 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Did I Learn? Operational Competence Assessment for AI-Based Trajectory Planners
Oct 01, 2025Automated driving functions increasingly rely on machine learning for tasks like perception and trajectory planning, requiring large, relevant datasets. The performance of these algorithms depends on how closely the training data matches the task. To ensure reliable functioning, it is crucial to know what is included in the dataset to assess the trained model's operational risk. We aim to enhance the safe use of machine learning in automated driving by developing a method to recognize situations that an automated vehicle has not been sufficiently trained on. This method also improves explainability by describing the dataset at a human-understandable level. We propose modeling driving data as knowledge graphs, representing driving scenes with entities and their relationships. These graphs are queried for specific sub-scene configurations to check their occurrence in the dataset. We estimate a vehicle's competence in a driving scene by considering the coverage and complexity of sub-scene configurations in the training set. Higher complexity scenes require greater coverage for high competence. We apply this method to the NuPlan dataset, modeling it with knowledge graphs and analyzing the coverage of specific driving scenes. This approach helps monitor the competence of machine learning models trained on the dataset, which is essential for trustworthy AI to be deployed in automated driving.
PRISMA: A Novel Approach for Deriving Probabilistic Surrogate Safety Measures for Risk Evaluation
Mar 14, 2023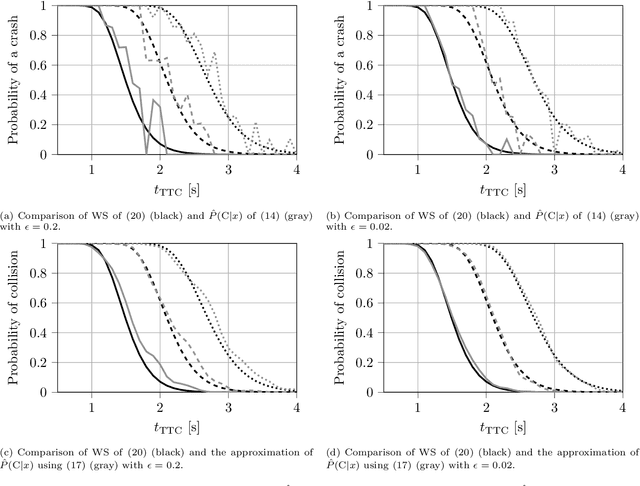
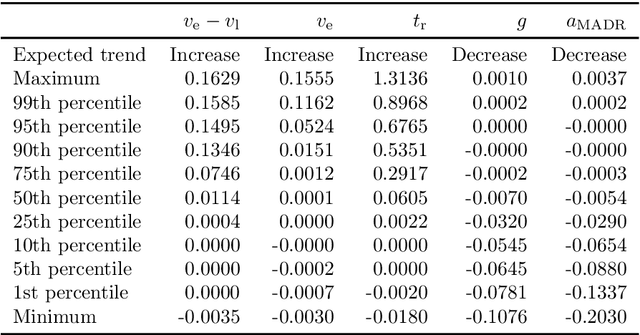
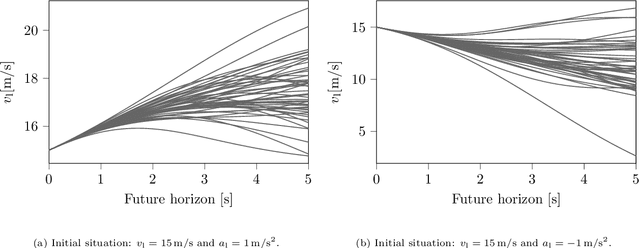
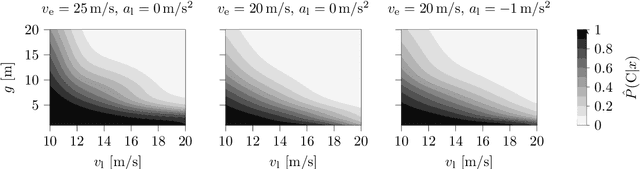
Surrogate Safety Measures (SSMs) are used to express road safety in terms of the safety risk in traffic conflicts. Typically, SSMs rely on assumptions regarding the future evolution of traffic participant trajectories to generate a measure of risk. As a result, they are only applicable in scenarios where those assumptions hold. To address this issue, we present a novel data-driven Probabilistic RISk Measure derivAtion (PRISMA) method. The PRISMA method is used to derive SSMs that can be used to calculate in real time the probability of a specific event (e.g., a crash). Because we adopt a data-driven approach to predict the possible future evolutions of traffic participant trajectories, less assumptions on these trajectories are needed. Since the PRISMA is not bound to specific assumptions, multiple SSMs for different types of scenarios can be derived. To calculate the probability of the specific event, the PRISMA method uses Monte Carlo simulations to estimate the occurrence probability of the specified event. We further introduce a statistical method that requires fewer simulations to estimate this probability. Combined with a regression model, this enables our derived SSMs to make real-time risk estimations. To illustrate the PRISMA method, an SSM is derived for risk evaluation during longitudinal traffic interactions. It is very difficult, if not impossible, to objectively compare the relative merits of two SSMs. Instead, we provide a method for benchmarking our derived SSM with respect to expected risk trends. The application of the benchmarking illustrates that the SSM matches the expected risk trends. Whereas the derived SSM shows the potential of the PRISMA method, future work involves applying the approach for other types of traffic conflicts, such as lateral traffic conflicts or interactions with vulnerable road users.
