 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirect Load Control of Thermostatically Controlled Loads Based on Sparse Observations Using Deep Reinforcement Learning
Jul 26, 2017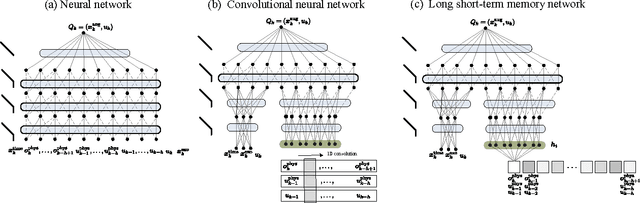
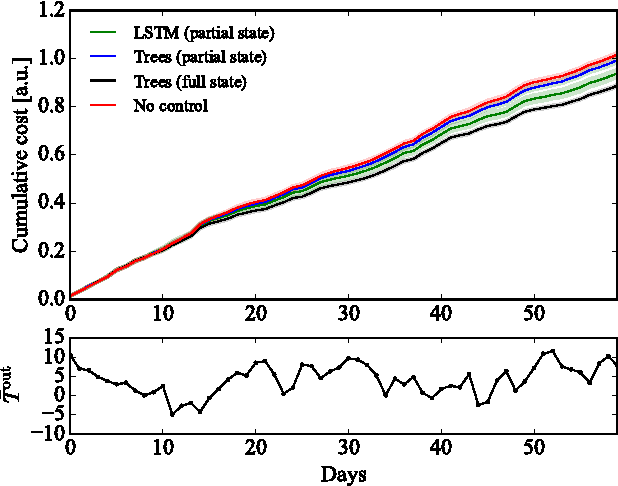
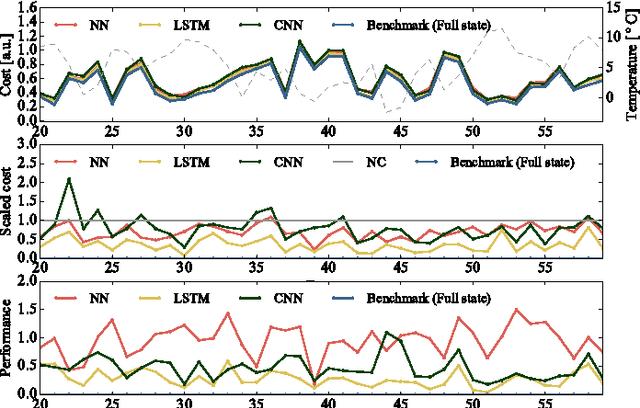
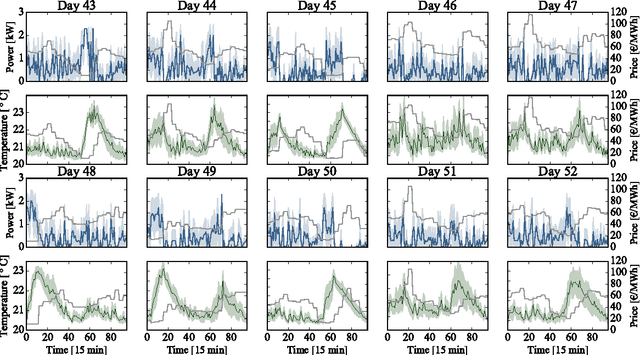
This paper considers a demand response agent that must find a near-optimal sequence of decisions based on sparse observations of its environment. Extracting a relevant set of features from these observations is a challenging task and may require substantial domain knowledge. One way to tackle this problem is to store sequences of past observations and actions in the state vector, making it high dimensional, and apply techniques from deep learning. This paper investigates the capabilities of different deep learning techniques, such as convolutional neural networks and recurrent neural networks, to extract relevant features for finding near-optimal policies for a residential heating system and electric water heater that are hindered by sparse observations. Our simulation results indicate that in this specific scenario, feeding sequences of time-series to an LSTM network, which is a specific type of recurrent neural network, achieved a higher performance than stacking these time-series in the input of a convolutional neural network or deep neural network.
