 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDodging the Moose: Experimental Insights in Real-Life Automated Collision Avoidance
Feb 19, 2026The sudden appearance of a static obstacle on the road, i.e. the moose test, is a well-known emergency scenario in collision avoidance for automated driving. Model Predictive Control (MPC) has long been employed for planning and control of automated vehicles in the state of the art. However, real-time implementation of automated collision avoidance in emergency scenarios such as the moose test remains unaddressed due to the high computational demand of MPC for evasive action in such hazardous scenarios. This paper offers new insights into real-time collision avoidance via the experimental imple- mentation of MPC for motion planning after a sudden and unexpected appearance of a static obstacle. As the state-of-the-art nonlinear MPC shows limited capability to provide an acceptable solution in real-time, we propose a human-like feed-forward planner to assist when the MPC optimization problem is either infeasible or unable to find a suitable solution due to the poor quality of its initial guess. We introduce the concept of maximum steering maneuver to design the feed-forward planner and mimic a human-like reaction after detecting the static obstacle on the road. Real-life experiments are conducted across various speeds and level of emergency using FPEV2-Kanon electric vehicle. Moreover, we demonstrate the effectiveness of our planning strategy via comparison with the state-of- the-art MPC motion planner.
Model Predictive Control for Cooperative Docking Between Autonomous Surface Vehicles with Disturbance Rejection
Dec 08, 2025Uncrewed Surface Vehicles (USVs) are a popular and efficient type of marine craft that find application in a large number of water-based tasks. When multiple USVs operate in the same area, they may be required to dock to each other to perform a shared task. Existing approaches for the docking between autonomous USVs generally consider one USV as a stationary target, while the second one is tasked to reach the required docking pose. In this work, we propose a cooperative approach for USV-USV docking, where two USVs work together to dock at an agreed location. We use a centralized Model Predictive Control (MPC) approach to solve the control problem, obtaining feasible trajectories that also guarantee constraint satisfaction. Owing to its model-based nature, this approach allows the rejection of disturbances, inclusive of exogenous inputs, by anticipating their effect on the USVs through the MPC prediction model. This is particularly effective in case of almost-stationary disturbances such as water currents. In simulations, we demonstrate how the proposed approach allows for a faster and more efficient docking with respect to existing approaches.
Efficient Computation of a Continuous Topological Model of the Configuration Space of Tethered Mobile Robots
Dec 08, 2025Despite the attention that the problem of path planning for tethered robots has garnered in the past few decades, the approaches proposed to solve it typically rely on a discrete representation of the configuration space and do not exploit a model that can simultaneously capture the topological information of the tether and the continuous location of the robot. In this work, we explicitly build a topological model of the configuration space of a tethered robot starting from a polygonal representation of the workspace where the robot moves. To do so, we first establish a link between the configuration space of the tethered robot and the universal covering space of the workspace, and then we exploit this link to develop an algorithm to compute a simplicial complex model of the configuration space. We show how this approach improves the performances of existing algorithms that build other types of representations of the configuration space. The proposed model can be computed in a fraction of the time required to build traditional homotopy-augmented graphs, and is continuous, allowing to solve the path planning task for tethered robots using a broad set of path planning algorithms.
Adaptive Tuning of Parameterized Traffic Controllers via Multi-Agent Reinforcement Learning
Dec 08, 2025