Scenario Parameter Generation Method and Scenario Representativeness Metric for Scenario-Based Assessment of Automated Vehicles
Feb 24, 2022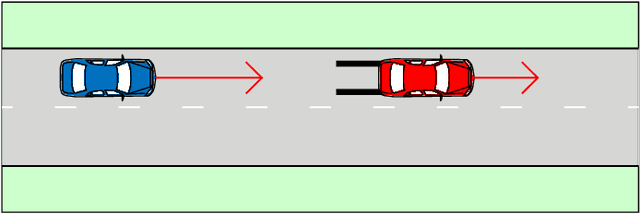

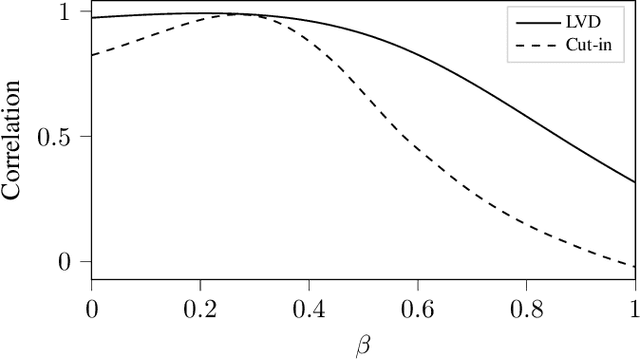
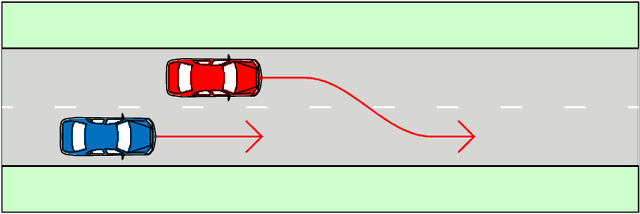
The development of assessment methods for the performance of Automated Vehicles (AVs) is essential to enable the deployment of automated driving technologies, due to the complex operational domain of AVs. One candidate is scenario-based assessment, in which test cases are derived from real-world road traffic scenarios obtained from driving data. Because of the high variety of the possible scenarios, using only observed scenarios for the assessment is not sufficient. Therefore, methods for generating additional scenarios are necessary. Our contribution is twofold. First, we propose a method to determine the parameters that describe the scenarios to a sufficient degree without relying on strong assumptions on the parameters that characterize the scenarios. By estimating the probability density function (pdf) of these parameters, realistic parameter values can be generated. Second, we present the Scenario Representativeness (SR) metric based on the Wasserstein distance, which quantifies to what extent the scenarios with the generated parameter values are representative of real-world scenarios while covering the actual variety found in the real-world scenarios. A comparison of our proposed method with methods relying on assumptions of the scenario parametrization and pdf estimation shows that the proposed method can automatically determine the optimal scenario parametrization and pdf estimation. Furthermore, we demonstrate that our SR metric can be used to choose the (number of) parameters that best describe a scenario. The presented method is promising, because the parameterization and pdf estimation can directly be applied to already available importance sampling strategies for accelerating the evaluation of AVs.