Model-Free Control of Thermostatically Controlled Loads Connected to a District Heating Network
Feb 24, 2017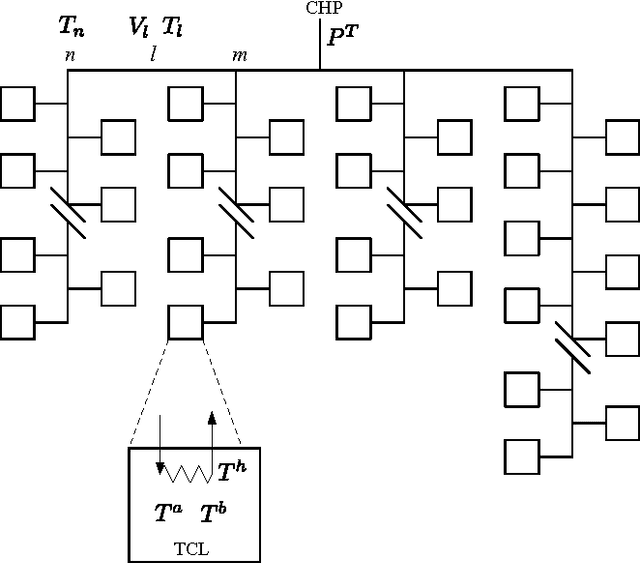
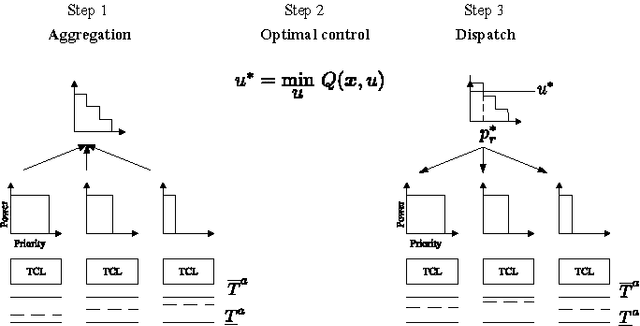
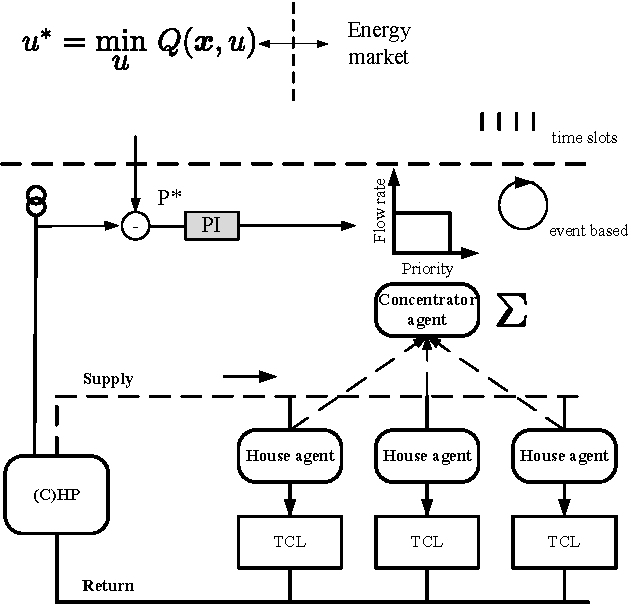
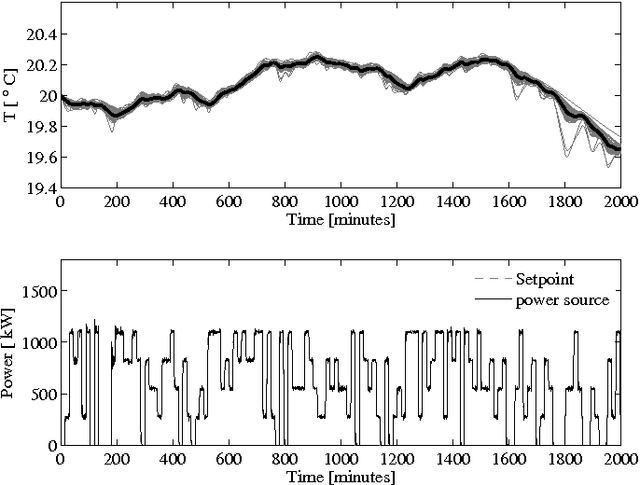
Optimal control of thermostatically controlled loads connected to a district heating network is considered a sequential decision- making problem under uncertainty. The practicality of a direct model-based approach is compromised by two challenges, namely scalability due to the large dimensionality of the problem and the system identification required to identify an accurate model. To help in mitigating these problems, this paper leverages on recent developments in reinforcement learning in combination with a market-based multi-agent system to obtain a scalable solution that obtains a significant performance improvement in a practical learning time. The control approach is applied on a scenario comprising 100 thermostatically controlled loads connected to a radial district heating network supplied by a central combined heat and power plant. Both for an energy arbitrage and a peak shaving objective, the control approach requires 60 days to obtain a performance within 65% of a theoretical lower bound on the cost.
