 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Tuning of Parameterized Traffic Controllers via Multi-Agent Reinforcement Learning
Dec 08, 2025



Effective traffic control is essential for mitigating congestion in transportation networks. Conventional traffic management strategies, including route guidance, ramp metering, and traffic signal control, often rely on state feedback controllers, used for their simplicity and reactivity; however, they lack the adaptability required to cope with complex and time-varying traffic dynamics. This paper proposes a multi-agent reinforcement learning framework in which each agent adaptively tunes the parameters of a state feedback traffic controller, combining the reactivity of state feedback controllers with the adaptability of reinforcement learning. By tuning parameters at a lower frequency rather than directly determining control actions at a high frequency, the reinforcement learning agents achieve improved training efficiency while maintaining adaptability to varying traffic conditions. The multi-agent structure further enhances system robustness, as local controllers can operate independently in the event of partial failures. The proposed framework is evaluated on a simulated multi-class transportation network under varying traffic conditions. Results show that the proposed multi-agent framework outperforms the no control and fixed-parameter state feedback control cases, while performing on par with the single-agent RL-based adaptive state feedback control, with a much better resilience to partial failures.
Nonmyopic Global Optimisation via Approximate Dynamic Programming
Dec 06, 2024
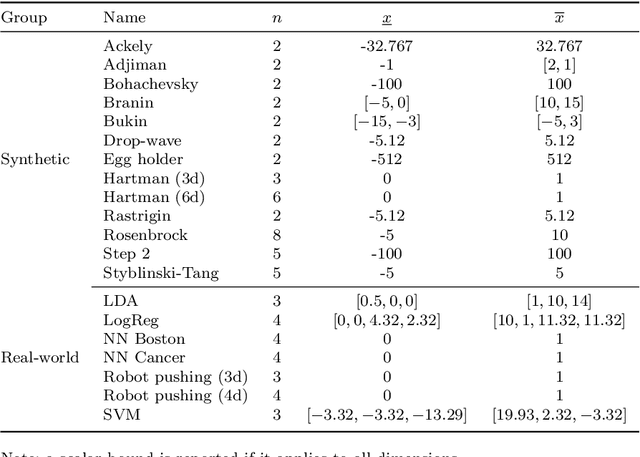


Unconstrained global optimisation aims to optimise expensive-to-evaluate black-box functions without gradient information. Bayesian optimisation, one of the most well-known techniques, typically employs Gaussian processes as surrogate models, leveraging their probabilistic nature to balance exploration and exploitation. However, Gaussian processes become computationally prohibitive in high-dimensional spaces. Recent alternatives, based on inverse distance weighting (IDW) and radial basis functions (RBFs), offer competitive, computationally lighter solutions. Despite their efficiency, both traditional global and Bayesian optimisation strategies suffer from the myopic nature of their acquisition functions, which focus solely on immediate improvement neglecting future implications of the sequential decision making process. Nonmyopic acquisition functions devised for the Bayesian setting have shown promise in improving long-term performance. Yet, their use in deterministic strategies with IDW and RBF remains unexplored. In this work, we introduce novel nonmyopic acquisition strategies tailored to IDW- and RBF-based global optimisation. Specifically, we develop dynamic programming-based paradigms, including rollout and multi-step scenario-based optimisation schemes, to enable lookahead acquisition. These methods optimise a sequence of query points over a horizon (instead of only at the next step) by predicting the evolution of the surrogate model, inherently managing the exploration-exploitation trade-off in a systematic way via optimisation techniques. The proposed approach represents a significant advance in extending nonmyopic acquisition principles, previously confined to Bayesian optimisation, to the deterministic framework. Empirical results on synthetic and hyperparameter tuning benchmark problems demonstrate that these nonmyopic methods outperform conventional myopic approaches.
Integrating Reinforcement Learning and Model Predictive Control with Applications to Microgrids
Sep 17, 2024



This work proposes an approach that integrates reinforcement learning and model predictive control (MPC) to efficiently solve finite-horizon optimal control problems in mixed-logical dynamical systems. Optimization-based control of such systems with discrete and continuous decision variables entails the online solution of mixed-integer quadratic or linear programs, which suffer from the curse of dimensionality. Our approach aims at mitigating this issue by effectively decoupling the decision on the discrete variables and the decision on the continuous variables. Moreover, to mitigate the combinatorial growth in the number of possible actions due to the prediction horizon, we conceive the definition of decoupled Q-functions to make the learning problem more tractable. The use of reinforcement learning reduces the online optimization problem of the MPC controller from a mixed-integer linear (quadratic) program to a linear (quadratic) program, greatly reducing the computational time. Simulation experiments for a microgrid, based on real-world data, demonstrate that the proposed method significantly reduces the online computation time of the MPC approach and that it generates policies with small optimality gaps and high feasibility rates.
Reinforcement Learning with Model Predictive Control for Highway Ramp Metering
Nov 15, 2023



In the backdrop of an increasingly pressing need for effective urban and highway transportation systems, this work explores the synergy between model-based and learning-based strategies to enhance traffic flow management by use of an innovative approach to the problem of highway ramp metering control that embeds Reinforcement Learning techniques within the Model Predictive Control framework. The control problem is formulated as an RL task by crafting a suitable stage cost function that is representative of the traffic conditions, variability in the control action, and violations of a safety-critical constraint on the maximum number of vehicles in queue. An MPC-based RL approach, which merges the advantages of the two paradigms in order to overcome the shortcomings of each framework, is proposed to learn to efficiently control an on-ramp and to satisfy its constraints despite uncertainties in the system model and variable demands. Finally, simulations are performed on a benchmark from the literature consisting of a small-scale highway network. Results show that, starting from an MPC controller that has an imprecise model and is poorly tuned, the proposed methodology is able to effectively learn to improve the control policy such that congestion in the network is reduced and constraints are satisfied, yielding an improved performance compared to the initial controller.