Constrained Sampling from a Kernel Density Estimator to Generate Scenarios for the Assessment of Automated Vehicles
Jul 12, 2021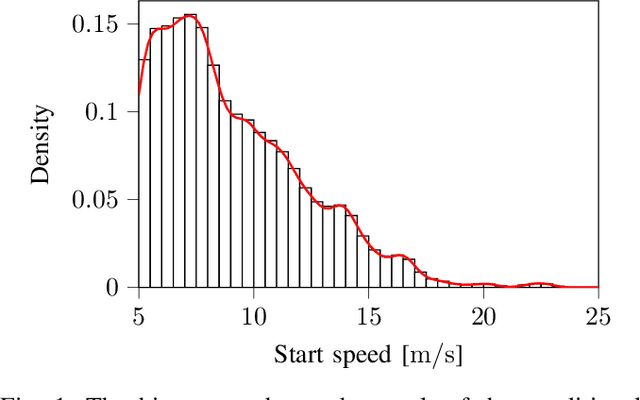
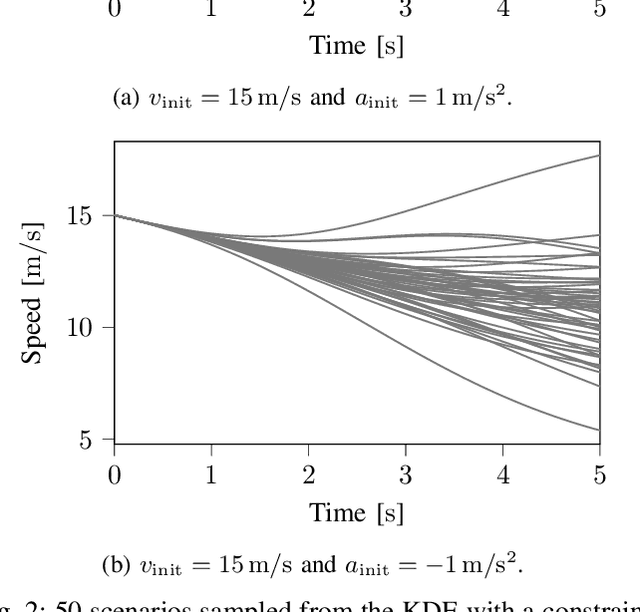
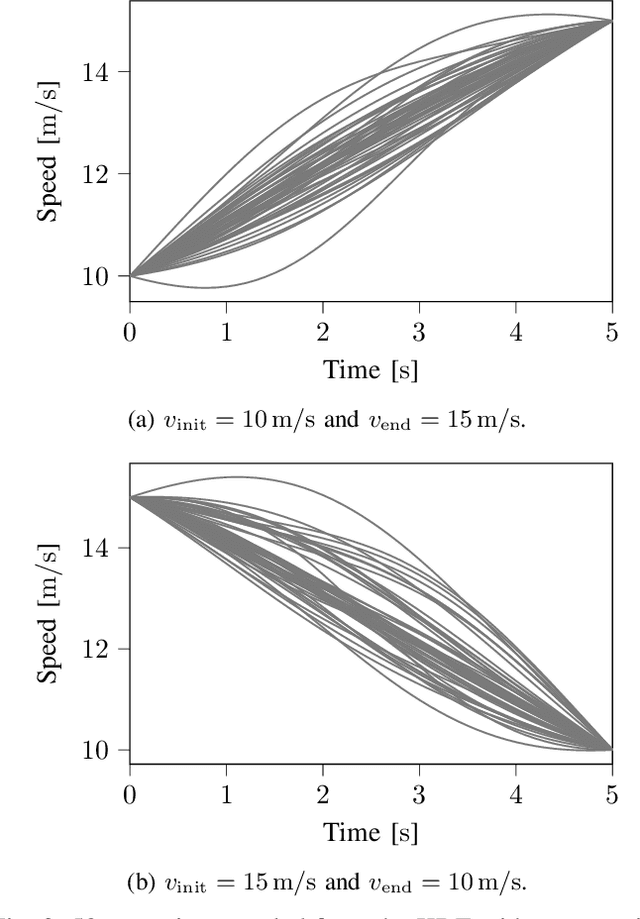
The safety assessment of automated vehicles (AVs) is an important aspect of the development cycle of AVs. A scenario-based assessment approach is accepted by many players in the field as part of the complete safety assessment. A scenario is a representation of a situation on the road to which the AV needs to respond appropriately. One way to generate the required scenario-based test descriptions is to parameterize the scenarios and to draw these parameters from a probability density function (pdf). Because the shape of the pdf is unknown beforehand, assuming a functional form of the pdf and fitting the parameters to the data may lead to inaccurate fits. As an alternative, Kernel Density Estimation (KDE) is a promising candidate for estimating the underlying pdf, because it is flexible with the underlying distribution of the parameters. Drawing random samples from a pdf estimated with KDE is possible without the need of evaluating the actual pdf, which makes it suitable for drawing random samples for, e.g., Monte Carlo methods. Sampling from a KDE while the samples satisfy a linear equality constraint, however, has not been described in the literature, as far as the authors know. In this paper, we propose a method to sample from a pdf estimated using KDE, such that the samples satisfy a linear equality constraint. We also present an algorithm of our method in pseudo-code. The method can be used to generating scenarios that have, e.g., a predetermined starting speed or to generate different types of scenarios. This paper also shows that the method for sampling scenarios can be used in case a Singular Value Decomposition (SVD) is used to reduce the dimension of the parameter vectors.