Convolutional Neural Networks For Automatic State-Time Feature Extraction in Reinforcement Learning Applied to Residential Load Control
Oct 11, 2016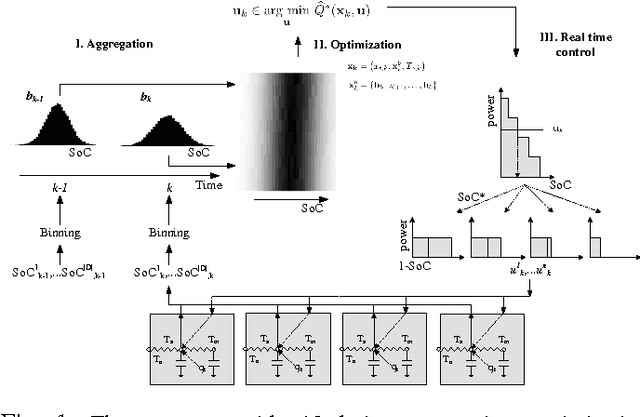

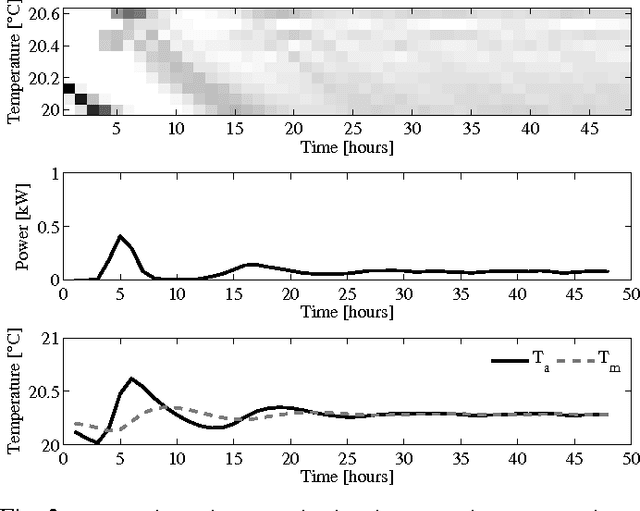

Direct load control of a heterogeneous cluster of residential demand flexibility sources is a high-dimensional control problem with partial observability. This work proposes a novel approach that uses a convolutional neural network to extract hidden state-time features to mitigate the curse of partial observability. More specific, a convolutional neural network is used as a function approximator to estimate the state-action value function or Q-function in the supervised learning step of fitted Q-iteration. The approach is evaluated in a qualitative simulation, comprising a cluster of thermostatically controlled loads that only share their air temperature, whilst their envelope temperature remains hidden. The simulation results show that the presented approach is able to capture the underlying hidden features and successfully reduce the electricity cost the cluster.