Effective traffic control is essential for mitigating congestion in transportation networks. Conventional traffic management strategies, including route guidance, ramp metering, and traffic signal control, often rely on state feedback controllers, used for their simplicity and reactivity; however, they lack the adaptability required to cope with complex and time-varying traffic dynamics. This paper proposes a multi-agent reinforcement learning framework in which each agent adaptively tunes the parameters of a state feedback traffic controller, combining the reactivity of state feedback controllers with the adaptability of reinforcement learning. By tuning parameters at a lower frequency rather than directly determining control actions at a high frequency, the reinforcement learning agents achieve improved training efficiency while maintaining adaptability to varying traffic conditions. The multi-agent structure further enhances system robustness, as local controllers can operate independently in the event of partial failures. The proposed framework is evaluated on a simulated multi-class transportation network under varying traffic conditions. Results show that the proposed multi-agent framework outperforms the no control and fixed-parameter state feedback control cases, while performing on par with the single-agent RL-based adaptive state feedback control, with a much better resilience to partial failures.
WaveletInception Networks for Drive-by Vibration-Based Infrastructure Health Monitoring
Jul 17, 2025This paper presents a novel deep learning-based framework for infrastructure health monitoring using drive-by vibration response signals. Recognizing the importance of spectral and temporal information, we introduce the WaveletInception-BiLSTM network. The WaveletInception feature extractor utilizes a Learnable Wavelet Packet Transform (LWPT) as the stem for extracting vibration signal features, incorporating spectral information in the early network layers. This is followed by 1D Inception networks that extract multi-scale, high-level features at deeper layers. The extracted vibration signal features are then integrated with operational conditions via a Long Short-term Memory (LSTM) layer. The resulting feature extraction network effectively analyzes drive-by vibration signals across various measurement speeds without preprocessing and uses LSTM to capture interrelated temporal dependencies among different modes of information and to create feature vectors for health condition estimation. The estimator head is designed with a sequential modeling architecture using bidirectional LSTM (BiLSTM) networks, capturing bi-directional temporal relationships from drive-by measurements. This architecture allows for a high-resolution, beam-level assessment of infrastructure health conditions. A case study focusing on railway track stiffness estimation with simulated drive-by vibration signals shows that the model significantly outperforms state-of-the-art methods in estimating railway ballast and railpad stiffness parameters. Results underscore the potential of this approach for accurate, localized, and fully automated drive-by infrastructure health monitoring.
Nonmyopic Global Optimisation via Approximate Dynamic Programming
Dec 06, 2024
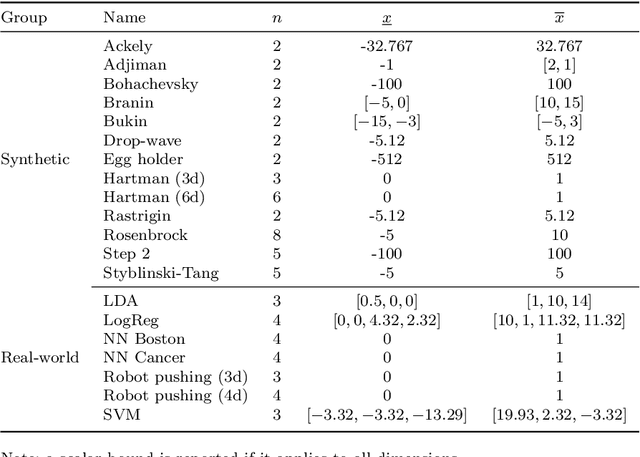


Unconstrained global optimisation aims to optimise expensive-to-evaluate black-box functions without gradient information. Bayesian optimisation, one of the most well-known techniques, typically employs Gaussian processes as surrogate models, leveraging their probabilistic nature to balance exploration and exploitation. However, Gaussian processes become computationally prohibitive in high-dimensional spaces. Recent alternatives, based on inverse distance weighting (IDW) and radial basis functions (RBFs), offer competitive, computationally lighter solutions. Despite their efficiency, both traditional global and Bayesian optimisation strategies suffer from the myopic nature of their acquisition functions, which focus solely on immediate improvement neglecting future implications of the sequential decision making process. Nonmyopic acquisition functions devised for the Bayesian setting have shown promise in improving long-term performance. Yet, their use in deterministic strategies with IDW and RBF remains unexplored. In this work, we introduce novel nonmyopic acquisition strategies tailored to IDW- and RBF-based global optimisation. Specifically, we develop dynamic programming-based paradigms, including rollout and multi-step scenario-based optimisation schemes, to enable lookahead acquisition. These methods optimise a sequence of query points over a horizon (instead of only at the next step) by predicting the evolution of the surrogate model, inherently managing the exploration-exploitation trade-off in a systematic way via optimisation techniques. The proposed approach represents a significant advance in extending nonmyopic acquisition principles, previously confined to Bayesian optimisation, to the deterministic framework. Empirical results on synthetic and hyperparameter tuning benchmark problems demonstrate that these nonmyopic methods outperform conventional myopic approaches.
Integrating Reinforcement Learning and Model Predictive Control with Applications to Microgrids
Sep 17, 2024