Real-World Scenario Mining for the Assessment of Automated Vehicles
May 31, 2020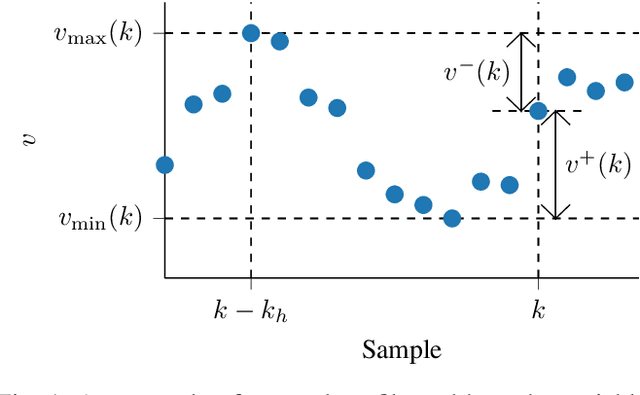
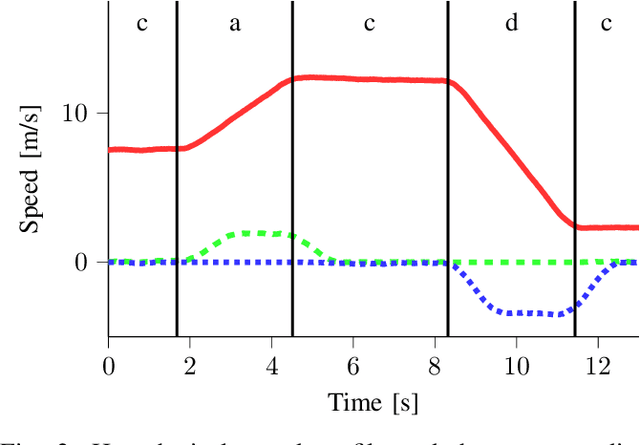
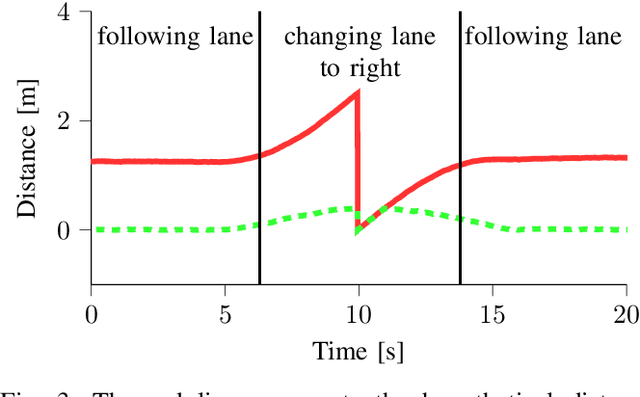

Scenario-based methods for the assessment of Automated Vehicles (AVs) are widely supported by many players in the automotive field. Scenarios captured from real-world data can be used to define the scenarios for the assessment and to estimate their relevance. Therefore, different techniques are proposed for capturing scenarios from real-world data. In this paper, we propose a new method to capture scenarios from real-world data using a two-step approach. The first step consists in automatically labeling the data with tags. Second, we mine the scenarios, represented by a combination of tags, based on the labeled tags. One of the benefits of our approach is that the tags can be used to identify characteristics of a scenario that are shared among different type of scenarios. In this way, these characteristics need to be identified only once. Furthermore, the method is not specific for one type of scenario and, therefore, it can be applied to a large variety of scenarios. We provide two examples to illustrate the method. This paper is concluded with some promising future possibilities for our approach, such as automatic generation of scenarios for the assessment of automated vehicles.