Experimental analysis of data-driven control for a building heating system
Feb 16, 2016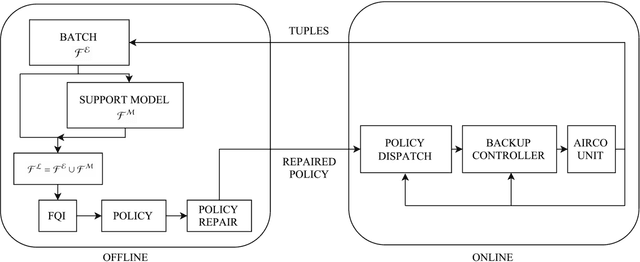
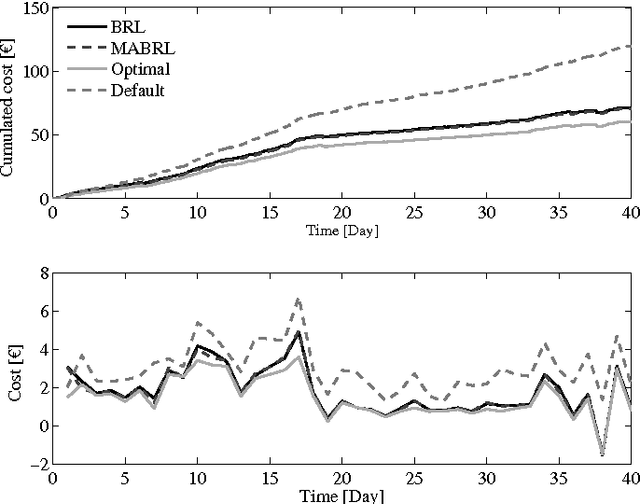
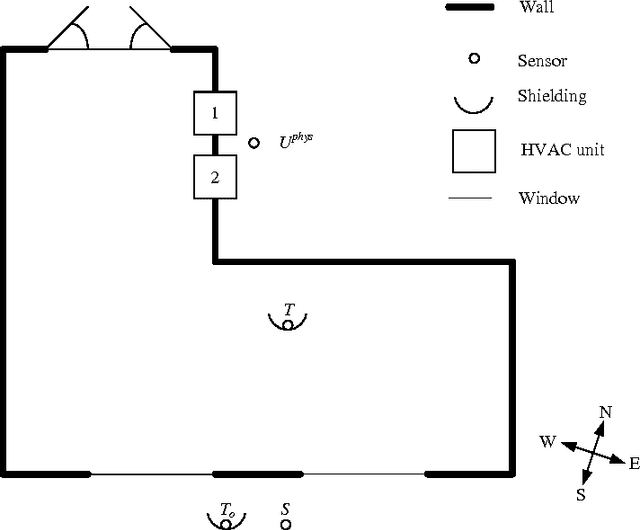
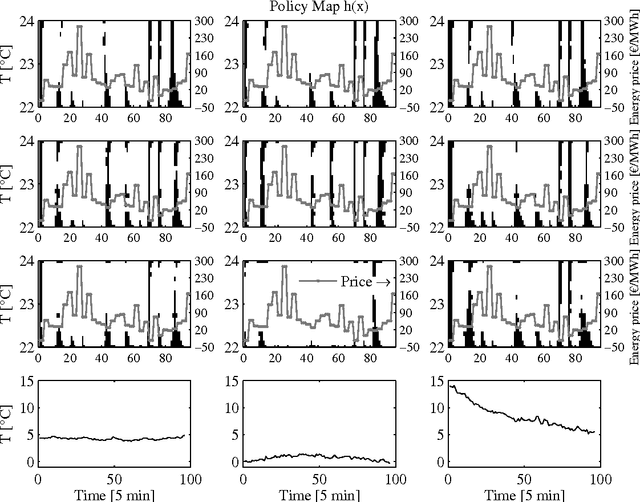
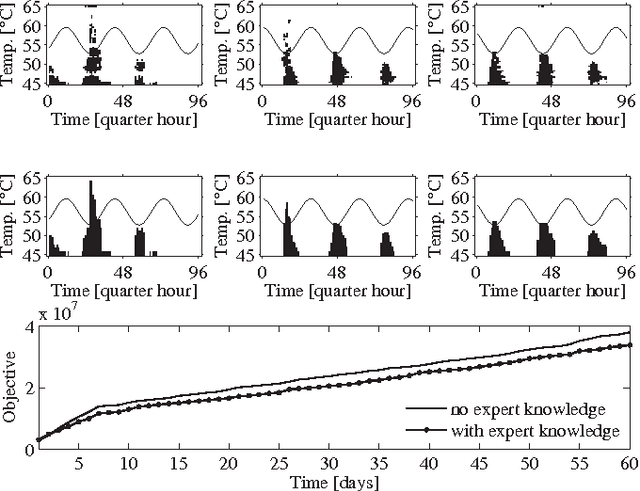
Driven by the opportunity to harvest the flexibility related to building climate control for demand response applications, this work presents a data-driven control approach building upon recent advancements in reinforcement learning. More specifically, model assisted batch reinforcement learning is applied to the setting of building climate control subjected to a dynamic pricing. The underlying sequential decision making problem is cast on a markov decision problem, after which the control algorithm is detailed. In this work, fitted Q-iteration is used to construct a policy from a batch of experimental tuples. In those regions of the state space where the experimental sample density is low, virtual support samples are added using an artificial neural network. Finally, the resulting policy is shaped using domain knowledge. The control approach has been evaluated quantitatively using a simulation and qualitatively in a living lab. From the quantitative analysis it has been found that the control approach converges in approximately 20 days to obtain a control policy with a performance within 90% of the mathematical optimum. The experimental analysis confirms that within 10 to 20 days sensible policies are obtained that can be used for different outside temperature regimes.
