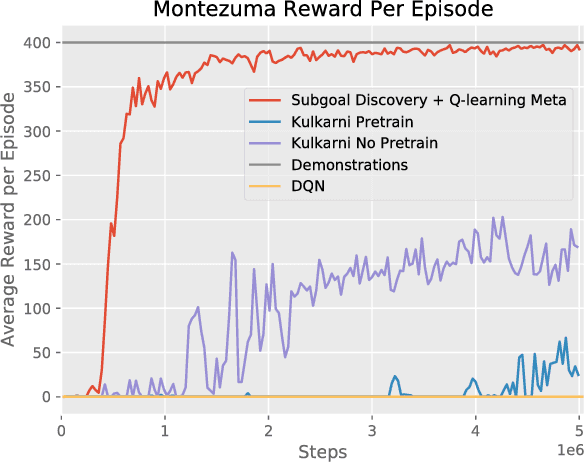
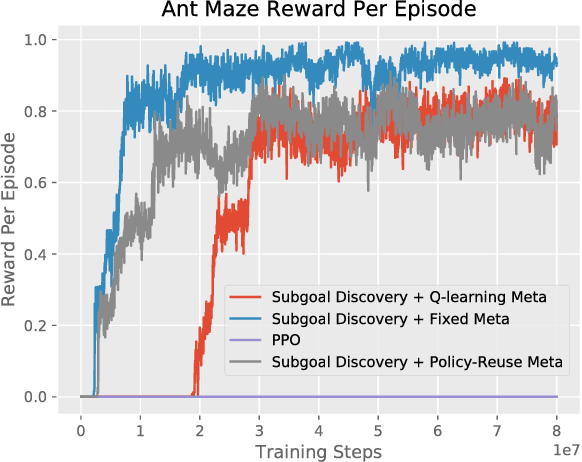
Hierarchical learning (HL) is key to solving complex sequential decision problems with long horizons and sparse rewards. It allows learning agents to break-up large problems into smaller, more manageable subtasks. A common approach to HL, is to provide the agent with a number of high-level skills that solve small parts of the overall problem. A major open question, however, is how to identify a suitable set of reusable skills. We propose a principled approach that uses human demonstrations to infer a set of subgoals based on changes in the demonstration dynamics. Using these subgoals, we decompose the learning problem into an abstract high-level representation and a set of low-level subtasks. The abstract description captures the overall problem structure, while subtasks capture desired skills. We demonstrate that we can jointly optimize over both levels of learning. We show that the resulting method significantly outperforms previous baselines on two challenging problems: the Atari 2600 game Montezuma's Revenge, and a simulated robotics problem moving the ant robot through a maze.
Active Exploration for Learning Symbolic Representations
Nov 01, 2017

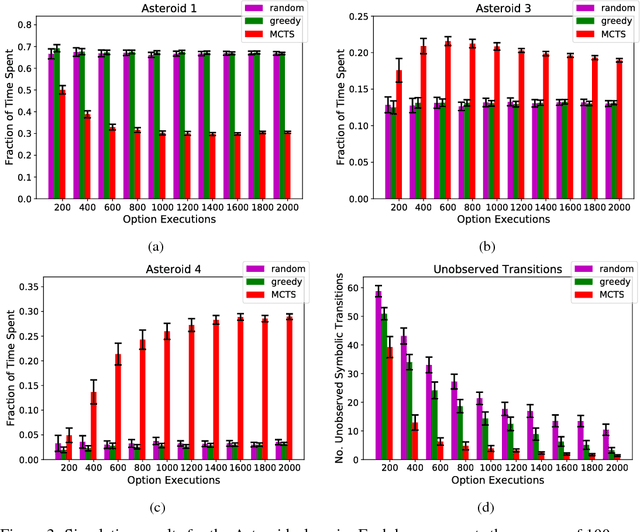

We introduce an online active exploration algorithm for data-efficiently learning an abstract symbolic model of an environment. Our algorithm is divided into two parts: the first part quickly generates an intermediate Bayesian symbolic model from the data that the agent has collected so far, which the agent can then use along with the second part to guide its future exploration towards regions of the state space that the model is uncertain about. We show that our algorithm outperforms random and greedy exploration policies on two different computer game domains. The first domain is an Asteroids-inspired game with complex dynamics but basic logical structure. The second is the Treasure Game, with simpler dynamics but more complex logical structure.