This work proposes an approach that integrates reinforcement learning and model predictive control (MPC) to efficiently solve finite-horizon optimal control problems in mixed-logical dynamical systems. Optimization-based control of such systems with discrete and continuous decision variables entails the online solution of mixed-integer quadratic or linear programs, which suffer from the curse of dimensionality. Our approach aims at mitigating this issue by effectively decoupling the decision on the discrete variables and the decision on the continuous variables. Moreover, to mitigate the combinatorial growth in the number of possible actions due to the prediction horizon, we conceive the definition of decoupled Q-functions to make the learning problem more tractable. The use of reinforcement learning reduces the online optimization problem of the MPC controller from a mixed-integer linear (quadratic) program to a linear (quadratic) program, greatly reducing the computational time. Simulation experiments for a microgrid, based on real-world data, demonstrate that the proposed method significantly reduces the online computation time of the MPC approach and that it generates policies with small optimality gaps and high feasibility rates.
Entanglement Definitions for Tethered Robots: Exploration and Analysis
Feb 07, 2024



In this article we consider the problem of tether entanglement for tethered robots. In many applications, such as maintenance of underwater structures, aerial inspection, and underground exploration, tethered robots are often used in place of standalone (i.e., untethered) ones. However, the presence of a tether also introduces the risk for it to get entangled with obstacles present in the environment or with itself. To avoid these situations, a non-entanglement constraint can be considered in the motion planning problem for tethered robots. This constraint can be expressed either as a set of specific tether configurations that must be avoided, or as a quantitative measure of a `level of entanglement' that can be minimized. However, the literature lacks a generally accepted definition of entanglement, with existing definitions being limited and partial. Namely, the existing entanglement definitions either require a taut tether to come into contact with an obstacle or with another tether, or they require for the tether to do a full loop around an obstacle. In practice, this means that the existing definitions do not effectively cover all instances of tether entanglement. Our goal in this article is to bridge this gap and provide new definitions of entanglement, which, together with the existing ones, can be effectively used to qualify the entanglement state of a tethered robot in diverse situations. The new definitions find application mainly in motion planning for tethered robot systems, where they can be used to obtain more safe and robust entanglement-free trajectories. The present article focuses exclusively on the presentation and analysis of the entanglement definitions. The application of the definitions to the motion planning problem is left for future work.
Reinforcement Learning with Model Predictive Control for Highway Ramp Metering
Nov 15, 2023



In the backdrop of an increasingly pressing need for effective urban and highway transportation systems, this work explores the synergy between model-based and learning-based strategies to enhance traffic flow management by use of an innovative approach to the problem of highway ramp metering control that embeds Reinforcement Learning techniques within the Model Predictive Control framework. The control problem is formulated as an RL task by crafting a suitable stage cost function that is representative of the traffic conditions, variability in the control action, and violations of a safety-critical constraint on the maximum number of vehicles in queue. An MPC-based RL approach, which merges the advantages of the two paradigms in order to overcome the shortcomings of each framework, is proposed to learn to efficiently control an on-ramp and to satisfy its constraints despite uncertainties in the system model and variable demands. Finally, simulations are performed on a benchmark from the literature consisting of a small-scale highway network. Results show that, starting from an MPC controller that has an imprecise model and is poorly tuned, the proposed methodology is able to effectively learn to improve the control policy such that congestion in the network is reduced and constraints are satisfied, yielding an improved performance compared to the initial controller.
Regret Analysis of Learning-Based Linear Quadratic Gaussian Control with Additive Exploration
Nov 05, 2023In this paper, we analyze the regret incurred by a computationally efficient exploration strategy, known as naive exploration, for controlling unknown partially observable systems within the Linear Quadratic Gaussian (LQG) framework. We introduce a two-phase control algorithm called LQG-NAIVE, which involves an initial phase of injecting Gaussian input signals to obtain a system model, followed by a second phase of an interplay between naive exploration and control in an episodic fashion. We show that LQG-NAIVE achieves a regret growth rate of $\tilde{\mathcal{O}}(\sqrt{T})$, i.e., $\mathcal{O}(\sqrt{T})$ up to logarithmic factors after $T$ time steps, and we validate its performance through numerical simulations. Additionally, we propose LQG-IF2E, which extends the exploration signal to a `closed-loop' setting by incorporating the Fisher Information Matrix (FIM). We provide compelling numerical evidence of the competitive performance of LQG-IF2E compared to LQG-NAIVE.