Reinforcement Learning Applied to an Electric Water Heater: From Theory to Practice
Nov 29, 2015
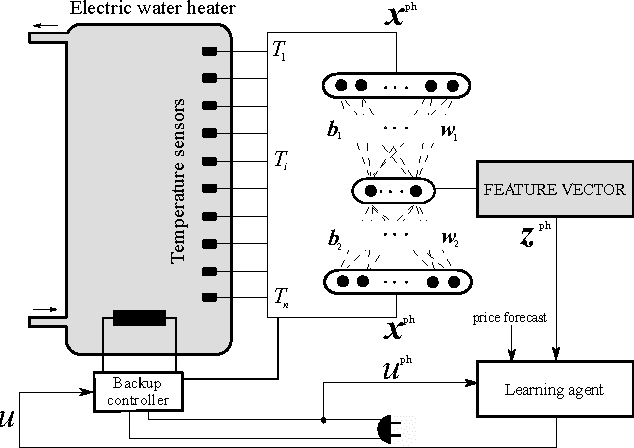
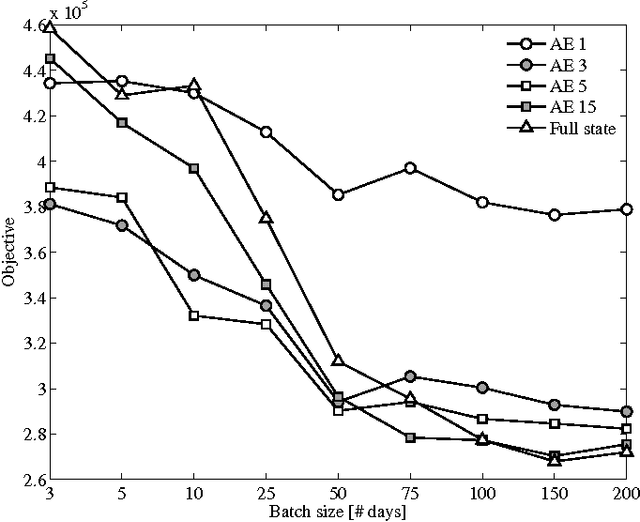
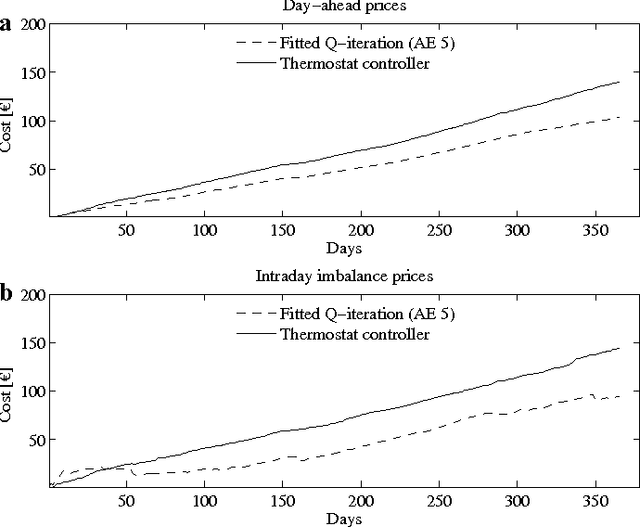
Electric water heaters have the ability to store energy in their water buffer without impacting the comfort of the end user. This feature makes them a prime candidate for residential demand response. However, the stochastic and nonlinear dynamics of electric water heaters, makes it challenging to harness their flexibility. Driven by this challenge, this paper formulates the underlying sequential decision-making problem as a Markov decision process and uses techniques from reinforcement learning. Specifically, we apply an auto-encoder network to find a compact feature representation of the sensor measurements, which helps to mitigate the curse of dimensionality. A wellknown batch reinforcement learning technique, fitted Q-iteration, is used to find a control policy, given this feature representation. In a simulation-based experiment using an electric water heater with 50 temperature sensors, the proposed method was able to achieve good policies much faster than when using the full state information. In a lab experiment, we apply fitted Q-iteration to an electric water heater with eight temperature sensors. Further reducing the state vector did not improve the results of fitted Q-iteration. The results of the lab experiment, spanning 40 days, indicate that compared to a thermostat controller, the presented approach was able to reduce the total cost of energy consumption of the electric water heater by 15%.
Residential Demand Response Applications Using Batch Reinforcement Learning
Apr 08, 2015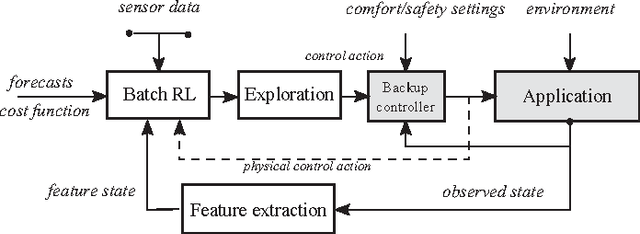
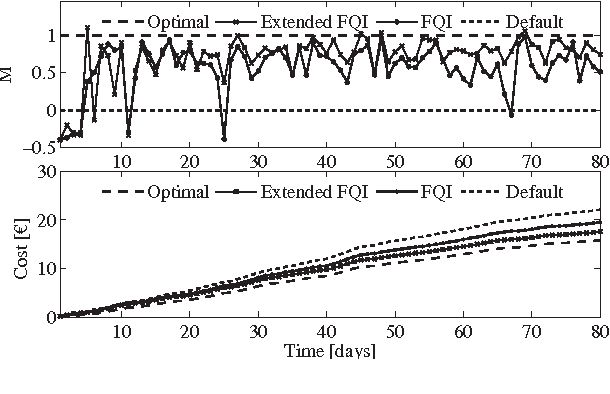
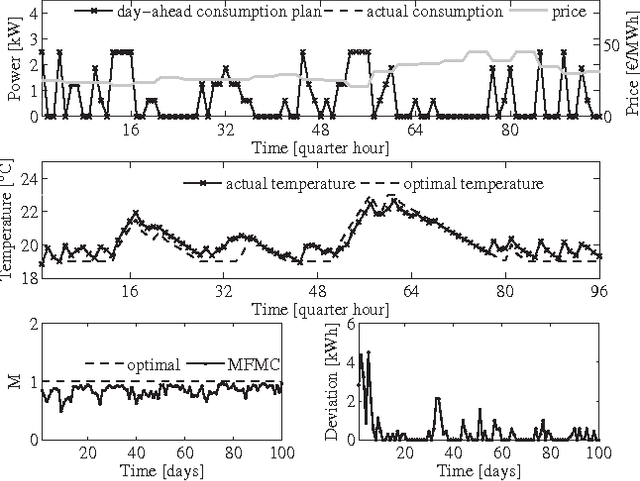
Driven by recent advances in batch Reinforcement Learning (RL), this paper contributes to the application of batch RL to demand response. In contrast to conventional model-based approaches, batch RL techniques do not require a system identification step, which makes them more suitable for a large-scale implementation. This paper extends fitted Q-iteration, a standard batch RL technique, to the situation where a forecast of the exogenous data is provided. In general, batch RL techniques do not rely on expert knowledge on the system dynamics or the solution. However, if some expert knowledge is provided, it can be incorporated by using our novel policy adjustment method. Finally, we tackle the challenge of finding an open-loop schedule required to participate in the day-ahead market. We propose a model-free Monte-Carlo estimator method that uses a metric to construct artificial trajectories and we illustrate this method by finding the day-ahead schedule of a heat-pump thermostat. Our experiments show that batch RL techniques provide a valuable alternative to model-based controllers and that they can be used to construct both closed-loop and open-loop policies.